#ICLR2023 New paper!
"Rethinking the expressive power of GNNs via graph biconnectivity" accepted as an 𝗼𝗿𝗮𝗹 𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 (notable-top 5%)
🔥A new direction to study GNN expressivity via graph biconnectivity!
👇Let's see the details of our fruitful results🤗
Excited to see our paper "Rethinking the expressive power of GNNs via graph biconnectivity" accepted as an 𝗼𝗿𝗮𝗹 𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 (notable-top 5%) at #ICLR2023!
https://t.co/jC6R1lCAPL
Joint work with @Roger98079446, Liwei Wang, and Di He
1/n
Can we turn part of an LLM's weights into long-term memory that continuously absorbs new knowledge?
We took a small step toward this with In-Place Test-Time Training (In-Place TTT) — accepted as an Oral at ICLR 2026 🎉
The key idea: no new modules, optional pretraining. We repurpose the final projection matrix in every MLP block as fast weights. With an NTP-aligned objective and efficient chunk-wise updates, the model adapts on the fly — complementing attention rather than replacing it.
📄 Paper: https://t.co/mtfkbptevk
with amazing @Guhao_Feng@Roger98079446 Kai @GeZhang86038849 Di @HuangRubio
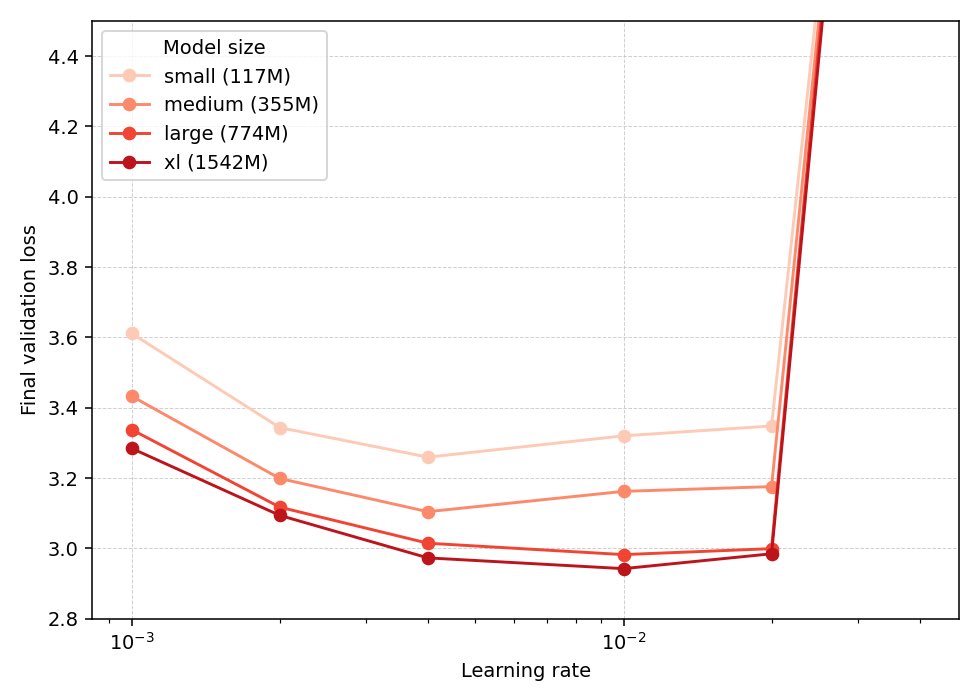
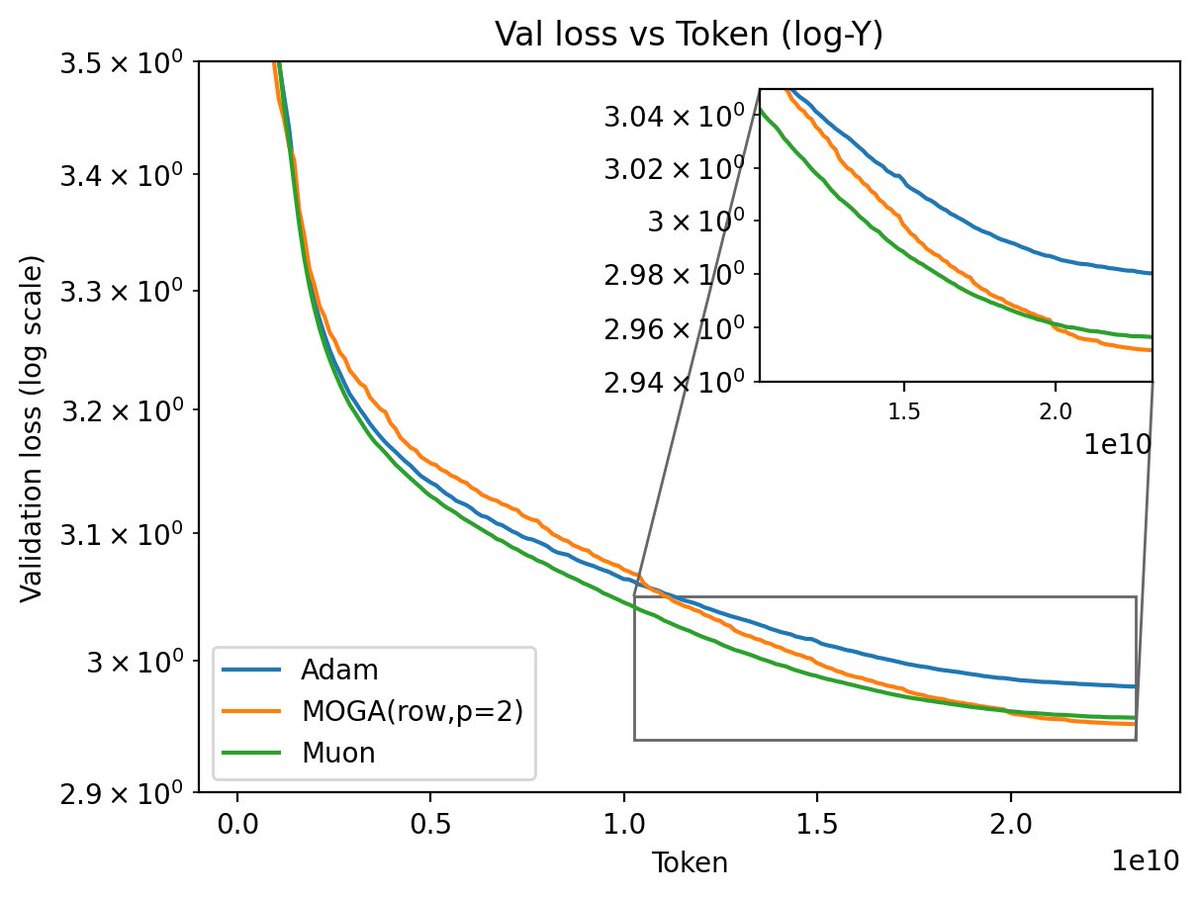
Gradient-Lipschitz analysis can recovers the scaling behind muP!Studying how network width changes the gradient Lip constant under operator norms, we
• recover muP scaling for Adam
• Muon’s smoothness can be bad
• New Row-wise gradient normalization is competitive with Muon
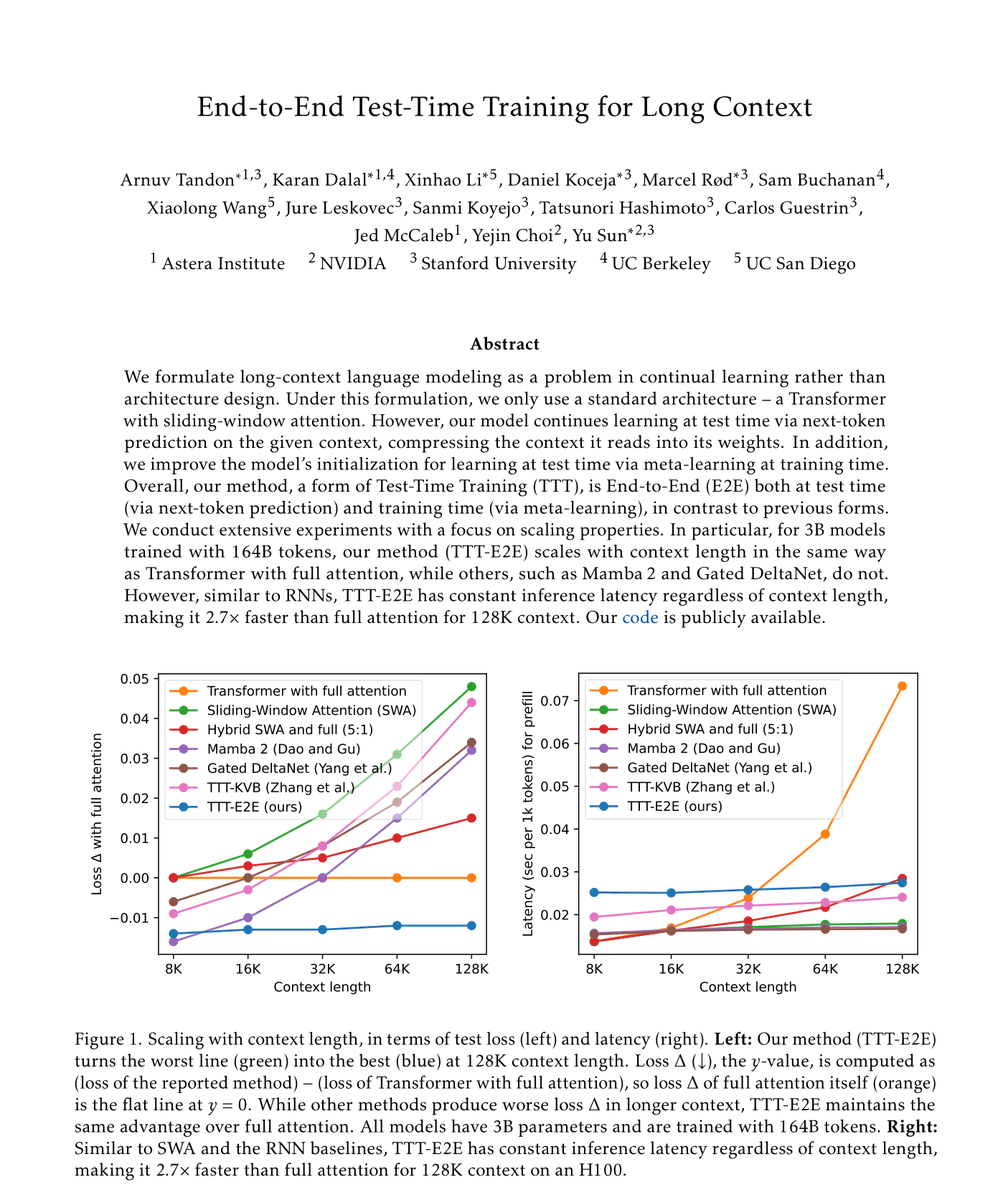
Our new paper, “End-to-End Test-Time Training for Long Context,” is a step towards continual learning in language models.
We introduce a new method that blurs the boundary between training and inference. At test-time, our model continues learning from given context using the same next-token prediction objective as training.
With this end-to-end objective, our model can efficiently compress substantial context into its weights and still use it effectively, unlocking extremely long context windows for complex reasoning and applications in agents and robotics.
Paper: https://t.co/tqPYECjFpn
Code: https://t.co/tADD7wYDAL
One point I made that didn’t come across:
- Scaling the current thing will keep leading to improvements. In particular, it won’t stall.
- But something important will continue to be missing.
Diagnosing and Improving Diffusion Models by Estimating the Optimal Loss Value
"We first derive the optimal loss in closed form under a unified formulation of diffusion models, and develop effective estimators for it, including a stochastic variant scalable to large datasets with proper control of variance and bias. With this tool, we unlock the inherent metric for diagnosing the training quality of mainstream diffusion model variants, and develop a more performant training schedule based on the optimal loss. Moreover, using models with 120M to 1.5B parameters, we find that the power law is better demonstrated after subtracting the optimal loss from the actual training loss, suggesting a more principled setting for investigating the scaling law for diffusion models."
Just grasped the true significance (not just bc it's submitted by Wenfeng) of this work after reading @SonglinYang4 's explanation. The breakthrough isn't hybrid attention (studied years ago), but the ingenious kernel that delivers real-world speedups for dynamic sparse attention.
As someone who worked on efficient transformers in undergrad, I had the impression that combining "efficient attentions" (linear, sparse, conv, block-structured), which theoretically would be faster, had the potential to replace full attention but was practically slower.
But Deepseek's solution is different: By having each query group of a token attend to the same KV block, they can really reduce the memory movement and achieve FlashAttention-like memory efficiency.
This matters enormously for reasoning models that output long thinking processes (10k+ tokens). The efficient dynamic sparse kernel dramatically speeds up both training and inference for such models.
What a brilliant example of algorithm-system co-design!
Mitigating racial bias from LLMs is a lot easier than removing it from humans!
Can’t believe this happened at the best AI conference @NeurIPSConf
We have ethical reviews for authors, but missed it for invited speakers? 😡
Apropos of some real life discussions: We have superfast custom CUDA implementations for tensor-product-based (Clebsch-Gordan) equivariant NNs: https://t.co/GItpvKPfPi
Based on the papers (and heavily optimized further!) https://t.co/I57bE5hIr7 and https://t.co/M7EKAq3qK8
Charge density is the core attribute of atomic systems in DFT. When representing and predicting charge density with ML, it is challenging to balance accuracy and efficiency. We propose a recipe that achieves SOTA on both: https://t.co/mxKQczuKzF 1/5
#ICLR2024 Just arrived in Vienna! Don't miss our oral presentation tomorrow afternoon in room Halle A3, focusing on 𝗚𝗡𝗡𝘀 and their 𝗲𝘅𝗽𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗼𝘄𝗲𝗿! Also, swing by our poster session (Poster272, Halle B). See you there! 🌟
Experiment:
Extensive experiments are conducted to verify the efficiency and generality of our approach. See our paper and code repository for more details!
Paper: https://t.co/UOPRKA2lCd
Code: https://t.co/7Sn4jg7ZRh
Looking forward to your feedback!
10/10
Our Method4⃣:
As a fundamental operation, our Gaunt Tensor Product can be applied to major operation classes that are widely used in E(3) equivariant networks. A comprehensive analysis is provided in our work:
9/n