Fed Chair Powell: I'm literally staying because of the actions that have been taken. I had long planned to be retiring. The things that have happened in the last 3 months have left me no choice but to stay until I see them through
Today I feel very proud and am honored to introduce PrismML.
This company grew out of years of research at Caltech and a simple conviction: the future of AI will not be defined only by ever-growing models. It will be defined by intelligence density - how much useful intelligence we can deliver per unit of compute, memory, and energy.
At PrismML, we seek to build the most concentrated form of intelligence. Our first proof point is the 1-bit Bonsai family: models that are small, fast, and efficient enough to run locally, while remaining competitive with full-precision models in their class.
We see this not as an endpoint, but as the beginning of a new paradigm for AI, one that expands where intelligence can exist: on-device, at the edge, in the cloud, and in entirely new products and systems.
We are excited to begin sharing that vision.
I was fired from Block today. I was the PM in charge of changing the default tip option on the Square terminal to start at 40%.
Jack replaced me with an AI agent that decides which tip amount to show based on your age, weight, and race.
If anyone is hiring product managers, please let me know!
Fantastic job by @DimitrisPapail! Two hypotheses:
- Harder benchmarks likely have high variance and tricky to predict (like many models achieve near zero).
- Expensive benchmarks with more problems may be more predictable due to finer difficulty granularity (so scaling laws show up).
This makes IMO 2025 hardest to predict as actually observed :)
Our paper "SmartChunk Retrieval: Query-Aware Chunk Compression with Planning for Efficient Document RAG" is accepted at #ICLR2026 🎉
Static chunks fail for long docs,Let the model decide. We make chunking a reasoning problem, introducing STITCH, a new RL↔SFT post-training loop
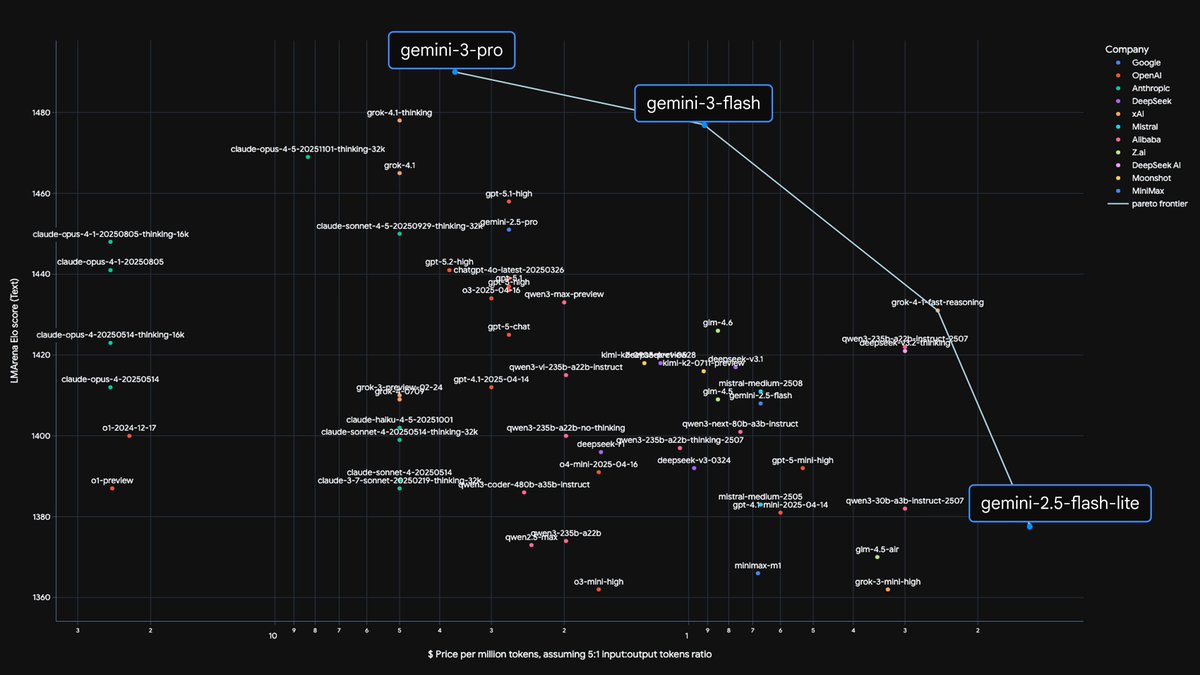
We’ve pushed out the Pareto frontier of efficiency vs. intelligence again.
With Gemini 3 Flash ⚡️, we are seeing reasoning capabilities previously reserved for our largest models, now running at Flash-level latency. This opens up entirely new categories of near real-time applications that require complex thought.
It’s available in the API, and rolling out today as the default model in AI Mode in Search and Gemini app globally.
Read more on the blog at: https://t.co/Uw9bmlJvhI
More in thread ⬇️
I’m really excited about our release of Gemini 3 today, the result of hard work by many, many people in the Gemini team and all across Google! 🎊
We’ve built many exciting new product experiences with it, as you’ll see today and in the coming weeks and months.
You can find it today on @GeminiApp and AI Mode in Search. For developers, you can build with it now in @GoogleAIStudio and Vertex AI.
https://t.co/KRV0xzniBY
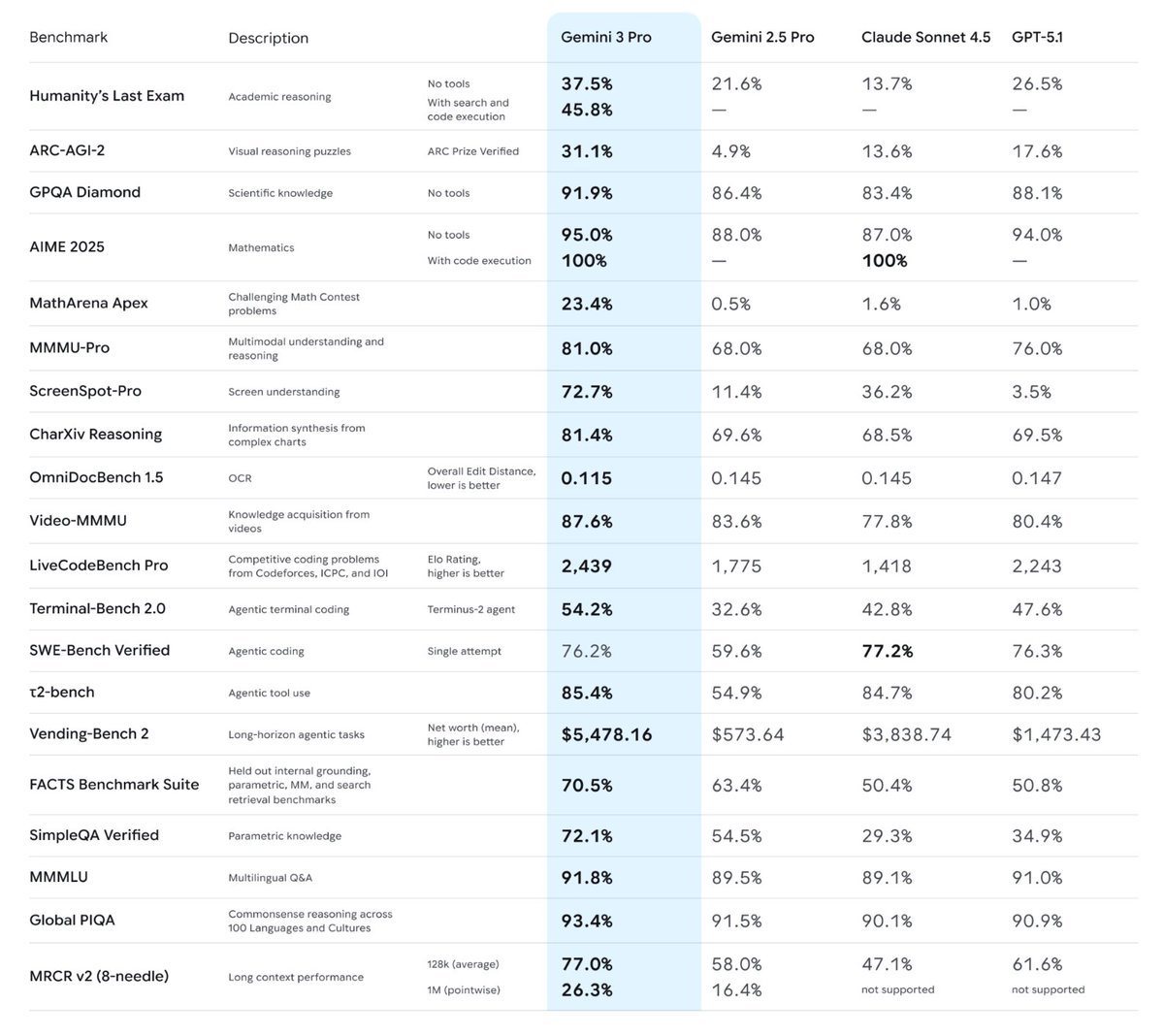
The model performs quite well on a wide range of benchmarks.
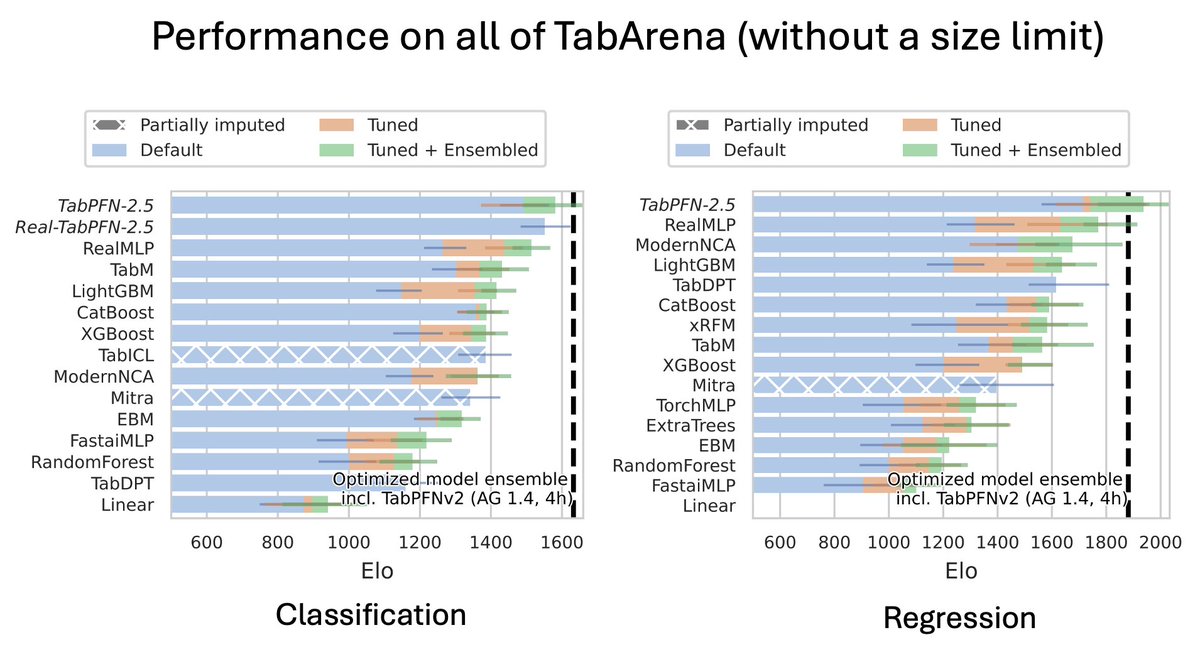
Update: TabPFN-2.5 is actually the SOTA model on all of TabArena (which has datasets with up to 100k training data points).
In a single forward pass, TabPFN-2.5 outperforms all other models, even if you tune them for 4 hours.
We built and previously evaluated TabPFN-2.5 for up to 50k data points (and 2k features) and were kind of surprised that it's SOTA up to 100k 🙂
👉 TabPFN-2.5 webinar tomorrow: https://t.co/Pcn4YdyPjE
👉 Model report on arXiv: https://t.co/RqhUylWurQ
(1) Our team at @GoogleDeepMind has been collaborating with Terence Tao and Javier Gómez-Serrano to use our AI agents (AlphaEvolve, AlphaProof, & Gemini Deep Think) for advancing Maths research. They find that AlphaEvolve can help discover new results across a range of problems.