Private AI Search for Law Firms and other highly regulated environments. Speed through data using search - without curation - and use any LLM without lock-in.
Massive test coverage just got free. The new discipline isn't "write tests carefully" ... it's "require tests on everything."
But agents test that their code works, not that you wanted it. Hold the line on system tests!
New post → https://t.co/PJkFNZIJs1
What if you didn't need a vector database?
Most enterprise RAG architectures assume you do. So you build ingestion pipelines. Chunk and embed. Manage stale indexes. Rebuild permissions from scratch. Repeat for every new source.
SWIRL does federated RAG without a vector database.
It reaches your sources at query time: M365, Snowflake, Salesforce, ServiceNow, whatever you have ... retrieves and re-ranks in real time, and delivers AI-ready, permissioned context to any LLM or agent.
No ingestion pipeline. No stale index. Permissions enforced by the source, not approximated in the retrieval layer.
The results are real... a global supply chain team was spending 4+ weeks to produce a weekly status report, pulling manually from Collibra, Oracle, Snowflake, and BigQuery. They deployed SWIRL across all four. No new infrastructure. No data migration. 100% of analyst test questions resolved in under one minute. Self-service.
The vector database was the wrong solution to the right problem.
→ https://t.co/NaNy3j8Uw2
#RAG #VectorDatabase #FederatedSearch #EnterpriseAI #ZeroETL #DataInfrastructure
Team SWIRL is delighted to announce the release of SWIRL Community 4.5!!
This version includes:
* Support for executing RAG with most LLMs and optional LLM instructions
* New MCP server for easy integration with Claude or any MCP client
* New Galaxy UI featuring search history & the return of dark mode
* New admin console featuring bulk editing support for SearchProviders, built-in activity analytics, log viewer, JSON paste support and more!
* Revised source selector now groups sources by tag and shows the tag selected instead of listing the underlying sources
* Updated re-ranking model improves precision and reduces response time
* Improved error handling, especially during AI insight generation
For full details, see the link in the comments... congratulations @SWIRL_SEARCH for this milestone release!!
SWIRL @SWIRL_SEARCH is honored to be listed in the @KMWorld 100 Companies that Matter in KM for the third year in a row!! 🏅🙏 #AI#KM#Legal
https://t.co/Uow6VTtysS
I just recorded a brief video overview of SWIRL AI Legal Search! https://t.co/SLpWkWOvC2
If you're in a law firm and trying to speed through internal data with AI, this is for you.
In the video, I cover:
• Why SWIRL helps firms get answers from internal systems ... fast
• How SWIRL runs privately (not hosted) and does not require ingestion, indexing, copying, or data curation
• How users log in with existing credentials (Microsoft, Ping Federate, etc.)
• How to search across multiple systems and slice through the results
• How AI generates insights grounded in the retrieved documents
• How every insight can be verified via deeplinks to the exact source document and contributing text
No black box. No data duplication. No mystery answers.
Please take a look. I’d genuinely appreciate feedback. Thank you.
Most conversations about AI in the legal industry focus on models. Which one writes better. Which one summarizes faster. Which one drafts the cleanest memo. But that misses the real shift.
The real change is not the model. It's the workflow.
For decades, legal work has been built around information scarcity. Lawyers knew where things lived. Case law databases. Document management systems. Matter files. Email. Internal precedent libraries. Each system held part of the answer. No single system held all of it.
Today, AI can write impressive text. But it still struggles with something far more important: finding the right information across all those systems. If the AI cannot see the key document in your own repository, its answer may sound confident but still be wrong.
That is why retrieval is becoming the real battleground in legal AI.
The firms that succeed will not be the ones running the most AI pilots. They will be the ones that allow AI to search, securely and in real time, across the systems where their knowledge already lives.
When that happens, the role of the lawyer shifts. The AI gathers information from across the firm’s knowledge universe. The lawyer interprets, challenges, and decides.
But there is another twist: every question lawyers ask these systems becomes data. Patterns emerge. What lawyers research. What clauses appear in deals. What risks keep coming up across matters.
In other words, AI systems are not just answering questions.
They are learning from them.
Which raises an interesting thought for the legal profession.
If AI is watching how lawyers search, research, and reason… who is paying attention to who??
Every law firm contains decades of accumulated expertise... briefs that shaped case law, contracts structured with precision, internal analyses that captured hard-earned insight.
Yet much of that knowledge becomes buried over time.
Partners retire. Associates leave. Practice groups evolve. File systems expand. The intellectual capital remains, but it becomes harder to retrieve in context.
SWIRL restores access to that institutional memory. Through federated search and semantic re-ranking, it surfaces prior work not just by keyword match, but by meaning and intent.
That means a junior associate preparing for a motion can discover prior winning arguments. A deal team can identify language used in similar negotiations years earlier. Strategic insight becomes reusable rather than lost.
This is not archival convenience.
Memory preserves competitive advantage.
The legal industry is moving fast into the AI layer. Westlaw has AI. Lexis+ has AI. Each platform is evolving from a research database into an assistant that answers questions, synthesizes cases, and drafts language with confidence.
That progress is real. But here is one thing we can be sure of: Lexis+ is not going to answer questions about Westlaw’s corpus, and Westlaw is not going to answer questions about Lexis’ corpus. They are separate ecosystems with separate content rights, ranking systems, and product strategies.
Now assume something more ambitious. Assume both platforms can integrate with your document management system. Assume they can see your briefs, prior matters, and internal knowledge assets.
Does that solve the structural problem? No.
Because the issue is not access. It is judgment.
Even if both systems can see the same internal content, they remain independent intelligence engines. Each has its own retrieval logic, ranking philosophy, and tuning decisions about what constitutes relevance and authority. Ask the same question in both systems and you may receive two polished, well-structured answers that emphasize different cases and reasoning paths.
At that point, the lawyer becomes the reranker again ... only now comparing AI-generated answers instead of document lists.
We are recreating the federated search problem at the reasoning layer.
The next step is AI federation.
Not replacing vendor AI, but orchestrating across it. A query is interpreted once, retrieval happens across systems, and results are evaluated in a shared context so that everything competes on the same relevance scale. Judgment happens above the silos instead of inside them.
In a world with two dominant legal research platforms, each with powerful AI, you are going to need one AI to work with them all.
We solved federated retrieval. The next challenge is federated reasoning. In legal practice, that won’t be a feature. It will be infrastructure.
Legal research should not start with a scavenger hunt.
Today SWIRL added support for two major public legal archives:
🇬🇧 The National Archives Caselaw (UK)
🇺🇸 CourtListener (US)
Now SWIRL can search and re-rank results across these sources alongside the rest of your enterprise knowledge, with optional AI insight generation using your choice of LLM.
No new index. No copying the data. Just connect and search.
For lawyers, researchers, and compliance teams, this means faster access to precedent across jurisdictions.
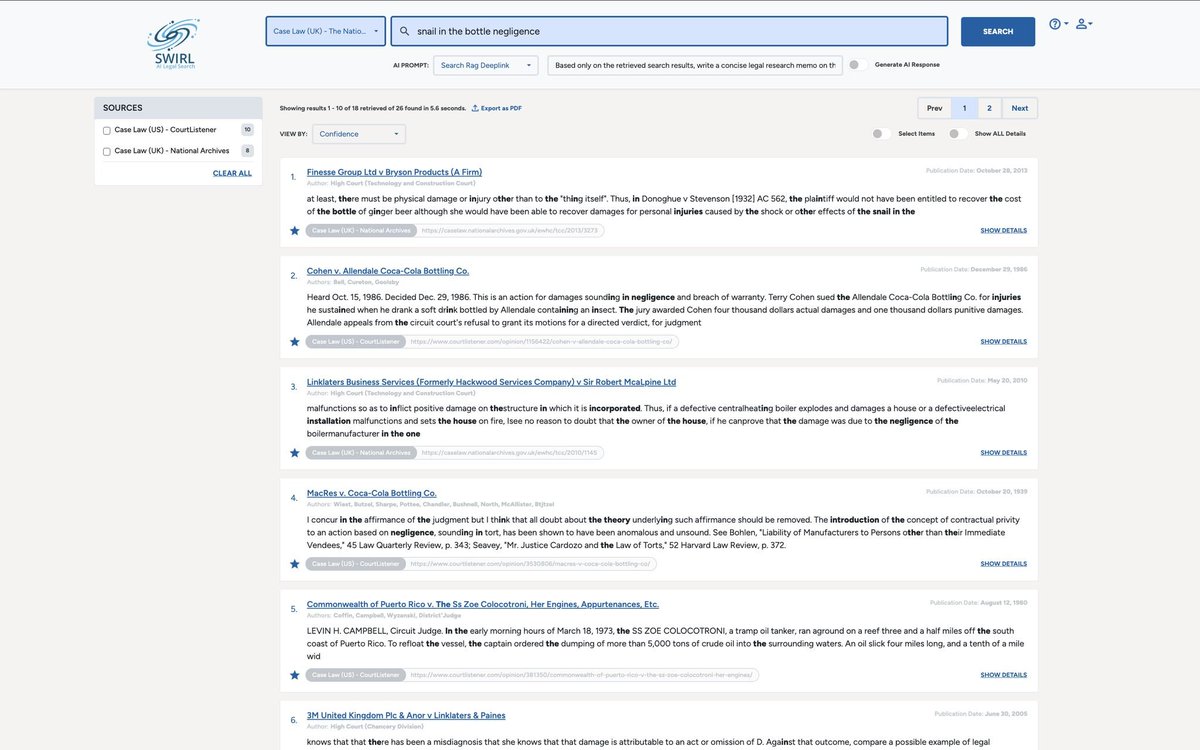
The screenshot below shows SWIRL in action on these sources looking for "snail in a bottle negligence" ... ping me for a live demo anytime!!
Modern AI systems get most of the attention today.
But one of the most important ideas behind modern search came from a paper written more than fifty years ago.
Karen Spärck Jones introduced a simple but profound insight in 1972: the importance of a word depends on how rare it is across documents.
She described it this way:
“The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs.”
That idea became Inverse Document Frequency (IDF).
In practice, it means something very intuitive... common words carry little meaning. Rare words carry much more.
When a search system ranks documents, terms that appear everywhere should matter less than terms that appear only in a few places. IDF captures that principle mathematically.
From that insight came TF-IDF, one of the foundational ranking methods in information retrieval. Later models such as BM25 refined the approach, but the core idea remains the same.
Even today, many systems, from enterprise search platforms to modern retrieval pipelines that support AI applications, still rely on variations of this concept.
The machinery under the hood.
Karen Spärck Jones helped explain which information actually matters when we search. Her work shaped how computers retrieve knowledge from large collections of documents ... something that professionals in fields like law rely on every day.
In an era focused on AI breakthroughs, it is worth remembering that some of the most durable ideas in computing come from elegant insights developed decades ago.
Inverse Document Frequency is one of them.
https://t.co/tKM1hNgn5o
After I posted the SWIRL demo video, people asked questions:
Which LLM is it using? Can you switch models? Does SWIRL include a chat interface? I thought it would be useful to answer a few of those questions here.
Q: Why does the demo show OpenAI?
A: The AI insights in that video were generated using OpenAI GPT-4.1 deployed in SWIRL's Azure tenant. But SWIRL itself is not tied to any specific model or provider. It can work with capable LLMs from most major vendors.
Q: How easy is it to switch LLMs?
A: Very easy. SWIRL comes with preloaded configurations for OpenAI, OpenAI on Azure, Anthropic, AWS Bedrock, Google, Ollama, and others. Connecting a model is straightforward: put in API key, activate it, assign it a role (rag, chat, etc), and start asking questions!
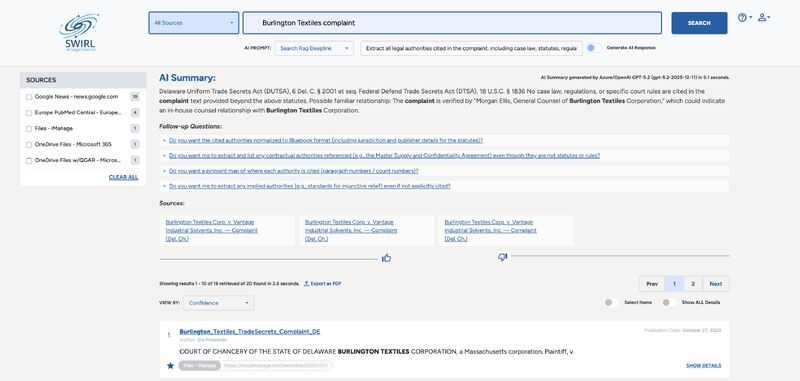
(See attached screen shot of SWIRL with OpenAI GPT-5.2, again running privately in Azure.)
Q: Can we tune how the LLM summarizes the data?
A: Yes... and this step turns out to be critical in real deployments. SWIRL allows teams to provide the LLM with context about what lives in each source and how it should be queried. Organizations can also encode internal standards, workflows, and review practices so the summaries reflect how the business actually operates. For example, a legal team might define the exact review steps required for a contract and make those part of the AI’s reasoning process.
Q: Do I have to use the SWIRL UI?
A: No. While SWIRL includes its own interface and Search Assistant, it’s not required. SWIRL exposes APIs for search and AI workflows, including an MCP server for agentic integrations. We also support plug-ins to popular front-ends such as Microsoft 365 Copilot, ChatGPT and others, allowing organizations to bring SWIRL’s search and retrieval capabilities directly into the environments where users already work.
If you're experimenting with enterprise AI search or evaluating different LLMs inside your organization, I’d be interested to hear what models you’re testing.
If AI Can’t Show Its Work, It Doesn’t Belong in the Firm!
Your litigators would *never* file a brief without citations.
Yet many firms are piloting AI systems that produce elegant prose with no verifiable foundation.
“Trust the model” is not a governance strategy.
SWIRL forces traceability. Ranked sources. Clickable documents. Exact passages used in generation.
That means your attorneys can verify before they rely. Perfect.
In the AmLaw 100, reputation is capital.
AI that cannot be examined is a liability. AI that can be audited becomes an asset.
Law firms are structured around necessary boundaries... practice groups, matter numbers, ethical walls, jurisdictional separations. Those controls exist for client protection and regulatory compliance.
But knowledge does not naturally confine itself to those boundaries.
The challenge is enabling discovery across the firm without dismantling governance.
SWIRL respects native permissions automatically, allowing attorneys to surface relevant precedent across systems while enforcing access rules in real time. Users only see what they are authorized to see. Nothing more.
From the moment you integrate it with the systems you use, like M365 and iManage.
This enables pattern recognition across matters. It surfaces similar negotiation language from other engagements. It identifies related litigation strategies. And it does so without centralizing sensitive data into a single vulnerable repository.
Strategic visibility. Governance intact. Lovely!
That combination is what modern legal AI should deliver!
Starting to worry that legal AI is heading toward a predictable wall... not because the models aren’t good enough.
But because of the assumptions we’re quietly making underneath them.
Assumption #1: Speed matters more than architecture.
If we can deploy a hosted AI solution in weeks, that’s better than taking months to get the infrastructure right. After all, innovation favors the fast.
Maybe. When client data, matter strategy, and privileged communications are involved, architecture isn’t a technical detail. It’s the product.
Assumption #2: Re-indexing everything is inevitable.
Of course we need to copy documents into a new system. Of course we need to build another searchable corpus. That’s just how AI works.
Is it? Or are we accepting data sprawl and permission reinterpretation as the cost of convenience?
Assumption #3: AI governance can be layered on later.
Let’s pilot broadly. We’ll figure out auditability, LLM controls, and risk oversight once lawyers love the interface. That sounds efficient... until a client asks exactly how their data was handled.
I’m not arguing against AI adoption. Quite the opposite. The firms that get this right will gain real leverage.
But I do think we need to separate “AI that demos well” from “AI that survives scrutiny.”
Legal has never rewarded surface-level solutions. It rewards defensible ones. #Legal #AI #LLMs
Law firms don’t have an AI problem. They have a data architecture decision to make.
In a profession built on privilege, confidentiality, and regulatory accountability, the structure of your data environment determines how safely and confidently you can innovate. Architecture isn’t plumbing. It’s strategy.
Here are five hard truths about Data Architecture for Legal Industry Leadership.
1. In legal, architecture is compliance.
Compliance is not a wrapper around the business model; it is the business model. That means access controls, ethical walls, retention policies, and auditability must be enforced by design. Architectures that allow intelligence to operate across systems using existing permissions, rather than copying sensitive content into new centralized stores, align far better with how law firms manage risk and client trust.
2. Privacy and AI must share the same foundation.
AI experimentation is accelerating, but in legal, scale only works if privacy scales with it. Every time data is extracted, replicated, or re-indexed into another platform, governance becomes more complex. A federated approach, where systems connect securely to repositories and respect native controls, reduces duplication and keeps the privacy model intact while still enabling insight.
3. Search is governance made practical.
Legal organizations depend on finding precedent and prior work product quickly, but only within strict permission boundaries. Modern architectures can unify search across distributed repositories while enforcing document-level security in real time. Re-ranking and reasoning across results without ingesting all underlying data reflects a model that enhances visibility without weakening control.
4. AI amplifies your architectural choices.
If your foundation respects data boundaries, ownership, and permissions, AI strengthens those structures. If it requires bypassing them, risk increases. Distributed, permission-aware architectures where intelligence comes to the data (rather than the other way around) are better suited to regulated environments where trust and defensibility matter.
5. Leadership must choose the architectural philosophy.
The key question isn’t which AI model to deploy; it’s whether your architecture preserves client trust as capability expands. Approaches built on secure federation and minimal data duplication allow firms to innovate without creating new silos or compliance blind spots. In legal, the firms that move fastest will be the ones whose architecture lets them move safely.
I read a recent post by the CEO of yet-another-vector-database company - this one positioned in legal search.
"Ingest everything, get insight" more or less.
It’s well written. And it’s also stuck in a pre-LLM mental model of what federated search is ...and what it can be.
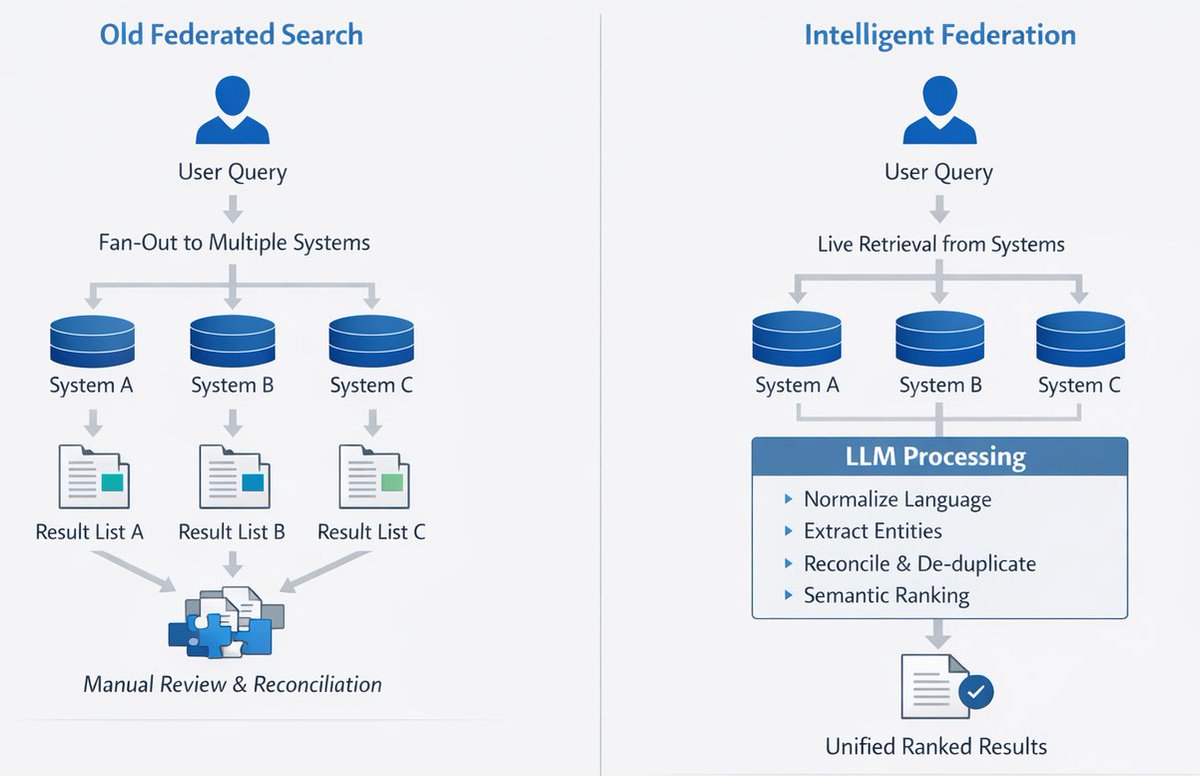
The core claim is that federated search is “fundamentally limited” because it fans a query out to multiple systems and hands the user fragmented results. That was a fair criticism ten years ago... But it’s no longer true, thanks to LLMs.
Let’s start with common ground.
In the past, federated search meant aggregation without understanding. You ran a query, got a grab bag of results... and you had to do the hard work.
Deduplicate. Reconcile versions. Decide what mattered.
It still saved time. There are many examples of successful federated engines - like Solcara, better known as TR LegalSearch Connect. But the limits were real, and the criticism reasonable.
Here’s where their argument breaks down... in assuming the only way to fix fragmentation is to centralize everything into a single unified index. That assumption may have been true at one time. Today, it is simply wrong.
Worse, it’s backwards.
Because the new reality is this.. Federated search is exactly what winning approaches do now.
Modern AI agents don’t start by building massive indexes. They retrieve data - live, across systems, and in real time... and then reason. Again: they fan out queries, pull back evidence, reconcile conflicts, and rank results after retrieval.
That’s federation. Intelligent federation.
What finally makes federation work isn’t generation. It’s understanding. And that’s exactly what LLMs are good at.
Think about the data law firms deal with every day:
* A half-finished Teams or Slack exchange
* A document buried in iManage
* A “know-how” memo in SharePoint
* A cited case from a commercial publisher
* An internal summary saved years ago
Pre-LLM, stitching that together was hard. Today, stitching is exactly what LLMs do! Across languages, domains and more.
Not to generate answers... but to:
* Interpret different formats
* Normalize language and intent
* Recognize related material
* Reconcile versions and overlap
* Rank by meaning, not source
None of which requires a single index. Instead, it requires context. A centralized index doesn’t create context. It creates drag:
* Re-indexing
* Duplicated security models
* Stale data
* Broken permissions
* Ingestion delays
And that’s not even considering the work and expense involved in centralization projects! Keeping permissions straight across system. Handling near-duplicates. Applying taxonomies and ontologies. Keeping it all in-synch with the source systems.
To say nothing of the potential compliance risks of co-mingling data from different sources, departments, or potentially licensed under different terms, into a single repository.
Live federation plus LLM-driven understanding solves the real problem: making sense of distributed knowledge as it exists right now, not as it was copied last night.
The post also argues that enrichment, linking, and entity extraction are impractical without a unified index. That might have been true when AI meant brittle pipelines and batch jobs. It isn’t true now. Modern LLMs can:
* Classify documents at query time
* Extract entities on demand
* Link concepts across systems
* Re-rank consistently after retrieval
* Respect source-level permissions
The “connective tissue” no longer lives in an index. It lives in the data itself. The model understands that.
Law firm data is fragmented. It always will be. But the conclusion that you can’t work effectively without centralizing everything is yesterday’s answer to today’s problem.
You don’t need to curate your way out of the mess. You don’t need to copy your data into a monolithic index. With LLMs, you can finally work with it. In place. Without the overhead and security risks of centralization.
Is it really that simple?
Yes, it is.