Super happy and honored to have been awarded an ERC Consolidator Grant for my project TAIPO. In TAIPO (not a typo!), we'll develop trustworthy AI tools for personalized oncology to help narrow the gap between the AI bench and the bedside. @DKFZ@DKTK_@goetheuni @FCI_health
1/2
📢 The results of the 2022 ERC Consolidator Grant competition are out: €657 million for 321 researchers.
Who has been offered funding?
What topics they will investigate?
Where will they do their research?
Discover the details ➡️ https://t.co/MYLZWZ5JSv
🇪🇺#EUfunded#ERCCoG
We’re hiring a Junior Group Leader - AI in immunotherapy - to join our team at the earliest possible date. The position is embedded within my Chair and the Chair of Cellular Immunotherapy (Michael Hudecek), and connected to CAIDAS center for AI.
https://t.co/ddYiddvUi8
🚀 new preprint with @lukasgradient and @gserpep: we introduce a novel *non-contrastive* approach for vision-language alignment. Without all the engineering complexities that come with contrastive learning, NOVA is more stable and excels on small medical imaging tasks! Details👇
Introducing NOVA — Non-Contrastive Vision-Language Alignment!
We show you don't need negative sampling, momentum encoders, or stop-gradients to align vision and language.
Just predict text embeddings from image views + one simple regularizer (hint: it's by @ylecun & @randall_balestr).
🧵👇🏼 1/n
Hi everyone,
If you like @scikit_learn, how about upvoting my request to add it to the LinuxFoundation insight board:
https://t.co/6SsDiT7NW3
Thanks 🧡💙
Small models as the new frontier and why this may be academia's LLM moment
Academia should reject the nihilism of "scale is all you need", i.e, that meaningful research requires frontier scale compute. This mindset hurts basic research and what we can contribute to machine learning in practice.
Many interesting questions about architectures, data, and training methods do show signal and can be tested at the O(100M) to O(1B) parameter scale within reasonable budget. There seems to exist no fundamental reason why these insights wouldn't transfer and hold up to 14B, 32B, or even larger models. Yes, there will be trends and observations that break at the trillion parameter scale, but my conjecture is that this will be irrelevant for the majority of models people will actually deploy locally in the future.
The economics of post-training (SFT/RL) are finally favorable for academia. Post training a 7B model fits on a single H100 GPU, which roughly $3/hour on cloud providers. You can train on 100M+ tokens for under $100.
Why care about mid/post-training? That's where a lot of interesting problems are! Reasoning, tool use, specialization, etc, these are settings where you see meaningful performance improvements and skills learnt within millions of trained tokens, not billions, that are typical for pretraining.
More importantly, the 4B-32B parameter range will likely dominate local deployment in the not so distant future. These models fit on reasonable hardware (a beefy laptop) as inference requires enough RAM to fit the model, but you can use without GPUs for single batch inf calls. Also these models, at that scale, are getting seriously good for tasks likecoding, math, tutoring, computer use etc.
So here is my conjecture: local models at the <100B scale will eventually generate more tokens/day than api-hosted frontier models.
This may be academia's moment! The open-weights ecosystem provides a path to real impact without million-dollar GPU clusters at this scale.
Our research can directly study, understand, and improve the 99% of models that will run locally, not the 1% that require data centers. This is finally both possible and meaningful. Don't be discouraged by scale maximalism!!
Last day to submit an abstract or register for the MOPRED Symposium on the 8.10. at @goetheuni about advances in multi-modal data integration and their applications in biomedicine. Keynote by @ewa_szczurek
Register here:
https://t.co/FCeWQFsUdD
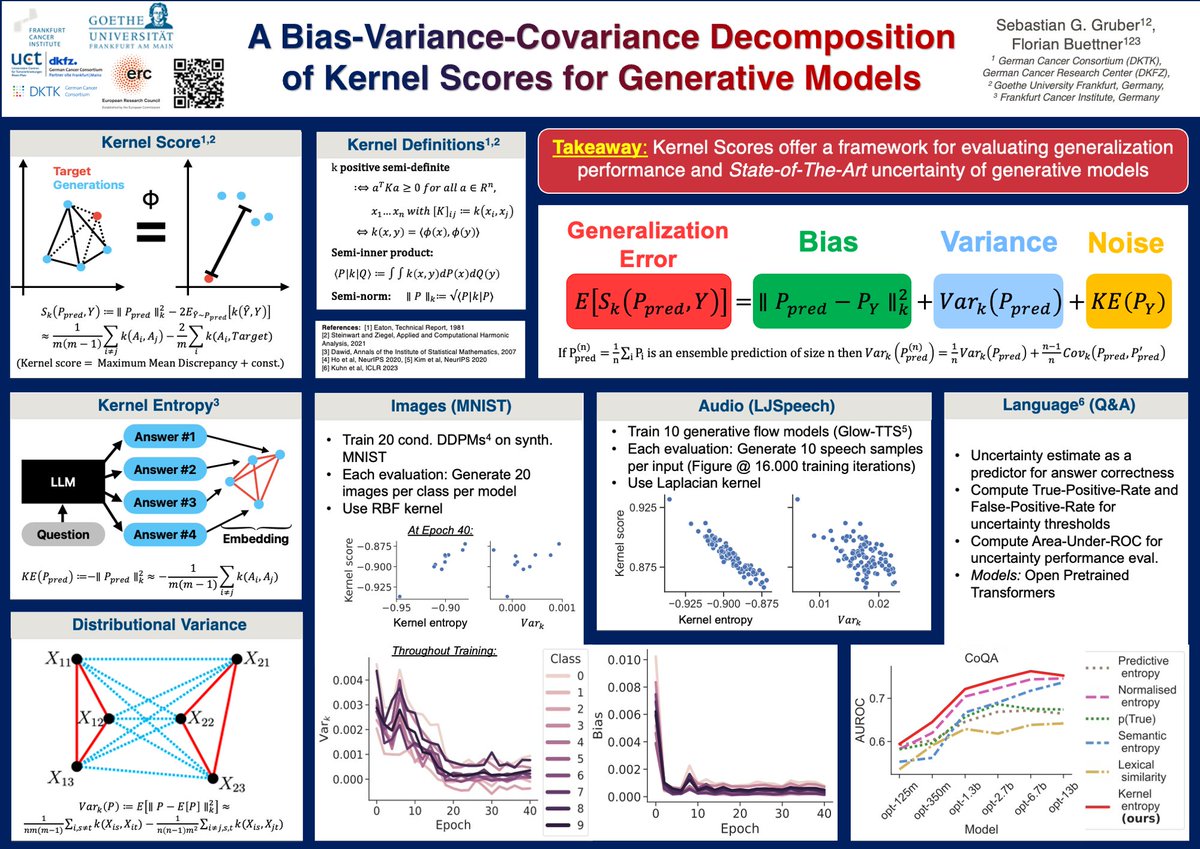
28 years ago the bias-variance-covariance decomposition of the mean squared error was introduced.
This week at @icmlconf, @BuettnerFlo and I will show that it also holds for kernel-based loss functions, which we use for image, audio, and language generation experiments...
Excited to be at #ICML2024 in Vienna with two exciting projects to improve the trustworthiness of modern AI systems that will hopefully help increase the uptake of such systems for real-world applications in industry and medicine!
🧵 1/3
3/3 How can generative models communicate their uncertainty? Via a novel bias-variance decomposition of kernel scores derived by @SebGGruber, we show that the kernel entropy as uncertainty measure is highly predictive of performance across modalities!
Young scientists regularly ask me for career advice. Academia or industry? Big company or startup? US or Europe? Good scientists in AI disciplines are fortunate to have many choices. But choosing can be stressful. I always give the same advice. 1/10
‼️The deadline for abstract submission to the Helmholtz AI Conference 2024 has been EXTENDED to April 14, Sunday! Take an active part in #HAICON24 - find more about contributions and submissions below 👇
https://t.co/uqoxmvsd04
@helmholtz_en@HIDAdigital@helmholtz_image