Productivity growth is everything.
That's the speed limit on growth, which is basically the speed limit on welfare.
And Europe has grown more slowly in measured productivity. That is robust. None of these disputes challenges that.
Keep that big picture framing.
Authors can't be trusted to run their own robustness checks.
In 17 AER papers, only 12/211 robustness checks "fail" with p > 0.05 (white).
In robustness checks chosen by 3rd parties, almost *half* of them fail (blue).
1/
New working paper with @AmolRaswan and Chris Udry: "The Sisyphean Pursuit of Evidence for Poverty Traps."
A central idea in development economics is that poverty can trap people. We went looking for the cleanest evidence. Here's what we found – and didn't.
People who hate SCM often dont know what SCM does or they have a paper they saw they dont like. Most of their criticisms, however, end up being about things that could apply to RDD, DID, IV, VAR, CVAR and even OLS.
Methods are tools. They can be misused. Says nothing about the tool
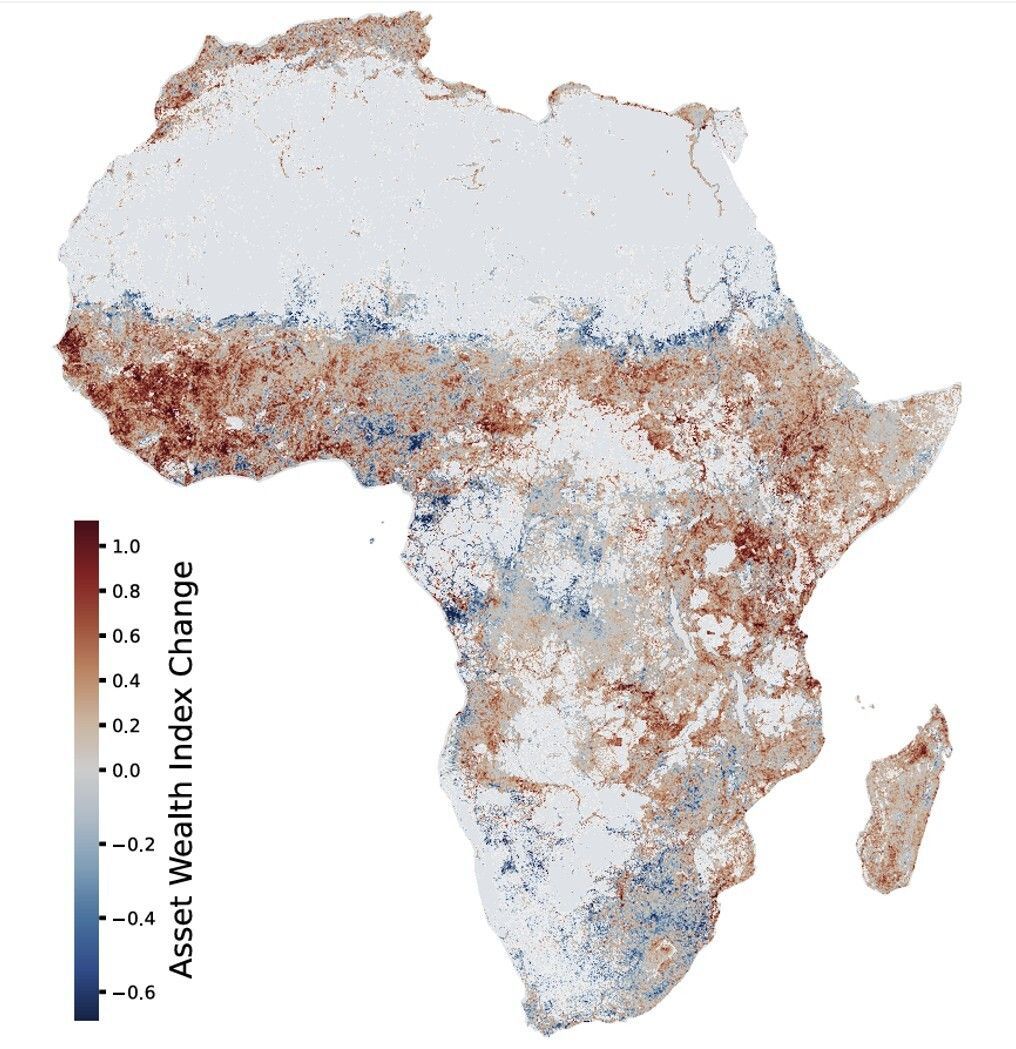
Measuring poverty used to mean flying data collectors to remote villages every decade. A satellite AI model just mapped every 6-km area of Africa for 36 GPU-hours total, which is roughly the cost of a tank of gas.
Cool paper by @MarshallBBurke and colleagues!
AI has now solved a major open problem -- one of the best known Erdos problems called the unit distance problem, one of Erdos's favourite questions and one that many mathematicians had tried.
https://t.co/SD1vVPkrHR
tldr
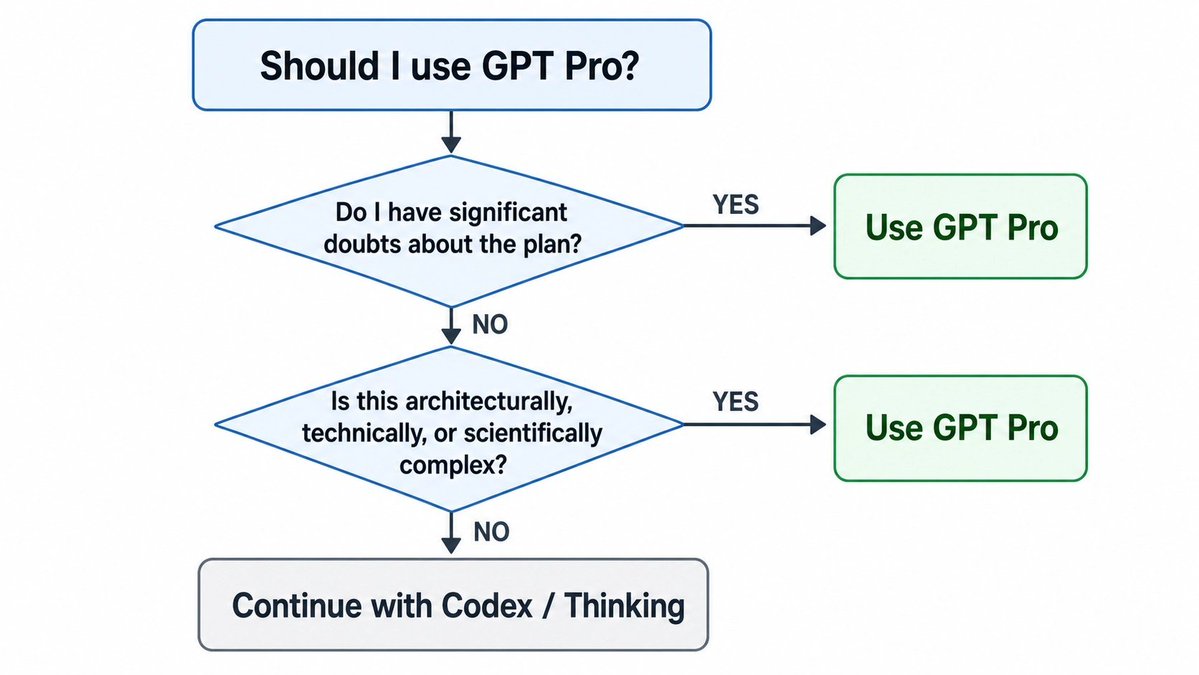
> GPT Pro is heavily underutilized by ChatGPT Pro subscribers
> my suggestion: use GPT Pro to review your complex plans before implementing them
> I discuss three cases: econ research, AI consulting, software development
To use GPT Pro *in* Codex
> Install oracle with "brew install steipete/tap/oracle". This is a useful tool to package context for review by GPT Pro.
> Install my oracle skill: https://t.co/b74jDSpr59
> Install the Codex Chrome extension: https://t.co/XFrluehsnh
Now, after you've iterated through some complex plan with Codex, send it to GPT Pro with "$oracle give me a review of the plan, add any important context"
Then, Codex will send a package to GPT Pro for review in a background Chrome tab. You'll retain control of your browser, be able to do other things, and Codex will keep polling the Chrome tab every 30 seconds or so until it gets a response.
Stanford recently livestreamed a 3.5 hour conference with leading economists (@Susan_Athey , Matt Gentzkow, and @ahall_research , among others) on "Empirical Work in the Age of AI"
I turned the whole thing into a readable transcript, separated by talk.
You can pass the whole thing to your coding agent to extract exactly what is useful for you.
Check it out here!: https://t.co/jKtU6mgG1X
This was not my experience this semester.
I followed @tylercowen idea of teaching 1/3 AI, so students become proficient with it and learn to use it well, to augment their learning rather than simply substitute for it, and 2/3 the standard material of the course.
In Development Economics, for example, a 400-level class where econometrics is a prerequisite, students are often not yet well prepared in the methods used in research. Several students told me that having AI teach them specific methods, and specific applications, was extremely useful.
The assignments were all designed to be done with AI, and they became more difficult than before. Students complained that they took too much time. But in the end, I think it is very useful for them to learn to think and work with AI as a tool at their side.
A fundamental lesson from my posts these last two weeks on modernization, industrial policy, and development is that development economics should be about understanding why South Korea got rich but Bolivia did not.
The current field has largely given up on that question. Sharply identified RCTs on small micro programs are a fine way to publish in the AER and get tenure at a fancy university, but a profession that knows everything about microfinance impact evaluations and almost nothing about industrialization has misallocated its own intellectual capital on a pretty heroic scale.
Four images of Seoul:
I just finished recording a free, 4+ hour course on the Codex Desktop App, with about 75% edited so far.
10 things I learned in the process of making the course:
1. OpenAI has killed it on interface - they're a clear level above Anthropic. It was such a pain in the ass to figure out how to add plugins in the Claude Desktop app's UI (wtf are "Connectors"), where as Codex makes them obvious and easy to install - just click on the button "Plugins".
2. gpt-5.5 xhigh can be overkill. I recommend xhigh for backend work, medium for frontend work and writing. Switch to xhigh/high if you find medium not doing enough for you.
3. Codex limits you to 6 subagents at a time. This is kind of limiting compared to Claude Code, which supports as many as 16 (?). I like having those parallel subagents for some code review workflows, and they don't work as well out of the box with Codex.
4. Codex subagents must be invoked explicitly by user request, where as Claude Code will frequently invoke subagents for you.
5. In Codex, plugins cannot include subagents. I hope this changes soon! Subagents do seem deemphasized overall in Codex relative to Claude Code.
6. If you're often hitting your weekly Codex limits, don't turn on fast mode early in the week. I was running 6-8 agents in parallel in a big burst of work on some 14 hour days on fast mode with gpt-5.5 xhigh, and I hit my weekly limits in 2.5 days! Instead, switch to fast mode toward the end of your week with the intention of ending it at close to 0.
7. Auto-review permission mode works pretty well! I still prefer Full Access + Destructive Command Guard for most of my work. But I'll teach it as default for most people, Claude Code's auto mode doesn't seem as good.
8. Cloud agents - at least according to the docs - are limited to gpt-5.3-codex as the latest available model. And there's no way to set up their environment in an infrastructure as code - type way. Doesn't seem to be an emphasis for OpenAI right now.
9. Codex skills come with an "openai.yaml" file which when configured, add some polish in the Codex desktop app, and also some optional dependencies. It confused me the first time I saw it!
10. It would be nice for Codex to have some built in skill for bootstrapping worktree environments - similar to Claude Code's "/update-config" for bootstrapping repo permissions. I made my own skill for this "/worktree-cli-boostrap", but I could see the nuisance of environment bootstrap as being enough of a hinderance to prevent many users from starting to work with worktrees.
The course will be out on YouTube on Friday (if my editor is fast) or Monday (if my editor is slow). I've also created an accompanying 180 slide deck which I'll release once the course is out.
Subscribe on my YouTube and you'll be the first to know https://t.co/7yH3LoXQS3 !
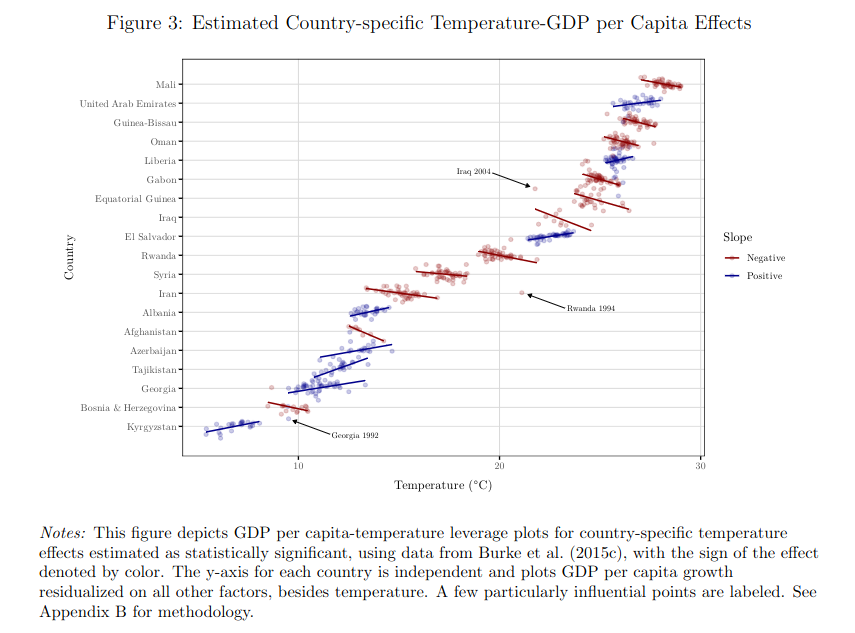
9/n) This figure shows within-country GDP-temperature relationships. El Salvador (tropical, service-based economy) and Iraq (desert, petrostate) have the same average temperature, but different within-country slopes. Pooling them in one regression assumes one global function.
A single GPU can now calculate hundreds of global weather scenarios in under 60 seconds. The exact same task requires a supercomputer and hours of brute-force physics.
Google DeepMind recently released WeatherNext 2. The model beats the previous state-of-the-art system on 99.9% of weather variables across a 15-day forecast window. It achieves this massive jump in accuracy using a new modelling approach called a Functional Generative Network.
Meteorologists categorise weather data into two buckets:
1. Marginals are isolated data points, like the precise temperature at a specific location or the wind speed at a certain altitude.
2. Joints are the massive, interconnected systems that form when all those individual elements interact.
The researchers hid the joint systems from the model during training. They only taught it the isolated marginals. When they turned it on, the model skillfully predicted the massive, complex systems anyway.
The architecture forces an 87-million-dimensional output distribution through a 32-dimensional mathematical bottleneck. To survive this severe constraint and still produce accurate individual data points, the neural network has no choice but to learn the underlying physics linking everything together. It figures out the weather because that’s the most efficient way to solve the maths.
The practical results are immediate. The model gives forecasters a full 24-hour advantage in tropical cyclone tracking compared to the previous leading system. It maps extreme wind speeds and heatwaves with unprecedented precision.
We’re watching a pretty big shift in predictive capabilities. The machine is deducing the structural reality of planetary weather from isolated fragments of data.
I’ve switched to using both and having them assess each other’s work and iterate.
It’s actually quite surprising how different their strengths and weaknesses are.
Mi grano de arena a este debate. Después de las elecciones de 2021, yo también estaba intrigado por los resultados. Cuando ONPE liberó las actas en formato digital (julio 2021), empecé a trabajar en un análisis forense. Terminé la versión final en septiembre 2024, pero para entonces el debate había muerto. Hoy veo que renació.
Aquí está mi paper.
¿Qué encuentro? Usando múltiples técnicas de detección de fraude electoral, ninguna detecta patrones consistentes con manipulación. De hecho, donde los efectos son identificables, van en dirección opuesta a lo que el fraude implicaría: las actas impugnadas están concentradas en territorio fujimorista (Lima: 1.99% de contestación vs. Puno: 0.47%), y esas actas favorecen a Fujimori, no a Castillo.
No hubo fraude.
__________________________________________________
Hoy subi el paper a mi Github.
Link del paper: https://t.co/a178X3XWnp
Todos los codigos estan disponibles para replicacion. Si alguien esta interesado: https://t.co/MeEydcKgvo
@dylantmoore This is great!
I often wonder whether skills need to spend lines describing syntax. Maybe it's enough to point Claude to .sthlp help files or a markdown translation of them?
Then the command-specific skills could focus on practical usage rules.