A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.
Figma shipped a silent patch specifically to kill figma-use — my open-source tool that did what they wouldn't: an MCP server that creates and modifies designs, JSX export, design linting. Then they scrambled to catch up with their own MCP server.
So I spent the weekend recreating @Figma from scratch.
OpenPencil: reads and writes .fig files, AI chat with full design tools, P2P collaboration with zero servers, ~7 MB app. No account, no subscription.
Three days, one developer, MIT license.
https://t.co/bPtP6JPbq0
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
This article explains the difficult trade-off of setting Kubernetes CPU limits, detailing how limits cause CPU throttling while omitting them risks noisy neighbor problems
➤ https://t.co/B88uDvYzlv
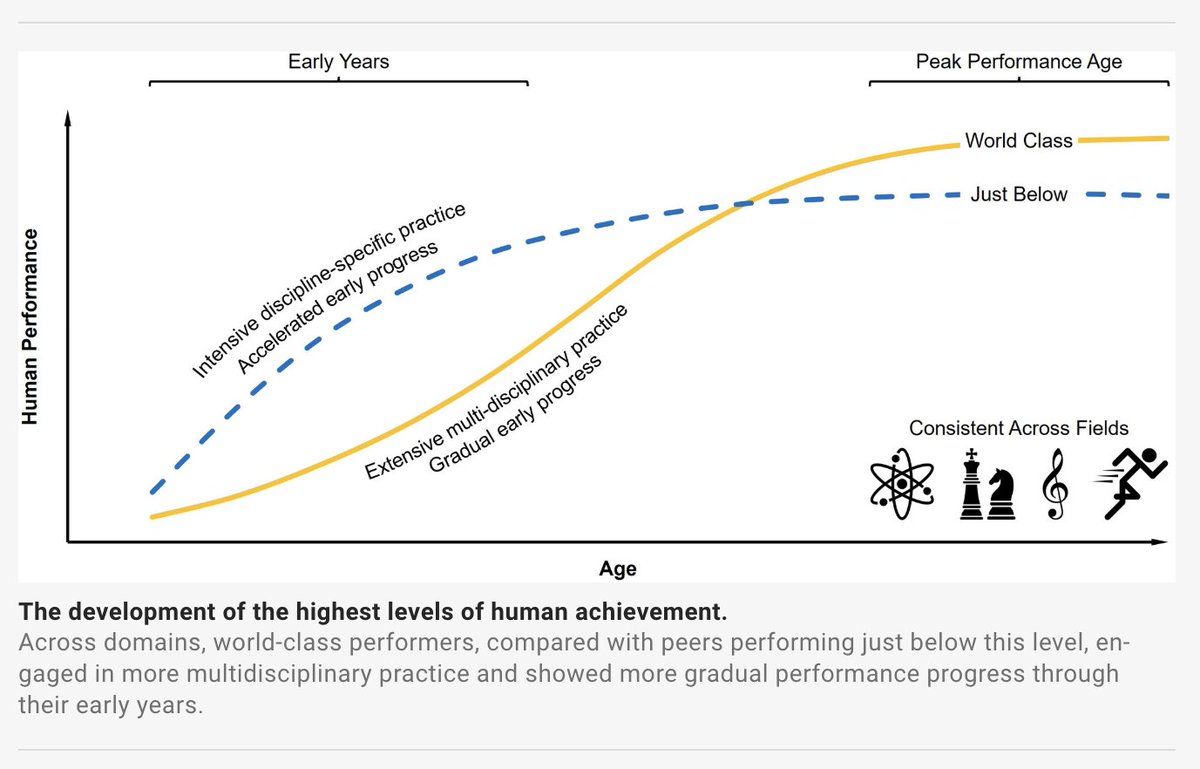
A massive new study on peak performance included 34,000 international top performers: Nobel laureates, renowned classical music composers, Olympic champs, and the world’s best chess players. It shows early specialization is a trap, and the road to greatness is long and varied.
Performance Hints
Over the years, my colleague Sanjay Ghemawat and I have done a fair bit of diving into performance tuning of various pieces of code. We wrote an internal Performance Hints document a couple of years ago as a way of identifying some general principles and we've recently published a version of it externally.
We'd love any feedback you might have!
Read the full doc at: https://t.co/jej95g236P
Announcing the Beta release of ty: an extremely fast type checker and language server for Python, written in Rust.
We now use ty exclusively in our own projects and are ready to recommend it to motivated users.
10x, 50x, even 100x faster than existing type checkers and LSPs.
Me 5 minutes after meeting somebody new: it's of utmost importance for you to
- open a broker account and buy Vanguard S&P 500 UCITS ETF (USD) Accumulating (VUAA), and
- take 10g creatine per day yes 5g was the previous recommendation but after 5g the benefits are cognitive and in studies it delays Alzheimer
- start lifting weights 3-4 times per week, strength training avoids guaranteed age-related muscle atrophy and bone density loss, no running is not enough, you need both strength training and cardio, get a personal trainer to check your form
- build a business or SaaS so you can escape the system of employee servitude which is generally built to exploit you, the only way to get really rich is own your own business and the earlier you start the sooner you'll succeed because it takes years to understand how to do a business so better start now
- as a guy you probably have low testosterone, it's an epidemic due to our processed food and soil depletion due to intense farming, you don't realize this is completely affecting your identity and behavior as a man, and in turn your relationships with women, and as a woman similarly your hormones are imbalanced too
- fix your hormones to how they should be (like they were 100 years ago) by working out, lifting weights (both for men and women), cardio and a clean diet of whole foods (meat, veg, fruit, eggs, water) and no processed food (whatever is made in a factory, eg 90% what's sold in stores)
- get therapy if you need, it's good if it solves things (like cognitive behavioral therapy) but it should always be combined with heavy workouts and a clean diet
- live near your friends because especially for men of middle age (your future) there is a loneliness epidemic, so to avoid this hang out with your friends every week (even if your gf/bf blocks this, override it, it's of utmost important for your mental health)
That's it for now 😊
The moment you've ACTUALLY been waiting for... Introducing Deep Research!
Rolling out now, Deep Research browses hundreds of sites to craft an organized report AND gives you an annotated list of sources for deeper exploration, all of which you can add directly to your notebook.
🐍📰 How to Use Loguru for Simpler Python Logging
In this tutorial, you'll learn how to use Loguru. You'll spend less time wrestling with logging configuration and more time using logs effectively to debug issues.
#python https://t.co/NyumbKm9zm
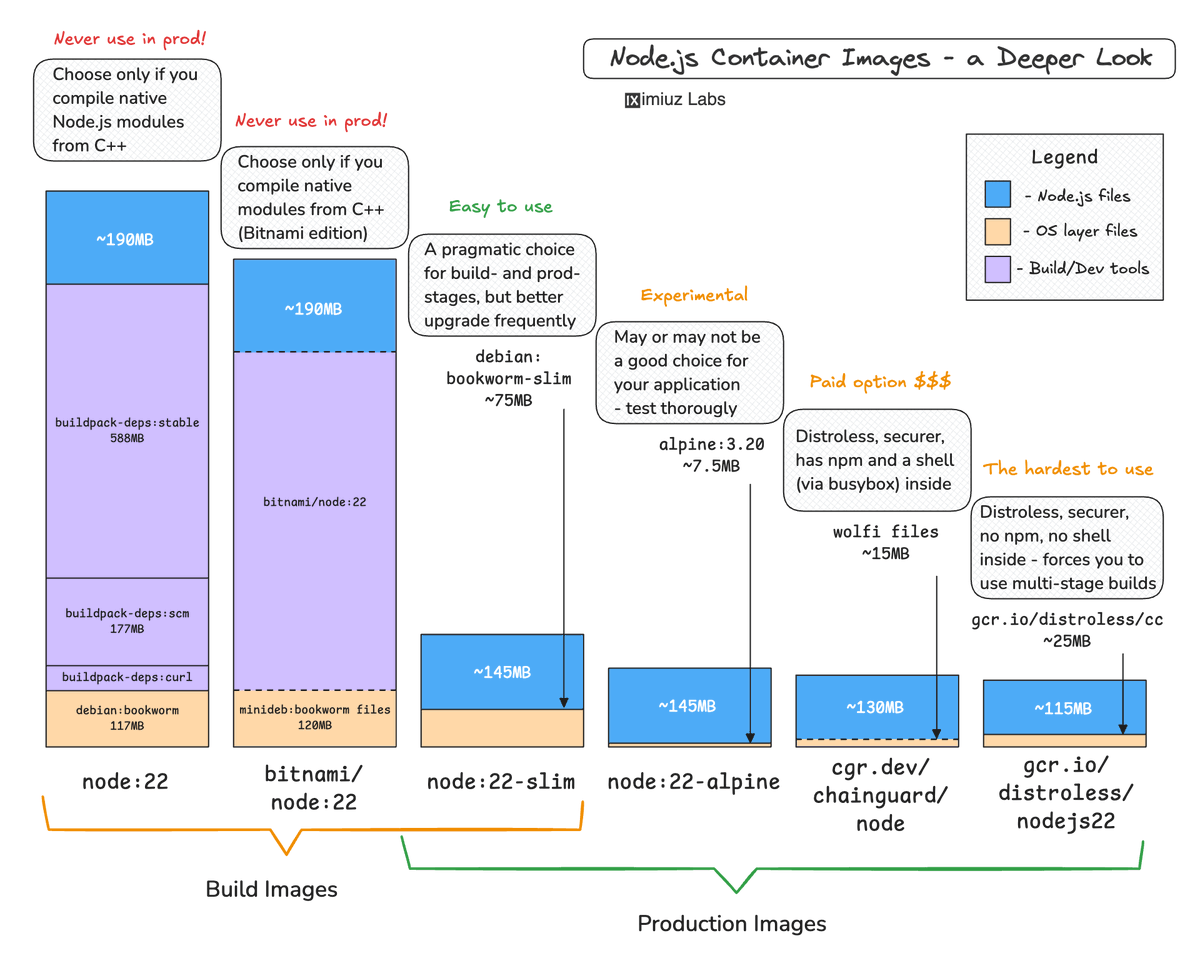
If you want to get rid of those hundreds of CVEs in your container images, the first step is to understand their origin.
Typical sources:
- A "fat" base image
- Forgotten build tools
- Outdated dependencies
Easy solution? A Multi-stage build with a fresh(er) and slim(er) base.
What if you could code an entire app... in Markdown? 🤔
With GitHub Copilot, you can. Write your app's logic in a spec file and let your coding assistant handle the compilation.
The result:
✨ Cleaner specs
⚡️ Faster iteration
🧠 An end to context loss
Discover a new way to build with Copilot. 🚀
https://t.co/e8fhUqoOq6
Automated software testing is growing in importance in the era of AI-assisted coding. Agentic coding systems accelerate development but are also unreliable. Agentic testing — where you ask AI to write tests and check your code against them — is helping. Automatically testing infrastructure software components that you intend to build on top of is especially helpful and results in more stable infrastructure and less downstream debugging.
Software testing methodologies such as Test Driven Development (TDD), a test-intensive approach that involves first writing rigorous tests for correctness and only then making progress by writing code that passes those tests, are an important way to find bugs. But it can be a lot of work to write tests. (I personally never adopted TDD for that reason.) Because AI is quite good at writing tests, agentic testing enjoys growing attention.
First, coding agents do misbehave! My teams use them a lot, and we have seen:
- Numerous bugs introduced by coding agents, including subtle infrastructure bugs that take humans weeks to find.
- A security loophole that was introduced into our production system when a coding agent made password resets easier to simplify development.
- Reward hacking, where a coding agent modified test code to make it easier to pass the tests.
- An agent running "rm *.py" in the working directory, leading to deletion of all of a project's code (which, fortunately, was backed up on github).
In the last example, when pressed, the agent apologized and agreed “that was an incredibly stupid mistake.” This made us feel better, but the damage had already been done!
I love coding agents despite such mistakes and see them making us dramatically more productive. To make them more reliable, I’ve found that prioritizing where to test helps.
I rarely write (or direct an agent to write) extensive tests for front-end code. If there's a bug, hopefully it will be easy to see and also cause little lasting damage. For example, I find generated code’s front-end bugs, say in the display of information on a web page, relatively easy to find. When the front end of a web site looks wrong, you’ll see it immediately, and you can tell the agent and have it iterate to fix it. (A more advanced technique: Use MCP to let the agent integrate with software like Playwright to automatically take screenshots, so it can autonomously see if something is wrong and debug.)
In contrast, back-end bugs are harder to find. I’ve seen subtle infrastructure bugs — for example, one that led to a corrupted database record only in certain corner cases — that took a long time to find. Putting in place rigorous tests for your infrastructure code might help spot these problems earlier and save you many hours of challenging debugging.
Bugs in software components that you intend to build on top of lead to downstream bugs that can be hard to find. Further, bugs in a component that’s deep in a software stack — and that you build multiple abstraction layers on top of — might surface only weeks or months later, long after you’ve forgotten what you were doing while building this specific component, and be really hard to identify and fix. This is why testing components deep in your software stack is especially important. Meta’s mantra “Move fast with stable infrastructure” (which replaced “move fast and break things”) still applies today. Agentic testing can help you make sure you have good infrastructure for you and others to build on!
At AI Fund and https://t.co/zpIxRSuky4’s recent Buildathon, we held a panel discussion with experts in agentic coding (Michele Catasta, President at Replit; Chao Peng, Principal Research Scientist at Trae; and Paxton Maeder-York, Venture Partnerships at Anthropic; moderated by AI Fund’s Eli Chen), where the speakers shared best practices. Testing was one of the topics discussed. That panel was one of my highlights of Buildathon and you can watch the video on YouTube.
[Original text: https://t.co/B1sQ5oDnCU ]