@pfau@FrnkNlsn Finally, it happened!! :D I wrote one of the papers citing your old version. Maybe, interestingly for you, I provided the bvd in the dual space, and also for functional cases https://t.co/nNtTJxF2dc
Looking forward to any discussions about kernels, uncertainty, bias-variance decompositions, or my other research: calibration!!
See you on Wed 24 Jul 11:30 a.m. CEST at Hall C 4-9
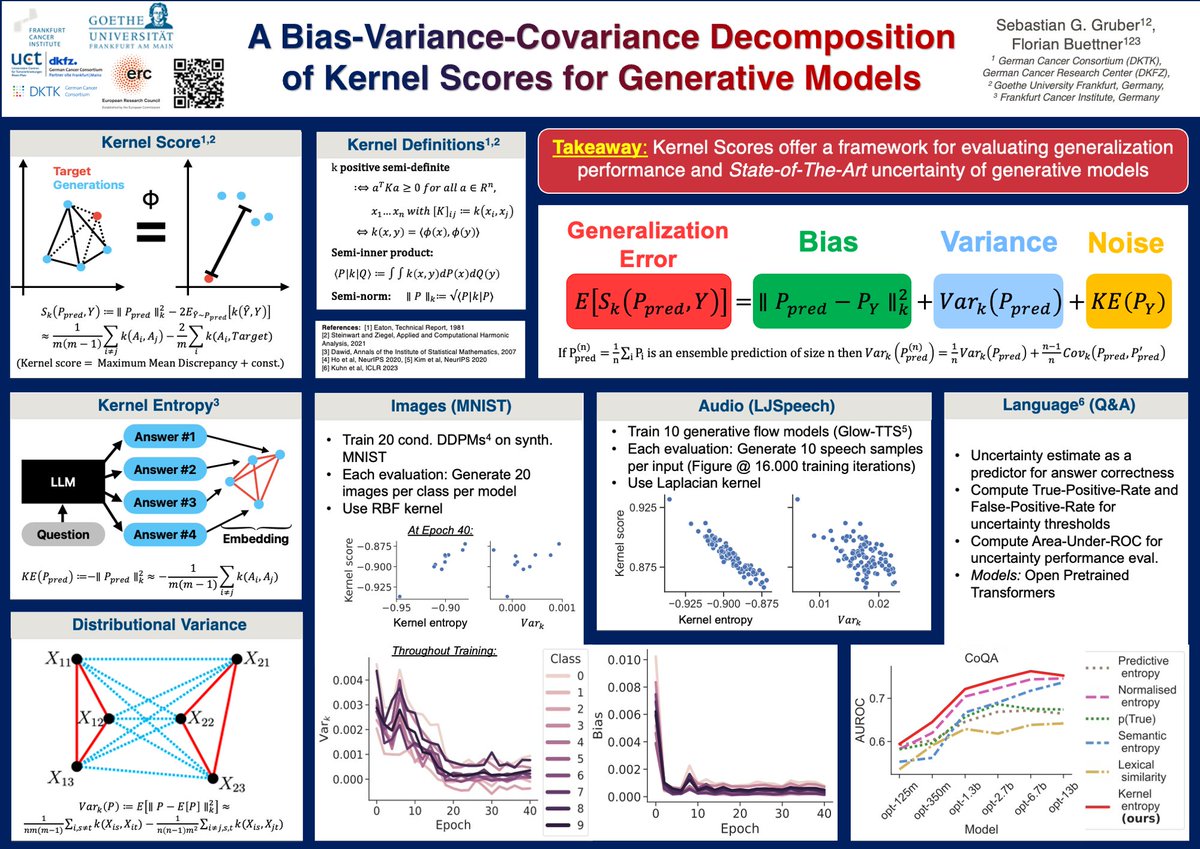
28 years ago the bias-variance-covariance decomposition of the mean squared error was introduced.
This week at @icmlconf, @BuettnerFlo and I will show that it also holds for kernel-based loss functions, which we use for image, audio, and language generation experiments...
The decomposition represents a framework for understanding generative models' generalization performance and uncertainty. Specifically, we outperform other baselines of uncertainty in predicting the answer correctness of LLMs
https://t.co/VwfwwyX9zt
@BlackHC In my experience, minimal changes to the optimization procedure can have major effects on the TS results. It is difficult to pinpoint the issue without toying around with the implementation.
@profgavinbrown@csmcr @RiccardoAli1 Conditionally yes. If you have parametric proper scores then you have a bijection to NLL expfam and bregman divergences. However, proper scores are also defined for non-parametric distributions. That's why we had to use functional bregman divergences in the paper
Today at #AISTATS24@SebGGruber, @dr_alex_tiulpin and I are presenting our work on “Consistent and Asymptotically Unbiased Estimation of Proper Calibration Errors”. You can find us from 15:00 to 17:00 @ MR1 #31 ☺️
Paper: https://t.co/oT6PaIkYFd
Code: https://t.co/nKFxlHOcMN
@HyperboIeva To give a (non-physical) example where a non-inner product dual space is critical:
We use them to perform a bias-variance decomposition of a general loss function for distributions https://t.co/Eoao5966Z1
@iScienceLuvr If you are interested for more, the MMD can also be used for other tasks, like audio and text generation. There even exists a bias-variance-covariance decomposition for it via kernel scores (=MMD + const) https://t.co/Ry0gZfngwE
@iScienceLuvr I highly enjoy that the MMD is used more for generative models. However, as mentioned in the paper, the KID already uses the MMD of feature embeddings. So, it would be interesting to have an ablation study of the kernel choice and embedder choice. The paper only evaluates FID
@DrHughHarvey @StanfordHAI Non-determinism is vital for the uncertainty estimation of LLMs (https://t.co/Ry0gZfngwE).
You can always increase the determinism by adjusting the sample temperature, however this also adjusts how certain the model is in its answer.
@Jeffaresalan@JonathanICrabbe@tennisonliu@MihaelaVDS Interesting work, Alan! You stated that averaging probabilities 'is a more natural strategy' than averaging scores. I agree, but if you want to minimize the CE loss without touching the bias then there is no way around averaging scores (c.f. Cor.3.6 in https://t.co/Eoao596EOz)
@bryancsk In the first book, yes. However, in the sequels, the author goes into great detail about how technology threatens the existence of every neutral actor. Ironically, the only safe solution in the books is to isolate yourself into a bubble of no progress for eternity
@BlackHC@ilyasut "allowing the company to be destroyed 'would be consistent with the mission'" ?!?!
Does not seem like a sustainable mindset from a stochastic process perspective. You only have to slip once into the impression of 'kill the company' and it's over.
@predict_addict Note that they don't cite that kernel density ratio estimation has already been done for the ECE in https://t.co/NsZf42og4H and https://t.co/qjwCsCKWr9
They also claim canonical calibration is infeasible even though unbiased+consistent estimators exist https://t.co/Son8B41qOO