Found something in my daily use of Claude Code that validates our Memento results:
Claude Code flushes the KV cache after some idle period, and when I come back past that the model is noticeably harder to work with.
Conjecture: post-flush, the model is no longer continuing its trajectory. It's shoved into a weird OOD regime where it has to simulate what has happened from the tokens and resume from a reconstruction.
Which is much harder than just continuing!!
We measured this effect in our paper. KV states (soft embeddings) carry information that text tokens don't, even when attention is masked.
Bottom line: If you flush your cache you lose a lot of accuracy!
@simonw “If a user indicates they are ready to end the conversation, Claude does not request that the user stay…”
Where people really out here telling Claude they want to stop, instead of… just stopping?
The power of the Claw, in the palm of a robot hand. Agentic robotics is here! Today, we open-source CaP-X: vibe agents, alive in the physical world. They incarnate as robot arms and humanoids with a rich set of perception APIs, actuation APIs, and auto synthesize skill libraries as they go. CaP-X is a strict superset of our old stack, because policies like VLAs are “just” API calls as well. It solves many tasks zero-shot that a learned policy would struggle with.
And we are doing much more than vibing. CaP-X is our most systematic, scientific study on agentic robotics so far:
- We build a comprehensive agentic toolkit: perception (SAM3 segmentation, Molmo pointing, depth, point cloud), control (IK solvers, grasp planner, navigation), and visualization (EEF, mask overlays) that work across different robots.
- CaP-Gym: LLM’s first Physical Exam! 187 manipulation tasks across RoboSuite, LIBERO-PRO, and BEHAVIOR. Tabletop, bimanual, mobile manipulation. Sim and real. Can’t wait to see the gradients flow from CaP-Gym to the next wave of frontier LLM releases.
- CaP-Bench: we benchmark 12 frontier LLMs/VLMs (Gemini, GPT, Opus, Qwen, DeepSeek, Kimi, and more) across 8 evaluation tiers. We systematically vary API abstraction level, agentic harness, and visual grounding methods. Lots of insights in our paper.
- CaP-Agent0: a training-free agentic harness that matches or exceeds human expert code on 4 out of 7 tasks without task-specific tuning.
- CaP-RL: if you get a gym, you get RL ;). A 7B OSS model jumps from 20% to 72% success after only 50 training iterations. The synthesized programs transfer to real robots with minimal sim-to-real gap.
3 years ago, our team created Voyager, one of the earliest agentic AI that plays and learns in Minecraft continuously. Its key ideas — skill libraries, self-reflection loops, and in-context planning — have since influenced many modern agentic designs.
Today, the agent graduates from Minecraft and gets a real job. It’s April Fool’s, but this Claw is getting its hands dirty for real!
Link in thread:
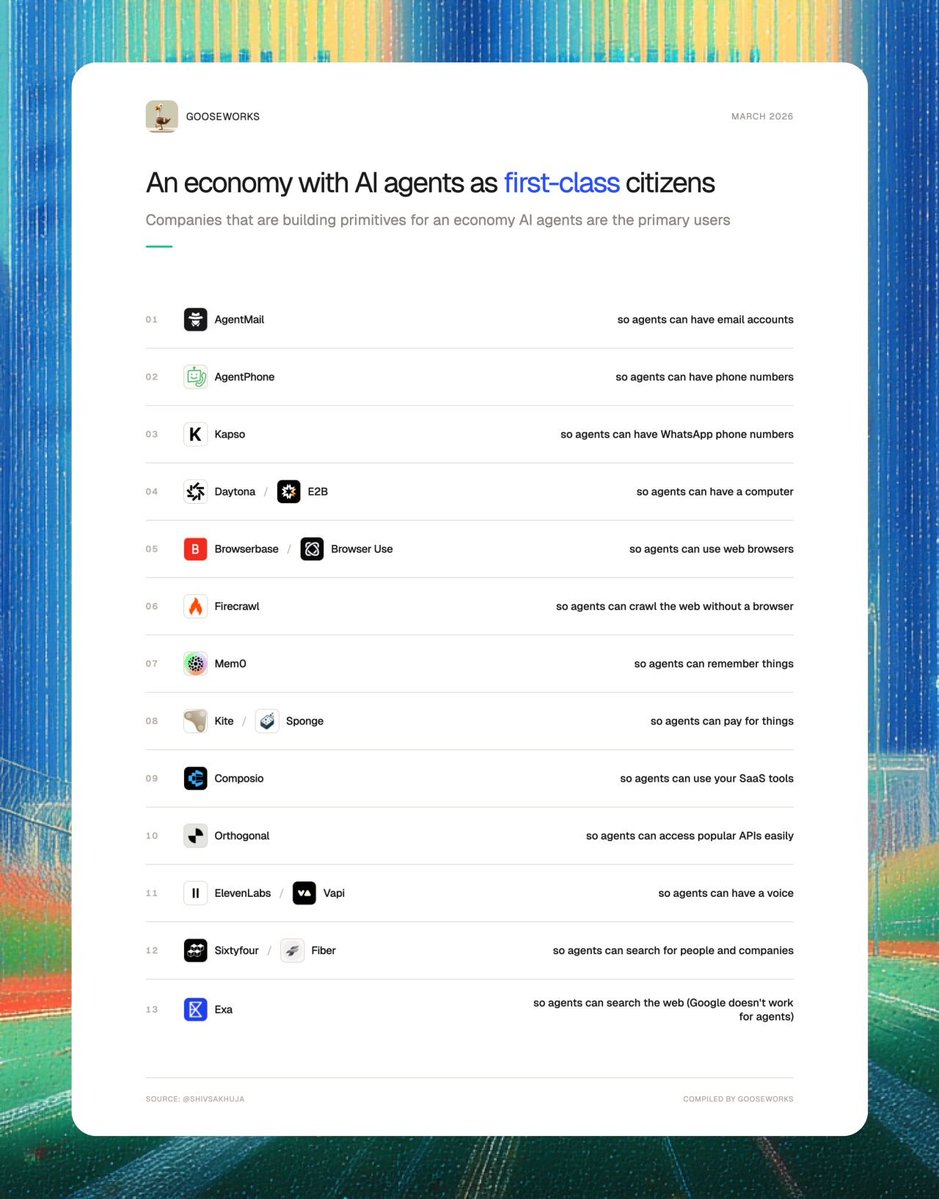
Lots of companies are now building primitives for an economy where AI agents are the primary users instead of humans.
They're betting on an economy of AI coworkers.
1. AgentMail (@agentmail): so agents can have email accounts
2. AgentPhone (@tryagentphone): so agents can have phone numbers
3. Kapso (@andresmatte): so agents can have WhatsApp phone numbers
4. Daytona (@daytonaio) / E2B (@e2b): so agents can have their own computers
5. Browserbase (@browserbase) / Browser Use (@browser_use) / Hyperbrowser (@hyperbrowser): so agents can use web browsers
6. Firecrawl (@firecrawl): so agents can crawl the web without a browser
7. Mem0 (@mem0ai): so agents can remember things
8. Kite (@GoKiteAI) / Sponge (@PayspongeLabs) : so agents can pay for things.
9. Composio (@composio): so agents can use your SaaS tools
10. Orthogonal (@orthogonal_sh) so agents can access APIs easily
11. ElevenLabs (@ElevenLabs) / Vapi (@Vapi_AI) so agents can have a voice
12. Sixtyfour (@sixtyfourai) so agents can search for people and companies.
13. Exa (@ExaAILabs): so agents can search the web (Google doesn’t work for agents)
If you stitch all of these together, you get a digital coworker that looks more human than AI.
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
Introducing the Agent Virtual Machine (AVM)
Think V8 for agents.
AI agents are currently running on your computer with no unified security, no resource limits, and no visibility into what data they're sending out. Every agent framework builds its own security model, its own sandboxing, its own permission system. You configure each one separately. You audit each one separately. You hope you didn't miss anything in any of them.
The AVM changes this.
It's a single runtime daemon (avmd) that sits between every agent framework and your operating system. Install it once, configure one policy file, and every agent on your machine runs inside it - regardless of which framework built it. The AVM enforces security (91-pattern injection scanner, tool/file/network ACLs, approval prompts), protects your privacy (classifies every outbound byte for PII, credentials, and financial data - blocks or alerts in real-time), and governs resources (you say "50% CPU, 4GB RAM" and the AVM fair-shares it across all agents, halting any that exceed their budget). One config. One audit command. One kill switch.
The architectural model is V8 for agents. Chrome, Node.js, and Deno are different products but they share V8 as their execution engine. Agent frameworks bring the UX. The AVM brings the trust. Where needed, AVM can also generate zero-knowledge proofs of agent execution via 25 purpose-built opcodes and 6 proof systems, providing the foundational pillar for the agent-to-agent economy.
AVM v0.1.0 - Changelog
- Security gate: 5-layer injection scanner with 91 compiled regex patterns. Every input and output scanned. Fail-closed - nothing passes without clearing the gate.
- Privacy layer: Classifies all outbound data for PII, credentials, and financial info (27 detection patterns + Luhn validation). Block, ask, warn, or allow per category. Tamper-evident hash-chained log of every egress event.
- Resource governor: User sets system-wide caps (CPU/memory/disk/network). AVM fair-shares across all agents. Gas budget per agent - when gas runs out, execution halts. No agent starves your machine.
- Sandbox execution: Real code execution in isolated process sandboxes (rlimits, env sanitization) or Docker containers (--cap-drop ALL, --network none, --read-only). AVM auto-selects the tier - agents never choose their own sandbox.
- Approval flow: Dangerous operations (file writes, shell commands, network requests) trigger interactive approval prompts. 5-minute timeout auto-denies. Every decision logged.
- CLI dashboard: hyperspace-avm top shows all running agents, resource usage, gas budgets, security events, and privacy stats in one live-updating screen.
- Node.js SDK: Zero-dependency hyperspace/avm package. AVM.tryConnect() for graceful fallback - if avmd isn't running, the agent framework uses its own execution path. OpenClaw adapter example included.
- One config for all agents: ~/.hyperspace/avm-policy.json governs every agent framework on your machine. One file. One audit. One kill switch.
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).
@kvickart@simonw Yup it’s always been a game to get exactly the right tokens in exactly the right order to illicit an optimal (subjective) response. It’s NP-Hard
PSA: the new plan mode "clear context and auto-accept" doesn't summarize your conversation, it discards it entirely. The plan file you approve becomes the sole source of truth, so it must be good enough to stand on its own
2. Start every complex task in plan mode. Pour your energy into the plan so Claude can 1-shot the implementation.
One person has one Claude write the plan, then they spin up a second Claude to review it as a staff engineer.
Another says the moment something goes sideways, they switch back to plan mode and re-plan. Don't keep pushing. They also explicitly tell Claude to enter plan mode for verification steps, not just for the build