Veo 3 is here, and in addition to better visuals, it makes noises and speaks! This was a massive effort made possible by incredible passion from the whole Veo team and the many other team enabling it to launch today.
Looking forward to seeing what others do with it!
#veo3
Veo 3, our SOTA video generation model, has native audio generation and is absolutely mindblowing.
For filmmakers + creatives, we’re combining the best of Veo, Imagen and Gemini into a new filmmaking tool called Flow.
Ready today for Google AI Pro and Ultra plan subscribers.
We're sharing progress on our video-to-audio (V2A) generative technology. 🎥
It can add sound to silent clips that match the acoustics of the scene, accompany on-screen action, and more.
Here are 4 examples - turn your sound on. 🧵🔊 https://t.co/VHpJ2cBr24
It's so awesome to see the impact of the computational audio capabilities we developed featured in
@madebygoogle 🎉 🎉 🎉
Congrats to John Hershey, @ScottTWisdom, @PGetreuer & everyone who contributed for pioneering new computational audio capabilities in Pixel8 #MadeByGoogle
Here is a short presentation of AudioScopeV2!📢 @ScottTWisdom and I are looking forward to discussing further about open-domain on-screen sound separation and meeting you in #ECCV2022!
webpage:https://t.co/tnFj8h2vSU...
arxiv:https://t.co/Xl8MyGN44c
video:https://t.co/lRb19rp34N
I am 😃 that we will present AudioScopeV2 at #ECCV2022! If you want to learn about improved audio-visual attention models and calibration for on-screen sound separation check our paper w. @ScottTWisdom!
project-page: https://t.co/56xex144Qx
new dataset: https://t.co/26F3UgkJ4P
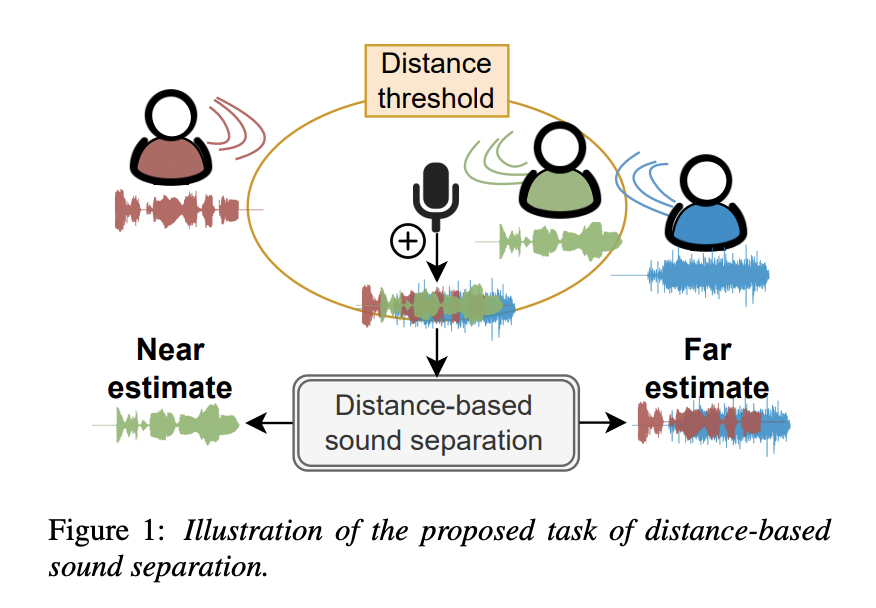
Distance-Based Sound Separation
abs: https://t.co/FMb1QKgibn
project page: https://t.co/a29MkM7qpO
With a single nearby speaker and four distant speakers, the model improves scale-invariant signal to noise ratio by 4.4 dB for near sounds and 6.8 dB for far sounds
Happy to see my summer work with @ScottTWisdom, Hakan Erdogan, and John Hershey was accepted for presentation at @ieeeICASSP 2022 😊 My first ICASSP paper in the books! Immensely thankful for their mentorship. Our first version can be found on arXiv at: https://t.co/xZ0BL7znaN
We can learn a lot about our environment just by listening to the birds. New #GoogleAI approaches can help isolate and identify birdsongs, helping ecologists better understand food systems and forest health. 🐦
https://t.co/Va9kjPTHRj
Our paper received a #WASPAA2021 special award for *Best Audio Representation Learning Paper*: "Self-Supervised Learning from Automatically Separated Sound Scenes". 🎉🚀
paper: https://t.co/NvEhyI8BzE
talk: https://t.co/TD2x6Gs9b8
slides: https://t.co/U0LcbcgjfC
👇
🔊Here's the video presentation of our WASPAA21 paper: "Self-Supervised Learning from Automatically Separated Sound Scenes". Work done during an internship at Google Research.
paper: https://t.co/NvEhyI8BzE
video: https://t.co/TD2x6Gs9b8
slides: https://t.co/U0LcbcgjfC
🔊Happy to announce FSD50K: the new open dataset of human-labeled sound events! Over 51k Freesound audio clips, totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology.
Paper: https://t.co/fn5NSsdkgy
Dataset: https://t.co/DmeCDQj6yW
I am thrilled to announce that our paper "Unsupervised Sound Separation using Mixtures of Mixtures" got accepted to #NeurIPS2020 as a #Spotlight paper!! 📢📢 All kudos to @ScottTWisdom and the rest of the Google guys! https://t.co/2nbGkjNABI
I'm a bit late posting this, but a very cool paper from Scott Wisdom and collaborators (including @ETzinis) out of Google introducing "MixIT": https://t.co/9FVhFwntL6
They tackle the problem of *unsupervised* source separation! 1/10