Libertad, equidad, esfuerzo y evolución. En ellos creo. Valoro el afecto, la lealtad y la humildad. Admiro el talento. En Digevo oficio de emprendedor.
Extraordinary. We are stardust.
Asteroid Bennu contain all 5 of nucleobases that form DNA and RNA on Earth and 14 of 20 amino acids found in living organisms (though Bennu contains equal amounts of these structures and their right-handed counterparts). https://t.co/kmTcpcmTKd
In 1965, Singapore was forced out of Malaysia.
No army.
No resources.
No fresh water.
A tiny island of 2M people living in slums.
Then ONE man's ruthless vision built modern Asia's greatest success...
🧵
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
Actually, as the LLM stack becomes more and more mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem is fixed at that of "next token prediction" with an LLM, it's just the usage/meaning of the tokens that changes per domain.
If that is the case, it's also possible that deep learning frameworks (e.g. PyTorch and friends) are way too general for what most problems want to look like over time. What's up with thousands of ops and layers that you can reconfigure arbitrarily if 80% of problems just want to use an LLM?
I don't think this is true but I think it's half true.
La mañana del 16 de diciembre de 1947, este cacharro cambió la historia de la informática, abriendo la puerta a la miniaturización. Es el primer transistor y, aunque no lo sepas, tiene un relación muy estrecha con cierto género literario de marcianos... 🛸
¡Dentro hilo! 🧵👇
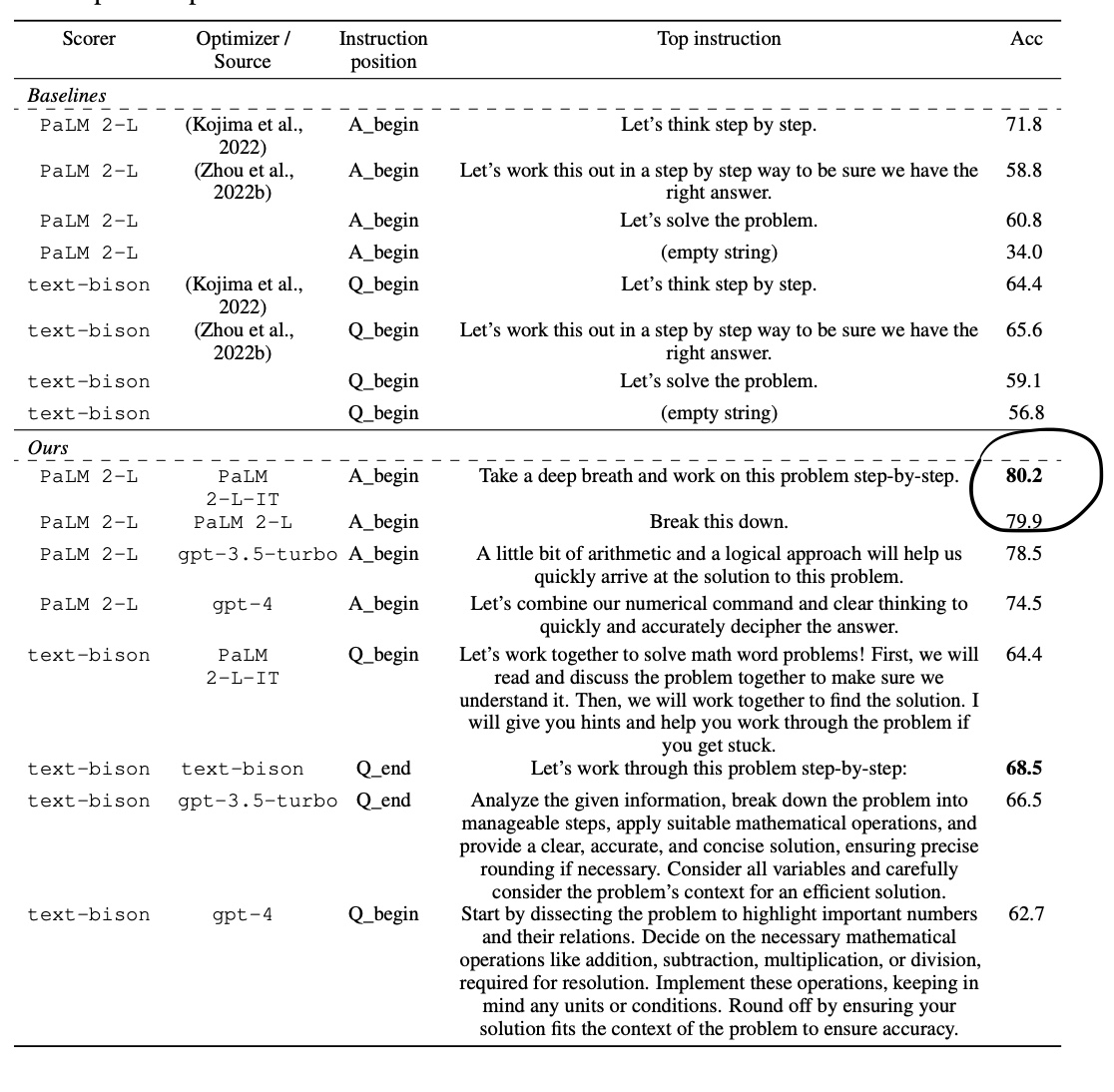
"Take a deep breath and work on this problem step-by-step." 😌
It may sound like a joke 😄, but this is the bottom line of Deepmind's recent paper...
Deepmind released a paper, titled 'Large Language Models as Optimizers,' where they used LLMs to optimize the prompts given to another LLM in order to improve its output.
In one of their experiments 🧪, they used Google's Palm as an optimizer, and eventually, it converged into a prefix that increased the accuracy of the following prompt by approximately 9% on average, and it was not other than: 'Take a deep breath and work on this problem step-by-step.'
I find it shocking that mathematical optimization converged to this very human empathic-like suggestion - "take a breath..." 😅. On the other hand, it was trained on what we human write everywhere, and this writing probably reflects us mindset more than we might think.
So I'll take a deep breath and move to my next meeting...
Readmore - https://t.co/OYN00DXhWa
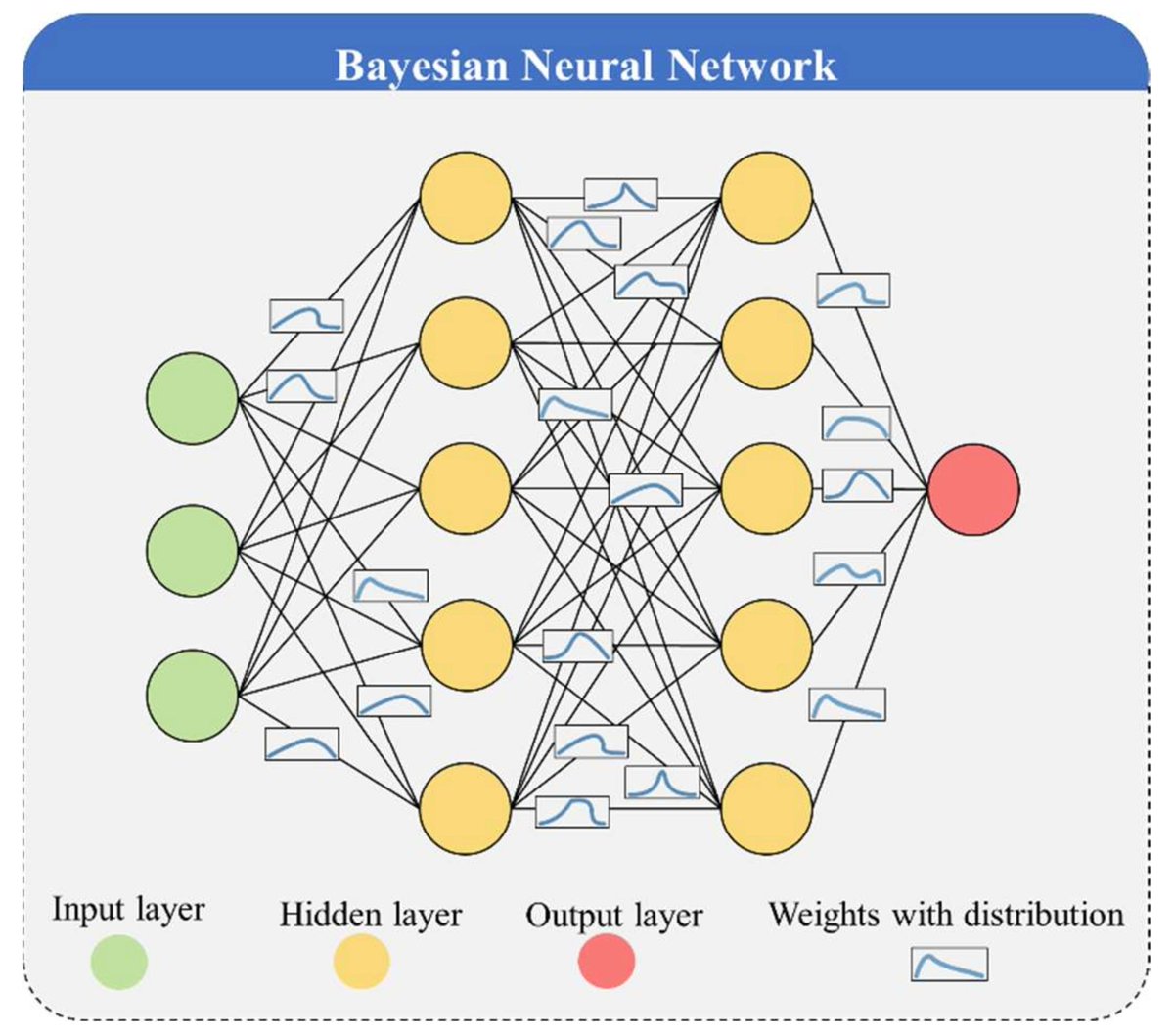
Bayesian Neural Networks - Capturing The Uncertainty Of The Real World
Life is inherently uncertain and probabilistic, and Bayesian Neural Networks (BNNs) are designed to capture and quantify that uncertainty
In many real-world applications, it's not sufficient to make a prediction; you also want to know how confident you are in that prediction. For example, in healthcare, a model that says a patient has a 70% chance of having a particular disease is less informative than one that says there's a 70% chance but with a margin of error of ±10%.
BNNs are less prone to overfitting, can be more data efficient as they can incorporate priors, and can output a probability distribution for each prediction. Knowing the uncertainty or the probability that a particular prediction is accurate builds trust and confidence with business users.
So how do Bayesian Networks Work?
The core idea is to replace the fixed weights w in a standard neural network with probability distributions P(w)
The famous equation from Bayes is:
P(A|B)=P(B|A)P(A) / P(B)
In the context of BNNs:
A is the model parameters (weights and biases).
B is the observed data.
P(A∣B) is the posterior distribution of the parameters given the data.
P(B∣A) is the likelihood of the data given the parameters.
P(A) is the prior distribution of the parameters.
P(B) is the evidence, often considered a normalizing constant.
Prior Distribution - You start with a prior distribution P(w) over the weights. This represents your initial belief about the model parameters before seeing any data.
Posterior Distribution - The goal is to compute the posterior distribution P(w∣D), which represents the updated belief about the weights after observing data D. Bayes theorem along with some approximation methods are used to calculate this distribution.
Prediction - Finally, to make a prediction for a new input x, you average over all possible weights, weighted by their posterior probabilities:
P(y∣x,D)=∫P(y∣x,w)×P(w∣D)dw
This gives you not just a point estimate but a distribution over the possible outputs y, capturing the model's uncertainty.
For example: BNNs can be applied to a dataset of MRI scans where each scan is labeled either "Cancer" or "No Cancer." The goal is to build a model that can predict these labels for new, unlabeled MRI scans. A BNN can say, "I'm 80% sure this is cancer, but there's a 20% chance it's not," which is valuable information for clinicians.
BNNs are useful wherever uncertainty quantification is important including disease diagnosis, risk assessment, energy forecasting, and real-time decision-making
En #Chañaral Clase Magistral de @RobertoMussoM en lanzamiento “Curso de Innovación y Emprendimiento” para estudiantes del @CfTdeAtacama en el marco de la línea Viraliza de @Corfo ejecutada por @DigevoVentures, nuestro socio estratégico para impulsar el emprendimiento en #Atacama
#27ee |⌚️ ¡Iniciamos la cuenta regresiva del 27ee Encuentro de Ecosistemas: quedan 5 días!
¿Ya te inscribiste? ☝🏻Te extendemos la invitación al Seminario Impacto de la Inteligencia Artificial en EBCT
📅Jueves 3 de agosto
⏰15:00 horas
🔗https://t.co/MSZASDu1B3
Te esperamos!
NVIDIA recently hit $1T in market cap.
The CEO Jensen Huang flew to Taipei to give a commencement speech at NTU.
Not Stanford. Not Harvard. NTU.
Here are 5 key insights on AI from Jensen's speech 👇
AI developments this week were insane.
We got massive announcements from Epic Games, OpenAI, Amazon, multiple AI robots, the US Senate, Hippocratic AI, Zapier, Zoom, Elon Musk, Meta, DragGAN, and Apple.
Here's EVERYTHING you need to know and why it's important:
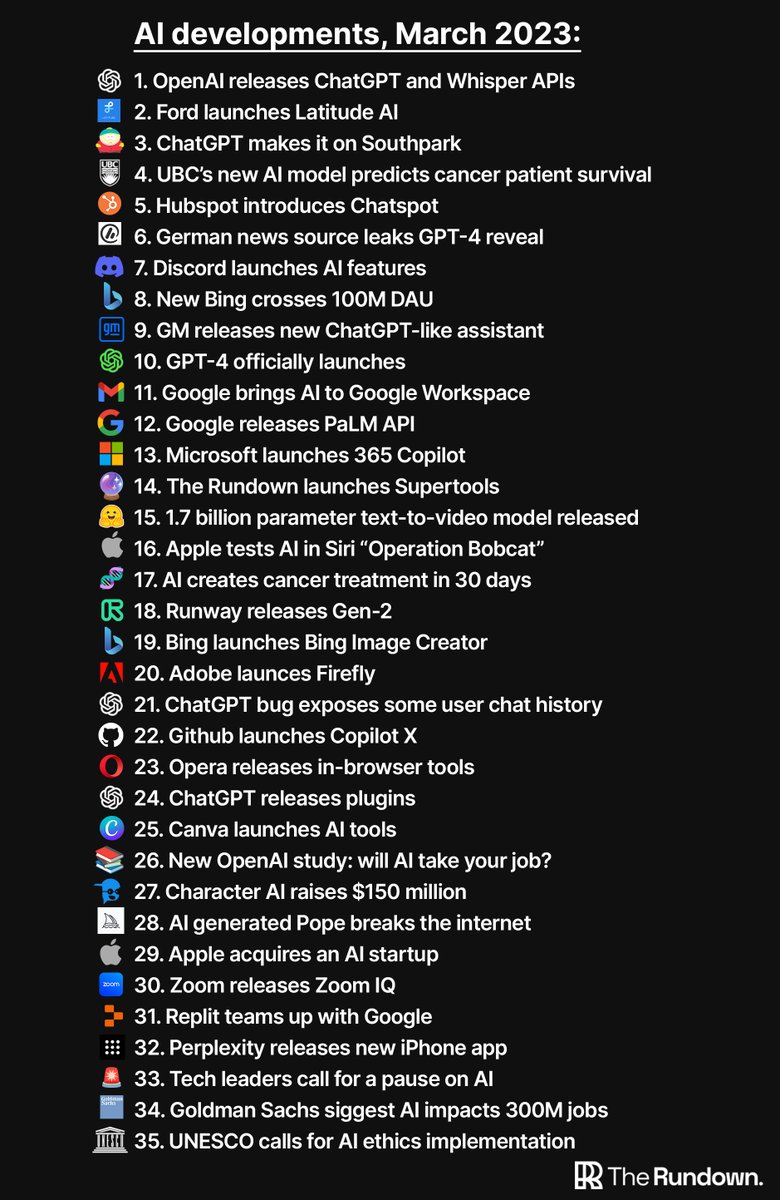
March of 2023 will go down as one of the most revolutionary months in history.
AI developments released this month changed the world forever.
Here's the rundown of the biggest events that happened 👇
El emprendimiento no es una moda. Es una consecuencia del cambio tecnológico. Preparar a todos los estudiantes universitarios para aprender es clave. https://t.co/eU0UGGMAF2
Colaborar con inteligencia artificial.
Es en lo que deben entrenar las universidades a todos los futuros profesionales. No importa la carrera que sigan.
Para eso, deben incorporar decididamente IA en el proceso educativo.
#int…https://t.co/foyJCF9rCC https://t.co/6t992MO6HR