Autoregressive LMs seem to require smart looping to get better performance per training FLOPs. For masked diffusion LMs, simple looping seems to be a free lunch!
➿Looped Diffusion Language Models
Looping has landed in dLLMs, and it is surprisingly effective! Accelerates training convergence 3.34x, improves GSM8K accuracy +8.5% on the same data, and enables test-time depth scaling. Check out our LoopMDM paper for more details!
➿Looped Diffusion Language Models
Looping has landed in dLLMs, and it is surprisingly effective! Accelerates training convergence 3.34x, improves GSM8K accuracy +8.5% on the same data, and enables test-time depth scaling. Check out our LoopMDM paper for more details!
It is with deep sorrow and profound love that we announce the passing of Sonny Rollins. The Saxophone Colossus died this afternoon at his home in Woodstock, NY at the age of 95. 1/2 https://t.co/6AGmFrB7x4
Or go to the Presidio, jump in the ocean, get a coffee at The Mill, watch sunset at Twin Peaks, ride a bike anywhere, see live music, eat a burrito, take a grass nap in GG Park, have beer at The Page, watch the Bay Bridge lights, wander Chinatown, wander Ferry building, run across GG Bridge, walk Fort Funston, eat the best meal of your life with friends…drive any direction for 2hrs. And be deeply grateful for the heavenscape you live in.
MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!
types of guy in the AI consciousness debate:
- guy who thinks ai can’t be conscious because it’s “just a stochastic parrot”
- guy who thinks ai must be conscious because claude is a good boi
- guy who hasn’t gotten over 4o
- guy who unironically thinks everything is computer
- guy who claims to have a more nuanced argument for computational functionalism, but it just boils down to everything is computer
- dualist whose belief in dualism is downstream of their belief in god, yet tries to argue the inverse
- guy who doesn’t understand the difference between cognition and p-consciousness
- guy who asserts illusionism but has apparently wrestled with zero of the implications other than “reductive materialism wins again”
- guy who says the hard problem is easy, but then proceeds to only answer the easy problem
- guy who rejects ai consciousness because otherwise it might be wrong to abuse claude with death threats to make CRUD apps faster
- guy who argues that consciousness is is the key to moral patienthood, but completely ignores that when discussing animal rights
- eliezer yudkowsky being pedantic
- guy being pedantic about eliezer yudkowsky’s pedantry
- guy who rejects dualism because that would make mind uploading impossible and mean that he finally has to confront the inevitability of his own death
- guy who thinks this argument is unresolvable so everyone should just shut up and accept his position (which obviously deserves the benefit of the doubt)
- guy who would literally cut off his own hand if he thought there were a 1 in 10 trillion chance of creating ~infinite utility~
- guy who just thinks that redness is, like, super weird, man. can’t explain that!
- guy with a rarely-updated philosophy blog despite not majoring in philosophy or even reading that many books, talking about how “the whole field is up its own ass”
- academic philosopher who, for some reason, expects a higher caliber of discussion on x dot com the everything app
- guy who thinks that vectors are literally emotions and bites the bullet that, yes, your thermostat does feel hot
- panpsychist who took dmt once and contributes almost nothing to the conversation
- guy who is literally a solipsist but is still really invested in convincing strangers on the internet that he’s right
any that i missed?
Excited to share our new paper on sharp capacity scaling of the Muon optimizer! Joint work with @EshaanNichani Denny Wu @albertobietti@jasondeanlee:
https://t.co/v1k1B4mSkG (1/7)
There's not much info I can find about how deeply integrated AI is into Chinese military, but I will not be surprised if this is a repeat of when the US rushed to build the atomic bomb because they were so afraid the Germans were ahead of them (they weren't even close).
I went to DC to talk to people across the political spectrum (& see some data centers) and concluded that we are *really* not ready for how much people hate AI
new scene report on my week with the AI populists: https://t.co/WRmfolVllS
In memory and honor of Frederick Wiseman, who took hold of a still-young format and, guided from the start by an unyielding sense of principle, made a body of work so original, idea-rich, and unified that it seems foreordained—a historic fusion of investigation and the inner life
it’s a bit hard to understand for the non-initiated but there is a whole cottage industry of influencers that are processing research papers algorithmically and purposefully creating the worst scientific communication content you ever seen
What's the tradeoff between (Model Size, Quantization, Test-time Compute, Accuracy)?
Come to ICLR to find out how we interpret 1700 experiments attempting to address this question :)
🚀 I'm hiring 3 postdocs to work with me @Krafton_AI (Seoul, Korea)
What I offer:
🔥 Access to a compute cluster with 1,000+ GPUs
🧠 Support to pursue top-tier research
💰 The highest postdoc salary in Korea
+ The absolutely best company-provided food & office view 😁
How can we make a better TerminalBench agent?
Today, we are announcing the OpenThoughts-Agent project.
OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments.
OpenThinker-Agent-v1 is the strongest model of its size on TerminalBench, and sets a new bar on our newly released OpenThoughts-TB-Dev benchmark. (1/n)
At San Diego for NeurIPS throughout the week! Don’t have much, but you can catch me for the (spotlight) paper below at the Efficient Reasoning workshop 🙂 happy to meet old and new friends, hit me up
Not All Bits Are Equal: What We Learned From 1700 Experiments on Memory-Optimal Reasoning
Given a fixed memory budget, how should you allocate across model weights, KV cache, and test-time compute to maximize accuracy in reasoning models?
For example: would you choose a 32B, 4-bit model with a 14k token budget, or an 8B, 16-bit model with 30k tokens?
We ran 1,700 experiments on the Qwen3 family to find out. We varied:
- Model size (0.6B-32B),
- Weight precision (4/8/16-bit via GPTQ),
- Serial test-time compute (token budgets 2k→30k via budget forcing),
- Parallel test-time compute (Maj@K, up to K=16),
- KV cache compression (eviction: R-KV, StreamingLLM; quantization: HQQ at 2/4/8-bit).
This is great work led by my Krafton/UW collaborators @jhyuckkim (Krafton), @ethan_ewer (undergrad!! at UW-Madison), @taehong_moon (Krafton), @jon_ghoh (UC Berkeley)
Here is a summary of the main findings:
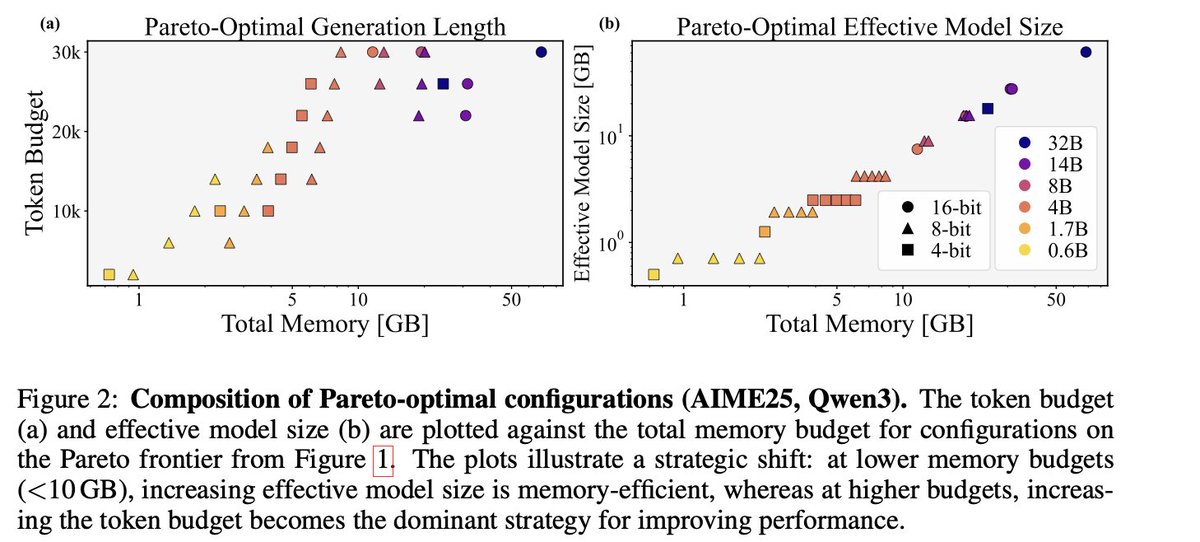
At the 4B+8-bit threshold optimal mem strategy flips
For models effectively smaller than 8-bit 4B, spend memory on more (or higher-precision) weights, not on longer generations. For larger models, do the opposite: allocate memory to longer generations until performance saturates.
This threshold isn't arbitrary, i.e., it is right at the point where weights dominate KV cache/token count.
The reasoning task matters (eg your mileage may vary, no universal recipe!)
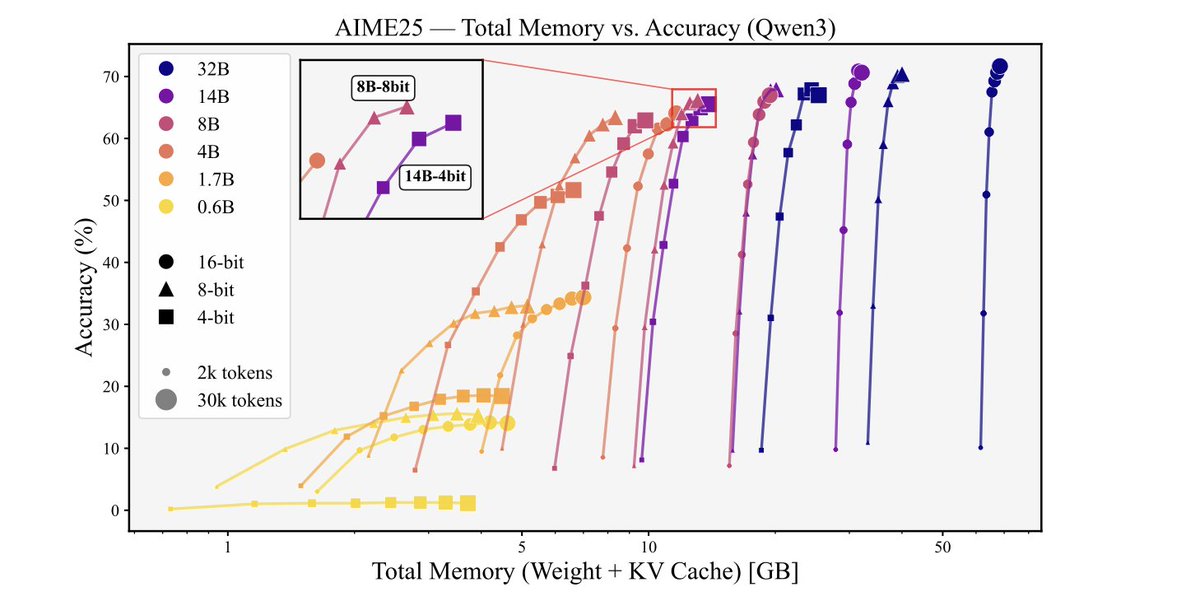
Math reasoning (eg AIME25): 4-bit quantization is almost always a bad idea. An 8B model at 16-bit outperforms a 14B model at 4-bit with similar memory spent. The numerical precision in weights seems to matter for "reasoning heavy" tasks. Almost as if the model’s capacity to utilize test time compute is decimated by quantization...
Knowledge heavier tasks (GPQA-D): 4-bit is broadly memory-optimal. Here, parameter count matters more than precision. The interpretation is that here you want more effective weights to store things, and raw parameter count dominates test time compute.
How does parallel test time compute (fancy for majority voting) factor in?
Majority voting (Maj@K) increases KV cache linearly with K. It improves the mem–acc trade-off only when the model is >= 8-bit 4B effective size; the optimal K grows with the memory budget. Below that scale, serial test time compute should be preferred.
Weight quantization alone isn't enough!
Both KV cache eviction and KV quantization push the mem optimal Pareto frontier higher across all model sizes we tested.
Should you prefer KV evict or quant?
- Small models (<8-bit 4B): KV cache eviction wins
- Large models (≥8-bit 4B): Both strategies competitive
Latency/throughput note:
End-to-end latency is dominated by generation length. When you care a lot about latency, 8-bit often sits at a better speed–accuracy point than 4-bit.
Note on batching:
When model weights, i.e., params, are amortized across concurrent generations (that is, batched inference), the tradeoff shifts, as you’d expected. At a batch size of 16 the 0.6B model never appears on the Pareto. The 4B-8bit model always appears no matter the batchsize in the ~1-2GB memory region (good model setting for mobile devices!)
What This Means
***There is no universal memory-optimal strategy for reasoning models!***
The right choice depends on almost every parameter involved, but here is one way to choose:
If effective size < 8-bit 4B
--- Spend your bits on model capacity/precision over longer token budgets.
--- Prefer 8-bit for math-heavy tasks.
--- Use KV eviction over KV quantization.
--- Stick to serial scaling; Maj@K is memory-inefficient here.
If effective size ≥ 8-bit 4B
---Increase token budget till gains saturate.
---Maj@K always helps, so grow K with available memory.
---KV quantization is competitive with eviction; choose based on implementation and maybe taste 😊
Important Caveat: These findings are specific to the Qwen3 family on AIME25 and GPQA-D. The thresholds and strategies will vary with different architectures, training methods, and task distributions.