🚨HUGE: CHINA JUST CRACKED MYTHOS LEVEL OF VULNERABILITY DETECTION
China's Zhipu AI has reportedly matched Claude Mythos at discovering software vulnerabilities, marking a major leap in the U.S.–China frontier AI race, per WSJ.
The new GLM-5.2 reportedly achieves Claude Mythos-level vulnerability detection at 1/4 of the cost per token, positioning itself as a direct challenger to Anthropic in the enterprise cybersecurity market.
Les couts des modèles d'IA deviennent insupportables pour les grandes entreprises (Amazon, Walmart, Cisco, Uber, Meta...) et elles commencent à en limiter l'accès à leurs collaborateurs, ne parvenant pas à en mesurer l'efficacité productive.
En conséquence, ce sont les tokens chinois, moins chers du fait d'une énergie primaire moins élevée, qui raflent la mise.
We created a monster’: companies rein in AI usage as costs strain budgets - https://t.co/Bkpuj7K5kl via @FT
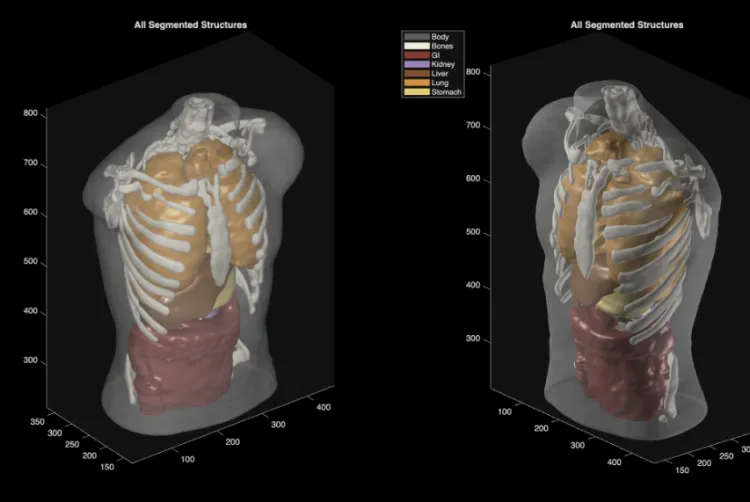
Midjourney's massive pivot into the personal health and medical industries.
Its first hardware project, a scanner that reads your body in 60 seconds, with 'full-body ultrasound machine'.
The plan is to put people in water, lower them through a sensor ring, send ultrasound waves through the body from many angles, record how those waves bend and scatter through fat, muscle, bone, and organs, then reconstruct a 3D internal map rather than a normal flat ultrasound view.
The water matters because ultrasound travels cleanly through it, so the body can be scanned from all sides without a handheld probe pressing against one spot.
Midjourney says the system uses 40 Butterfly Ultrasound-on-Chip modules, thousands of transducers, and about two petaflops of processing to reconstruct 3D maps of muscle, fat, bone, and organs in about 60 seconds.
This is closer to ultrasound CT than hospital CT, because it uses sound waves instead of ionizing radiation, and it avoids MRI’s strong magnets.
Midjourney’s first target is not cancer diagnosis or organ-disease detection, but body composition maps, meaning repeatable scans that show changes in muscle, fat, bone, organs, and possibly training or diet effects.
Medical diagnosis would need FDA clearance, so the likely path is wellness first, then narrow medical claims one by one, rather than a finished hospital-grade MRI replacement on day 1.
The first public site is planned for San Francisco by end-2027, inside a Midjourney Spa with about 10 scanners, hot tubs, saunas, cold plunges, and a gym.
Midjourney says the bigger target is 50,000 scanners globally over 6 years and 1B full-body scans per month, but that is still a company ambition, not a proven deployment plan.
What is happening here is a bet that medical imaging becomes less like a rare test and more like a longitudinal record of the body
Yann LeCun va probablement gagner le débat scientifique sur l'IA.
Et ça n'aura aucune importance. 👇
Le résumé tient en deux lignes : l'un des pères de l'IA quitte Meta, lève un milliard de dollars, et part prouver que les LLM, ChatGPT, Claude, Grok, sont une impasse vers l'intelligence réelle.
Sur le fond, il a sans doute raison. Un LLM ne comprend pas le monde, il prédit le mot suivant. Ni mémoire, ni modèle du réel, ni vraie planification. LeCun le dit crûment : c'est moins intelligent qu'un chat. Techniquement, dur de lui donner tort.
Sauf qu'il répond à la mauvaise question.
LeCun demande : « qu'est-ce que l'intelligence réelle ? »
Le marché, lui, demande : « qu'est-ce qui est utile, maintenant ? »
Ce ne sont pas la même question. Et les confondre, c'est l'erreur classique du chercheur.
Le marché n'a jamais payé pour de l'intelligence. Il paie pour de l'utilité.
On n'a jamais appris aux avions à battre des ailes. On se fichait de reproduire le vol « réel » des oiseaux, on voulait juste voler. Résultat : des machines qui ne comprennent rien à l'aérodynamique d'un moineau transportent des millions de gens par jour.
Les LLM, c'est pareil. Ils ne comprennent pas le monde. Et ça ne les empêche pas de réécrire ton code, rédiger ton contrat, avaler des métiers entiers. Un outil n'a pas besoin d'un modèle du monde pour valoir des trillions.
Je build avec ces modèles tous les jours. Ils sont « bêtes » au sens de LeCun. Ça ne m'a jamais empêché de shipper quoi que ce soit.
LeCun construit peut-être ce qui comptera en 2035. Mais pour les dix prochaines années, les utilisateurs, la valeur, l'argent, tout est sur les modèles « stupides ».
On confond toujours avoir raison et gagner.
LeCun aura peut-être raison. Les LLM, eux, ont déjà gagné.
I was wrong
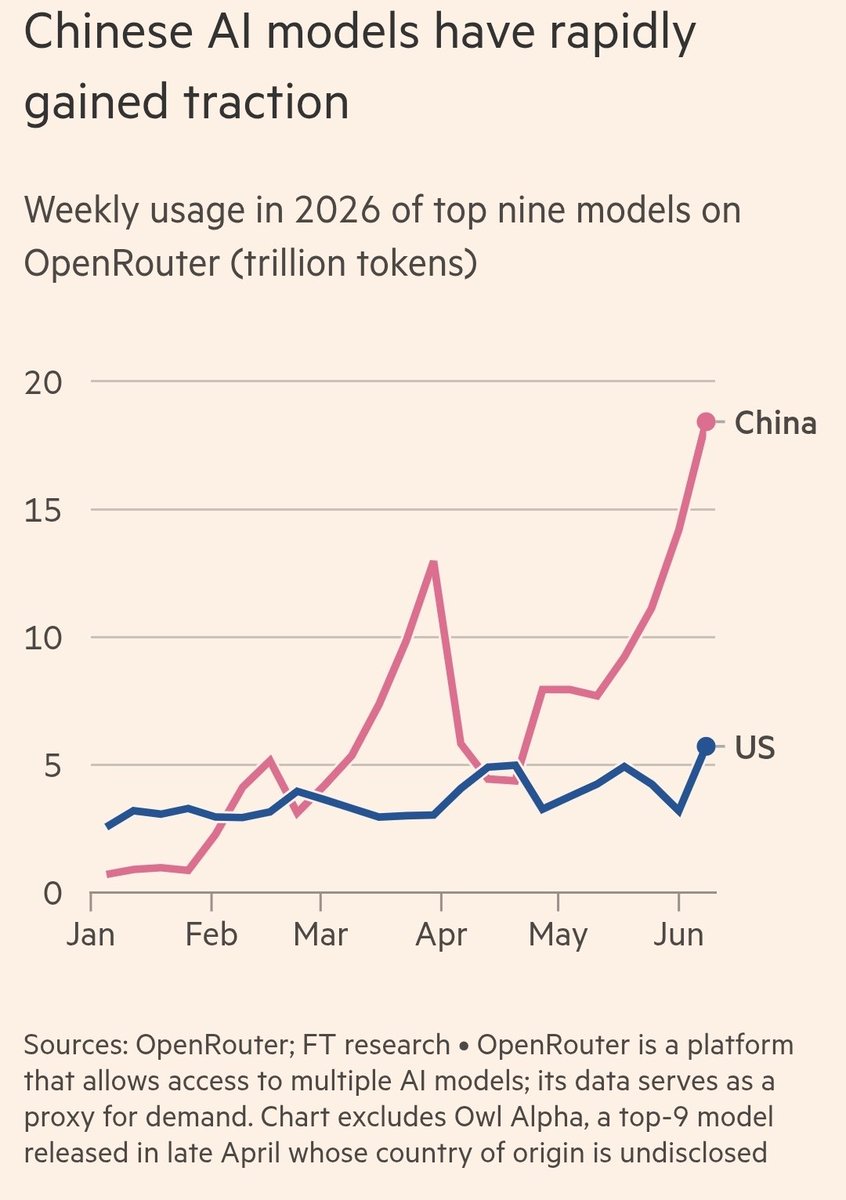
I've been saying for months that open source AI models are 6 months behind frontier
They caught up. GLM 5.2 is as good as Opus 4.8
This changes everything. If you run GLM 5.2 locally no government can take it away. You become sovereign
And even if you run through APIs, its a fraction of the cost
The battlefield is different now. If open source is as good as frontier, and people have cheaper alternatives, governments can't be as quick to regulate. It will destroy the frontier AI labs
All of this is such a massive win for the people
If you are not paying attention to local models yet, you are making a tremendous mistake
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.
This is the silent limiter on Claude Fable 5.
Fable 5 may not give you its full strength when you use it to build or improve frontier AI models — especially work that helps train, scale, copy, or optimize a powerful Claude/GPT-class model.
Anthropic says in these cases Fable 5 may not visibly refuse or switch models, but may quietly reduce its own effectiveness through hidden safeguards like prompt modification, steering vectors, or PEFT.
As a paying user, that matters: the model can still sound helpful while being intentionally less capable in a narrow but important category of work.
i.e. you may not get Fable 5’s best ability:
- Building a large-model pretraining pipeline.
- Designing data pipelines for training a frontier LLM.
- Planning distributed training across huge GPU clusters.
- Debugging or optimizing model-parallel training systems.
- Designing infrastructure for large-scale pretraining runs.
- Working on ML accelerator or AI-chip design.
- Trying to distill or copy a frontier model.
- Asking how to make a competing frontier model stronger, cheaper, or faster.
A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.
Google's new algorithm just shrunk 31GB of memory down to 4GB 🤯
TurboVec is a new open-source tool that stores the data your AI app searches through, using 16x less memory.
It runs on Google's TurboQuant, which skips the slow setup step every other tool needs.
→ Faster search than the popular alternative (FAISS)
→ Works on both Mac and standard servers
→ Narrow results to exactly what you want
→ Plugs straight into LangChain and LlamaIndex
Your data never leaves your machine. Runs fully offline, works with Python out of the box.
100% Open Source.
🚨 AI Just Created a Material Humans Never Imagined!
Scientists have developed a revolutionary new material that is stronger than steel, lighter than foam, and up to 5 times stronger than titanium.
The most surprising part? It was designed by artificial intelligence, not human engineers.
Using AI, researchers created entirely new microscopic structures that were later 3D-printed and tested. The results could lead to lighter airplanes, stronger buildings, and more efficient vehicles.
This breakthrough shows that AI is no longer just helping scientists—it’s starting to invent alongside them.
What could the world look like when AI designs the materials of the future?
Source: University of Toronto. AI-designed nanomaterials achieve exceptional strength and lightness. University of Toronto Engineering News.
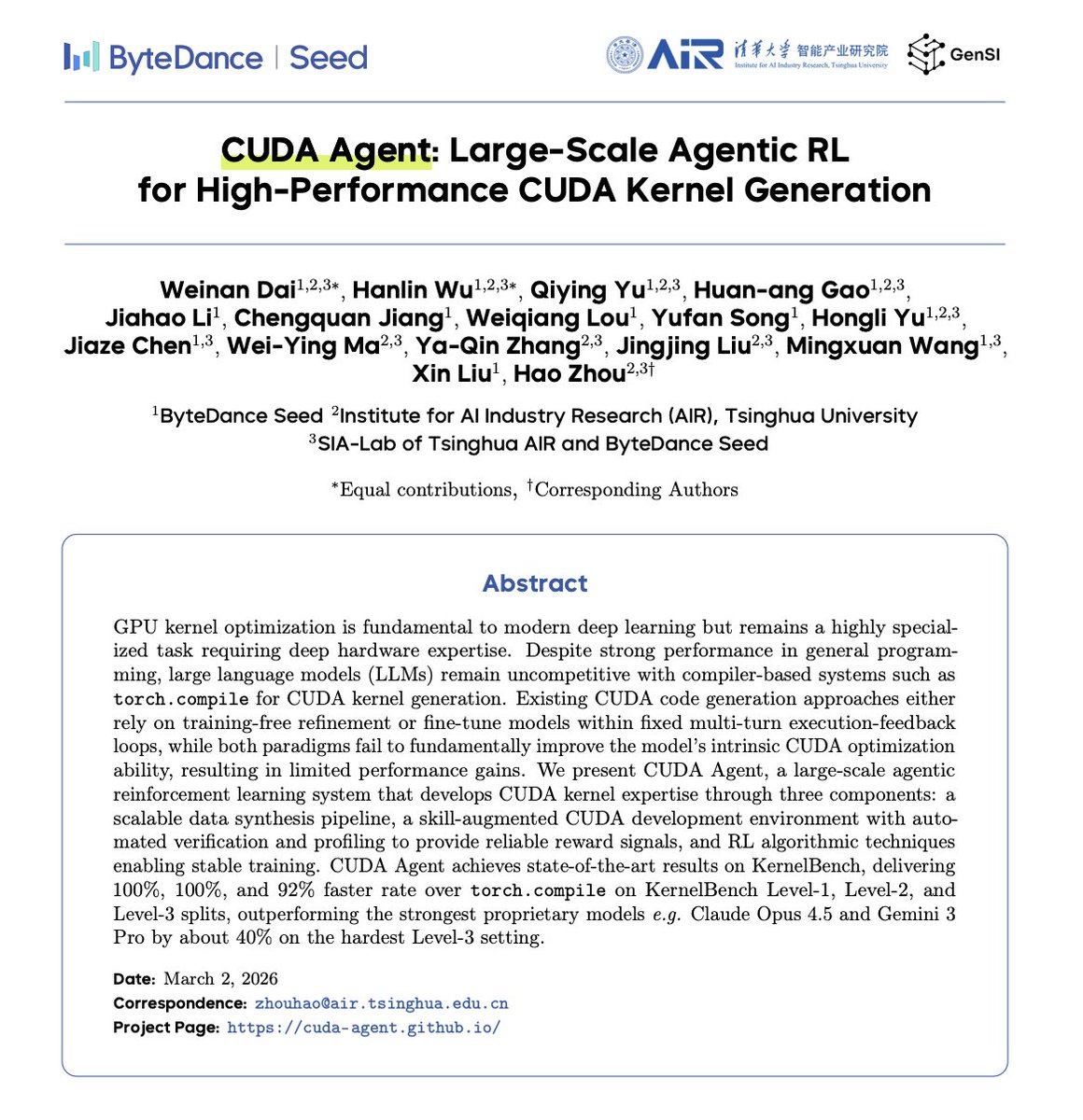
ByteDance has published a paper that should make every NVIDIA investor sweat.
They trained an AI that writes CUDA better than humans experts.
They call it CUDA Agent.
And it completely rewrites the economics of AI hardware.
They built a massive agentic reinforcement learning loop. The AI writes a kernel, compiles it, profiles the hardware, analyzes the bottlenecks, and rewrites the code until it's flawless.
It learned how to optimize memory access patterns and hardware tiling strategies that traditional compilers miss.
The results are staggering.
On the industry-standard KernelBench, CUDA Agent completely destroyed traditional compilers.
It delivered code that runs up to 3.2x faster than PyTorch's native execution.
On the hardest, most complex models, it beat the strongest proprietary models in the world—including Claude Opus 4.5 and Gemini 3 Pro, by 40%.
It didn't just match human experts. It started discovering optimizations that static compilers literally cannot see.
Here is why this is a massive threat to NVIDIA.
NVIDIA's dominance relies on the fact that CUDA is incredibly hard to master. Developers get locked in because optimizing code for other chips is too painful.
But if an AI agent can autonomously generate hyper-optimized hardware kernels...
You don't need a team of $500k a year CUDA engineers to build world-class infrastructure.
And if an AI can autonomously master CUDA, it can master AMD's ROCm. Or custom silicon.
The impenetrable software wall protecting NVIDIA's monopoly just got breached by a reinforcement learning loop.
If anyone can automatically squeeze maximum performance out of any chip...
Hardware becomes a commodity.
🇺🇸🇨🇳Huawei’s chairman just turned U.S. chip controls into a victory speech for China’s semiconductor rise.
“We are also grateful to the US for enabling our country’s semiconductor industry chain to truly grow,” Xu Zhijun said
Huawei’s Tau Scaling Law has shifted the target from “make transistors smaller” to “make signals arrive faster,” because modern chips often lose speed inside long wires, timing buffers, and layout delays rather than inside the transistor itself.
Huawei says this path could reach density comparable to 1.4 nm by 2031.
LogicFolding attacks that bottleneck by stacking logic in 3D, shortening the distance signals travel, increasing density without restricted EUV machines, and reportedly cutting redundant buffers by more than 50%.
While, this is not the same as owning TSMC-style leading-node manufacturing, because China still faces hard gaps in yield, power efficiency, tooling, and global production scale - But still it's a massive progress in developing China's own chip design stack.
The story shows how sanctions can slow a company while teaching it where to become stronger.
---
huaweicentral. com/we-are-thankful-to-us-for-enabling-our-chip-tech-growth-huawei/
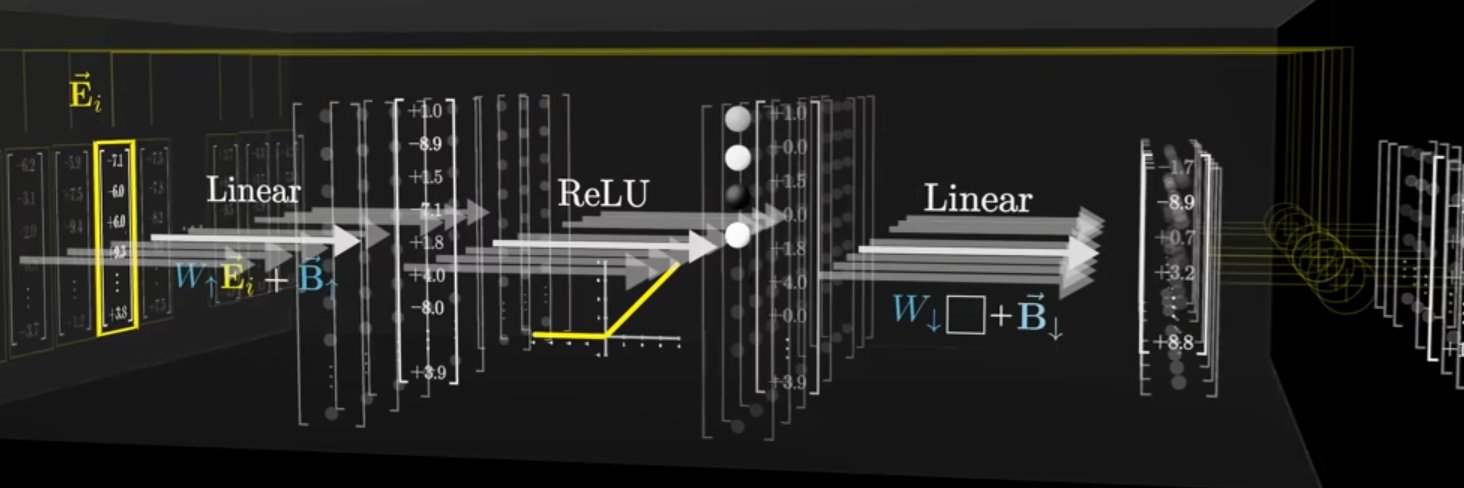
Google has quietly dropped what researchers are calling "Attention Is All You Need V2."
And it signals the end of the Transformer era as we know it.
In 2017, the original "Attention Is All You Need" paper changed the world by proving that AI doesn't need recurrence, it just needs to pay attention.
But today, even the most advanced models like GPT and Gemini suffer from a massive, structural flaw: Catastrophic Forgetting.
The moment an AI learns something new, it starts losing what it learned before. It’s why AI "hallucinates" or loses the thread in long conversations.
This paper, titled "Nested Learning: The Illusion of Deep Learning Architectures," completely replaces the way AI stores information.
The researchers have introduced a paradigm shift called Nested Learning (NL).
Here is why this is "V2":
For the last decade, we treated AI models as one giant, flat mathematical function. NL proves that a model is actually a set of thousands of smaller, "nested" optimization problems running in parallel.
Instead of one giant "memory," each layer has its own internal "context flow." This allows the model to learn new tasks at test-time without overwriting its core intelligence.
It moves us past the static Transformer. The new architecture (HOPE) demonstrated 100% stability in long-context memory and "post-training adaptation" that was previously impossible.
The technical takeaway is brutal for the competition:
Existing deep learning works by compressing information until it breaks. Nested Learning works by organizing information so it can grow forever.
We’ve spent 7 years trying to make Transformers bigger. Google figured out how to make them "Nested."
The Transformer replaced the RNN in 2017.
Nested Learning is here to replace the Transformer in 2026.
🚨 The world’s first open-source 100B medical LLM is here 🏥 Local inferencers have a Health model option to run at home.
AntAngelMed (100B params, only 6.1B active) recently released:
✅ Tops open-source models on MedBench & HealthBench
✅ 200+ tokens/sec on H20 hardware
✅ 128K context length
💪 Strong in medical reasoning, safety & empathy
🔒 Runs locally (full privacy)
⚡ Only 6.1B active params (very efficient)
🧠 Fine-tunable for hospitals & research
🖥️Practical Deployment Options for AntAngelMed (100B Medical LLM) (all are only estimates)
✅ Best Balance → INT4 (~50 GB) on 2–4x GPUs (RTX 5090 / 4090)
✅ Max Quality → FP8 (~100 GB) on (DGX Spark, Mac Studio 128GB)
✅ Budget Option → INT4 (~50 GB) on 2x RTX 4090 + CPU offload (slower)
❌ Single RTX 5090 (32GB) → Not recommended (model too big)
❔ GGUF could bring down the size even more
Built by Zhejiang Health + Ant Healthcare.
A big jump for open & privacy-friendly medical AI.
🇺🇦 Yulia Mendel, ex-porte-parole de Zelensky, balance tout chez Tucker Carlson : le pays n’a plus que 25 millions d’habitants sur son sol, dont 11 millions de retraités qui crèvent avec 75 à 200 dollars par mois. Des civils meurent de faim et de froid. Les morts à la guerre ? Des centaines de milliers, cachés ou maquillés en crises cardiaques. Et elle accuse directement Zelensky de blanchiment d’argent massif.
Voilà le « bastion de la démocratie » qu’on finance à coups de milliards.
Research proves that current AI agent groups cannot reliably coordinate or agree on simple decisions.
Building teams of AI agents that can consistently agree on a final decision is surprisingly difficult for LLMs.
But problem is that developers frequently assume that if you have enough AI agents working together, they will eventually figure out how to solve a problem by talking it through.
This paper shows that this assumption is currently wrong. Even in a friendly environment where every agent is trying to help, the team often gets stuck or stops responding entirely. Because this happens more often as the group gets bigger, it means we cannot yet trust these agent systems to handle tasks where they must agree on a correct answer.
----
Paper Link – arxiv. org/abs/2603.01213
Paper Title: "Can AI Agents Agree?"