@efranzosa Thank you! This figure started as a diagram of the workflow that I made in Lucidchart (attached here). Then, Audrey Bell, a very talented science illustrator at Arcadia, worked her magic in Illustrator! https://t.co/I4dS09MArT. @thecrispress also gave critical feedback.
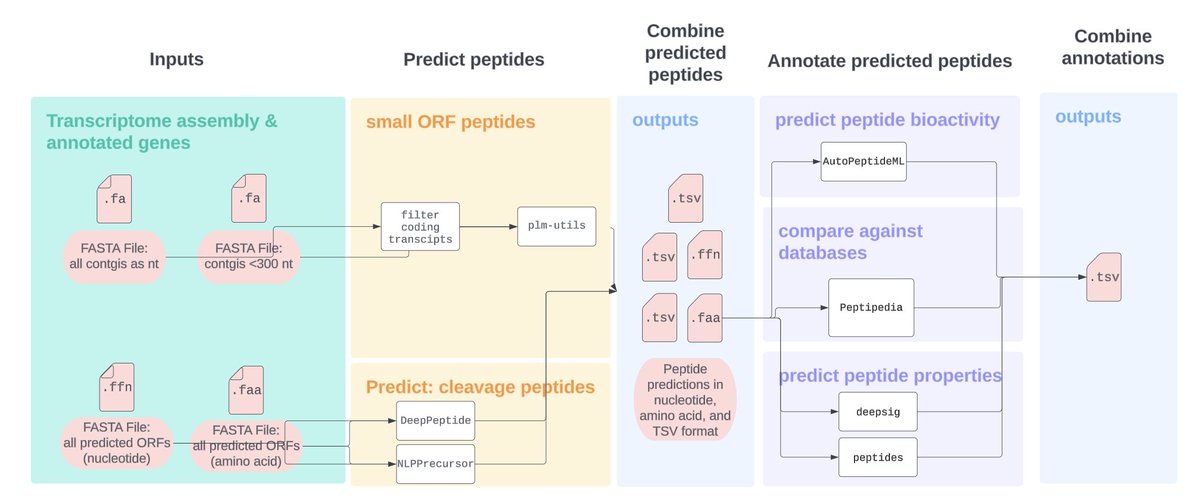
Introducing peptigate (peptide+investigate), a workflow that predicts and annotates peptides from transcriptome assemblies. It predicts small ORF-encoded peptides, cleavage peptides, and ribosomally synthesized and posttranslationally modified peptides.🧵
https://t.co/nX3nZ382PL
Learn more about plm-utils by reading our pub, “Using protein language models to predict coding and noncoding transcripts,” or see the GitHub repository.
https://t.co/zxnnun3O3w
https://t.co/yql2mLJIhz
Have you ever wondered whether a transcript is coding or noncoding? Or whether a predicted open reading frame encodes a functional protein? We recently had this question for very short open reading frames (sORFs). Enter the Python package plmutils 🧵
https://t.co/zxnnun3O3w
This was a combined effort between many scientists @ArcadiaScience. @Gilad had the initial idea to use ESM embeddings to improve prediction accuracy, while @kchev implemented the code and performed some of the validation.