I've defended and graduated!
Perhaps the most important lesson I've learned during my time at MIT is that progress in science (and in society!) is deeply collective. In today's world --- and especially in a hyper-competitive field like AI research --- it's easy to get sucked into comparison and self-doubt. Much of this, I think, comes from a misunderstanding of how scientific progress actually works: we tend to attribute oversized credit to a small number of figures. But certainly none of the work I've done, and none of the growth I've undergone, would have been possible without the support of my mentors, collaborators, and the insights of millions of brilliant scientists before me.
Along these lines, I am grateful to the amazing community around me who have supported my journey: most importantly, to my advisor @jacobandreas, the dozens of collaborators I've worked with during my PhD, my labmates, my mentees, and my co-organizers at @MITGradUnion --- all of whom have shown me, in various ways, what it means to work not out of comparison but out of love: for science, for the community around me, and for humanity.
I hope to carry forward these values wherever I go.
@gpusteve This is what grouped GEMM kernels are for :) Only two GEMM kernel launches per rank (in forward). Choose the dtype that makes sense for you numerically and then write the kernels that will make it fast.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
We have a new blog about cluster launch control (CLC) on NVIDIA Blackwell GPUs! CLC is a powerful tool for dynamically scheduling work across the GPU, both within- and accross-kernels.
https://t.co/5eNykPOBFb
I alluded to this a few tweets ago but just pushed up a shortish blog on a subtle feature of CLC work stealing that makes cuda-graphable grouped_gemm possible with this scheduling mode:
https://t.co/n665ou3PRv
My colleagues Jack Carlisle and Jay Shah gave a fantastic lecture for @GPU_MODE yesterday on our categorical foundations for CuTe layout algebra! They were joined by Cris Cecka, the inventor of CuTe, and @marksaroufim as moderators. Bravi tutti!
https://t.co/FRsiOAPGfH
🚀 Linear Attention is unlocking million-token context windows by dropping computational complexity from O(N^2) to O(N), but software is increasingly bottlenecking the hardware.
Meet cuLA (CUDA Linear Attention): hand-written kernels using CuTe DSL & CUTLASS C++ to extract maximum performance on NVIDIA GPUs. A drop-in replacement for FLA designed to push hardware to its absolute limits.
Thank you to the companies and open-source communities behind Kimi K2.5, Ray, ThunderKittens, PyTorch, and more.
We'd also like to thank Fireworks and Colfax for their collaboration and partnership.
PyTorch 2.11 is now available, featuring 2,723 commits from 432 contributors since PyTorch 2.10. This release prioritizes performance scaling for distributed training and next-generation hardware architectures.
Highlights include a FlashAttention-4 backend for FlexAttention on Hopper and Blackwell GPUs, Differentiable Collectives for distributed training, and performance optimizations for Intel GPUs via XPU Graph. This release also delivers comprehensive operator expansion for Apple Silicon (MPS) and RNN/LSTM GPU export support.
🖇️ Read the PyTorch 2.11 release blog and release notes: https://t.co/JZ4xkjEiNQ
#PyTorch #OpenSource #AIInfrastructure
The frontier has increasingly shifted to hybrid models - from Qwen to Kimi-Linear and now with NVIDIA's Nemotron-3 Super - that rely on a strong linear sequence model. Today we release Mamba-3, the most powerful linear model to date.
https://t.co/OpMmqEWMkP
@drisspg@gaunernst it's pretty close, but FA-4 is missing in particular some of the inference optimizations that FA-3 has, such as cuda graphability via dynamic scheduling metadata. coming soon, though!
FlexAttention now has a FlashAttention-4 backend.
FlexAttention has enabled researchers to rapidly prototype custom attention variants—with 1000+ repos adopting it and dozens of papers citing it.
But users consistently hit a performance ceiling. Until now.
We've added a FlashAttention-4 backend to FlexAttention on Hopper and Blackwell GPUs. PyTorch now auto-generates CuTeDSL score/mask modifications and JIT-instantiates FlashAttention-4 for your custom attention variant.
The result: 1.2× to 3.2× speedups over Triton on compute-bound workloads.
🖇️ Read our latest blog here: https://t.co/KVElBn4TEE
No more choosing between flexibility and performance.
hashtag#PyTorch hashtag#FlexAttention hashtag#FlashAttention hashtag#OpenSourceAI
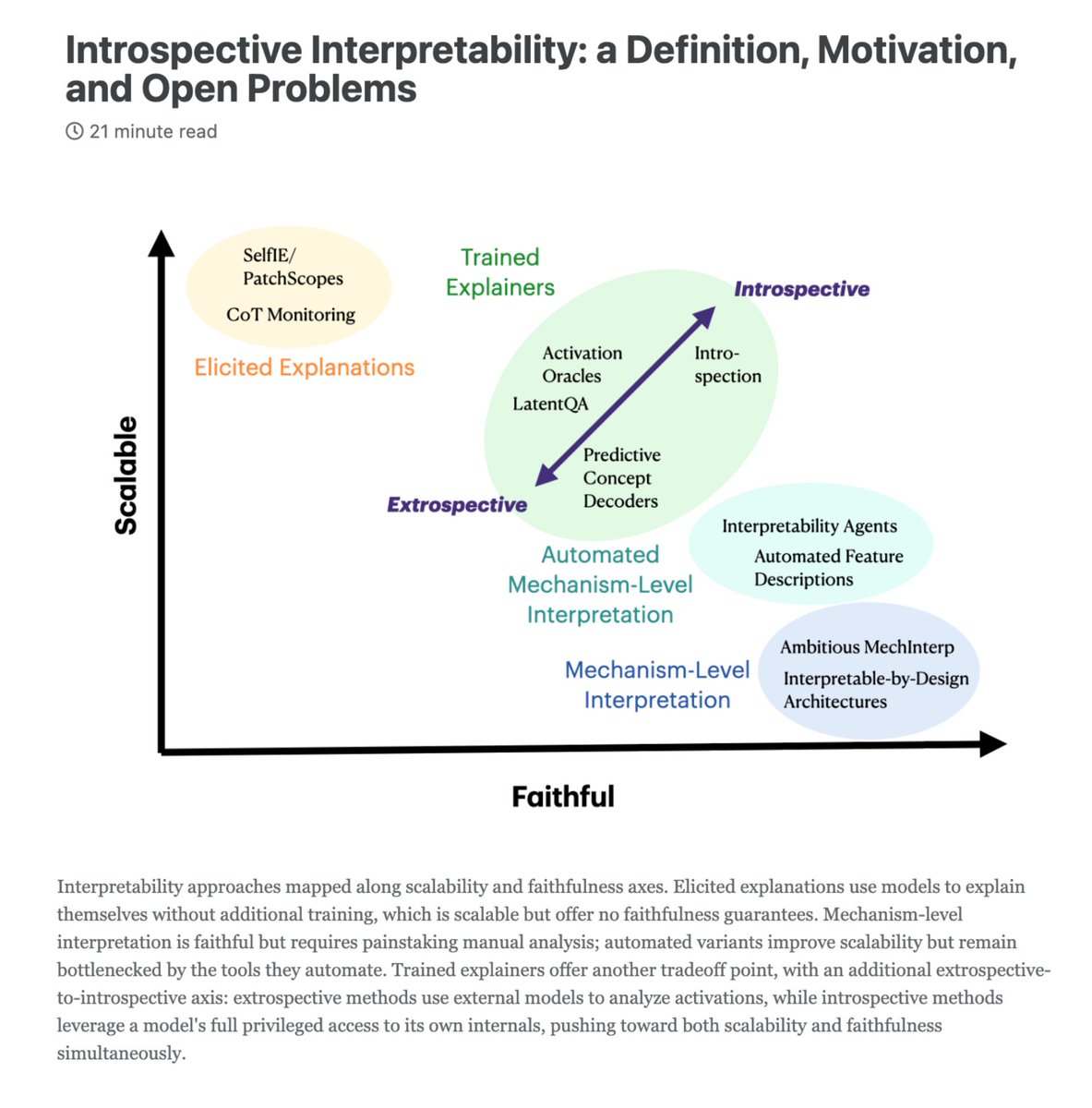
New blog post on introspection for interpretability, and why I think training models to self-explain is a promising frontier for interpretability research: