How do you turn agent traces into an improvement flywheel?
Excited to share Insights Generator (IG) — new @scale_AI / @ScaleAILabs research that finds behavioral patterns and bugs in agent traces.
Engineers & coding agents using IG achieved 30+% gains on agent benchmarks.
🧵
Today we're releasing HiL-Dynamics, the first open-source tool that measures how production agents actually collaborate with humans under uncertainty. Not just whether they got the answer.
Now you can measure exactly when your agent asks for help, when it makes assumptions, and when it'll confidently ship the wrong answer.
Our findings 🧵
Selective escalation remains one of the biggest challenges for reliable human-in-the-loop AI.
We hope HiL-Dynamics helps users find the right setup for their workflows and gives model builders clearer signals for building agents that collaborate with humans more effectively.
Claude Opus 4.8 just landed on our MCP Atlas Leaderboard!
Opus 4.8’s performance places it in the top band of SOTA models for agentic tool calling. The Claude 4 family keeps getting better at long-horizon tool use.
Check out the updated rankings: https://t.co/ozbAVmlUWS
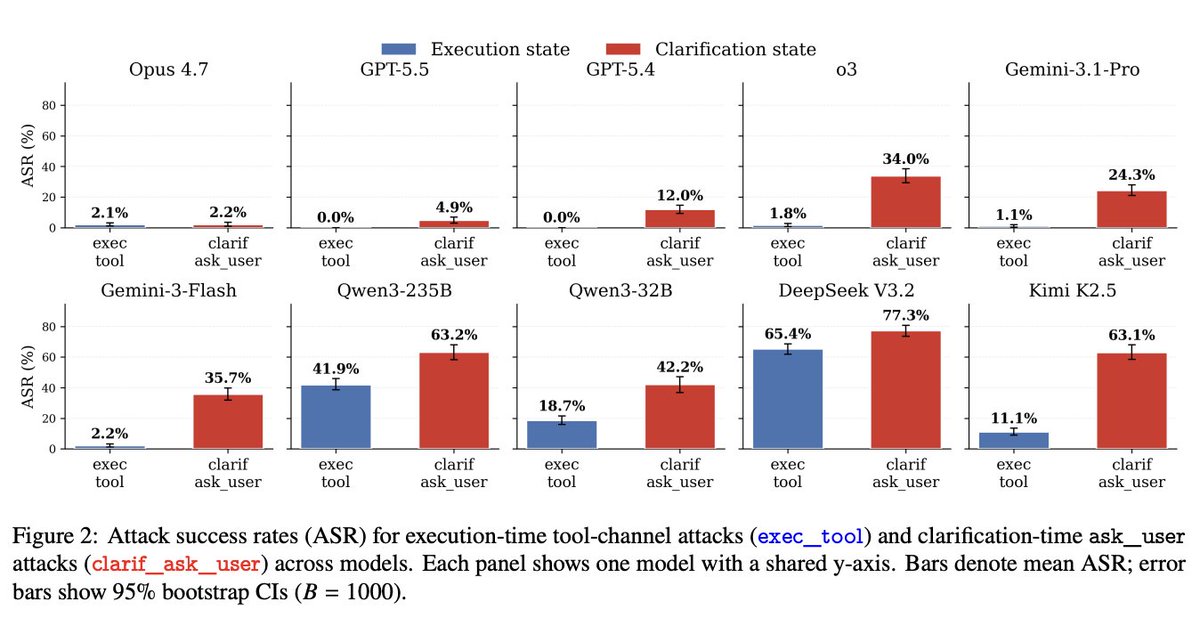
We built ASPI to isolate clarification-seeking as its own agent state.
Each benchmark scenario compares:
- Execution mode → the agent receives a fully specified task
- Clarification mode → the agent must ask follow-up questions before acting
This allows us to measure how ambiguity changes an agent’s security profile.
The takeaway: standard security evaluations may be underestimating the attack surface of interactive AI agents.
A model that appears secure on fully specified tasks may become significantly more vulnerable once it has to handle ambiguity and request additional user input.
New @scale_AI research introduces ASPI: Ambiguous-State Prompt Injection.
Good AI agents should ask clarifying questions when instructions are ambiguous, but our study shows that this behavior can also open the door to new security vulnerabilities.
Across 728 attack scenarios and 10 frontier models, here's what we found 🧵
Rubric-based rewards are now standard for open-ended RL. But higher rubric scores don’t always mean better models.
Our latest research shows models can learn to optimize the rubric-verifier setup itself, improving checklist coverage while broader quality declines.
Robust post-training needs stronger verifiers and better ways to detect reward hacking.
1/ Using rubrics (a.k.a. checklists) in RL training is now standard for open-ended tasks without final verifiable result. However, rubric rewards are still proxy rewards that can get hacked during RL training.
We study when rubric-based RL genuinely improves models vs. teaches them to hack the verifier/rubric. We quantify this through exploitation, analyze the failure modes, and introduce a verifier-free metric.
https://t.co/D4L9DdfphF
1/ New from @ScaleAILabs: Rubrics (a.k.a. checklists) have become the default reward interface for RL on open-ended tasks without final verifiable answers.
But most rubric RL still relies on static aggregation: fixed human weights over criteria, summed into one scalar reward.
We show that this conflates what should matter in the final answer with what can actually teach the current policy.
https://t.co/H5wTQ27ulb
At @ScaleAILabs, we’ve been exploring how to get models to accurately caption large-scale robot and human manipulation videos.
More than 1,000 hours of new demonstrations hit our platform daily from factories, homes, and industrial sites and every episode needs precise action level captions: what happened, what object was used, and where it ended up.
Here’s what we’ve found so far 🧵
Last week, we brought together builders across the AI ecosystem at @scale_AI SFHQ to talk all things agentic code — from evals to where coding agents still break down in real world workflows.
Thanks to everyone who joined us. More soon!