Twinflow distillation blog for qwen-image-2512 is finally up:
the idea: 2 NFE on a 20B flow model. standard twinflow gives you a performance ceiling (student can't beat teacher). so i bolted on latent-space rl gradients to escape the teacher's distribution + dynamic renoise sampling to stop early training from collapsing.
did it work? kinda!
checkpoints from step 5k-10k are on hf if you want to poke at them and figure out what i did wrong. my guess is the rl weight ramp needs to be sigmoidal not a hard switch and more steps!
All the links to the blog, code and the checkpoints are in comments (just so that X does not limit this post).
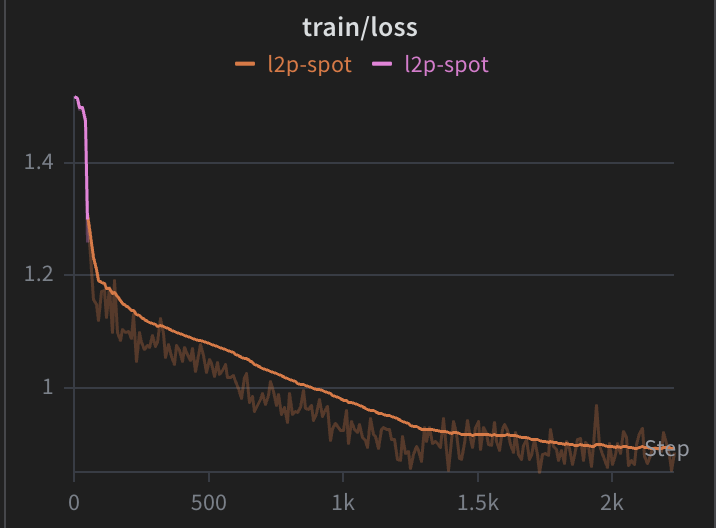
Distilling Qwen-Image-2512 using TwinFlow, student sucking up knowledge from a monster teacher I think qwen-image is capable of doing far more then Z-image atleast on the realistic front (personal observations). Slashed batch times with MP and custom augs, 8xH200 pinned at max pretty much. Also added RL to the loop in theory it should get better then the teacher but that remains to be seen since the RL kicks in after 2k steps. The loss wont be very indicative of how the training is working I guess since its a distillation run, attaching some results on how it's going [at 1100 and 1600].
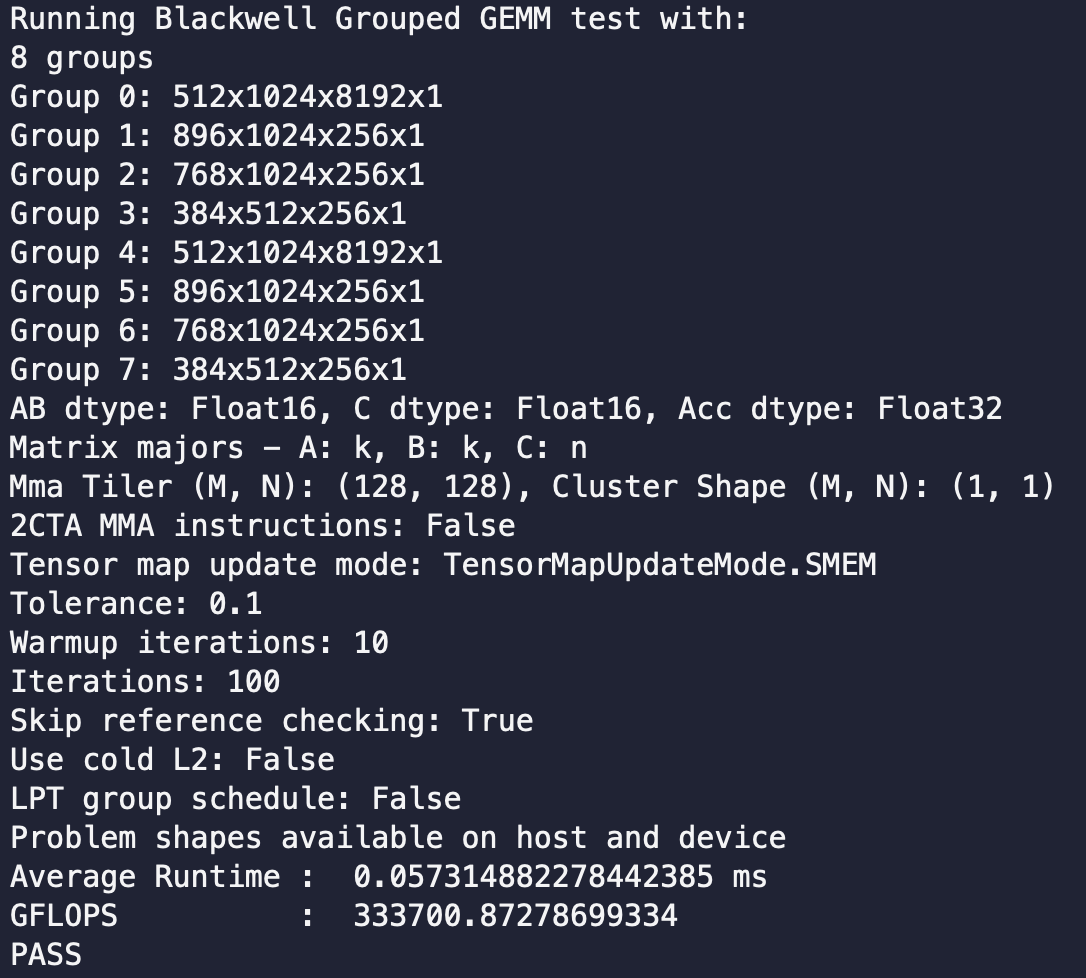
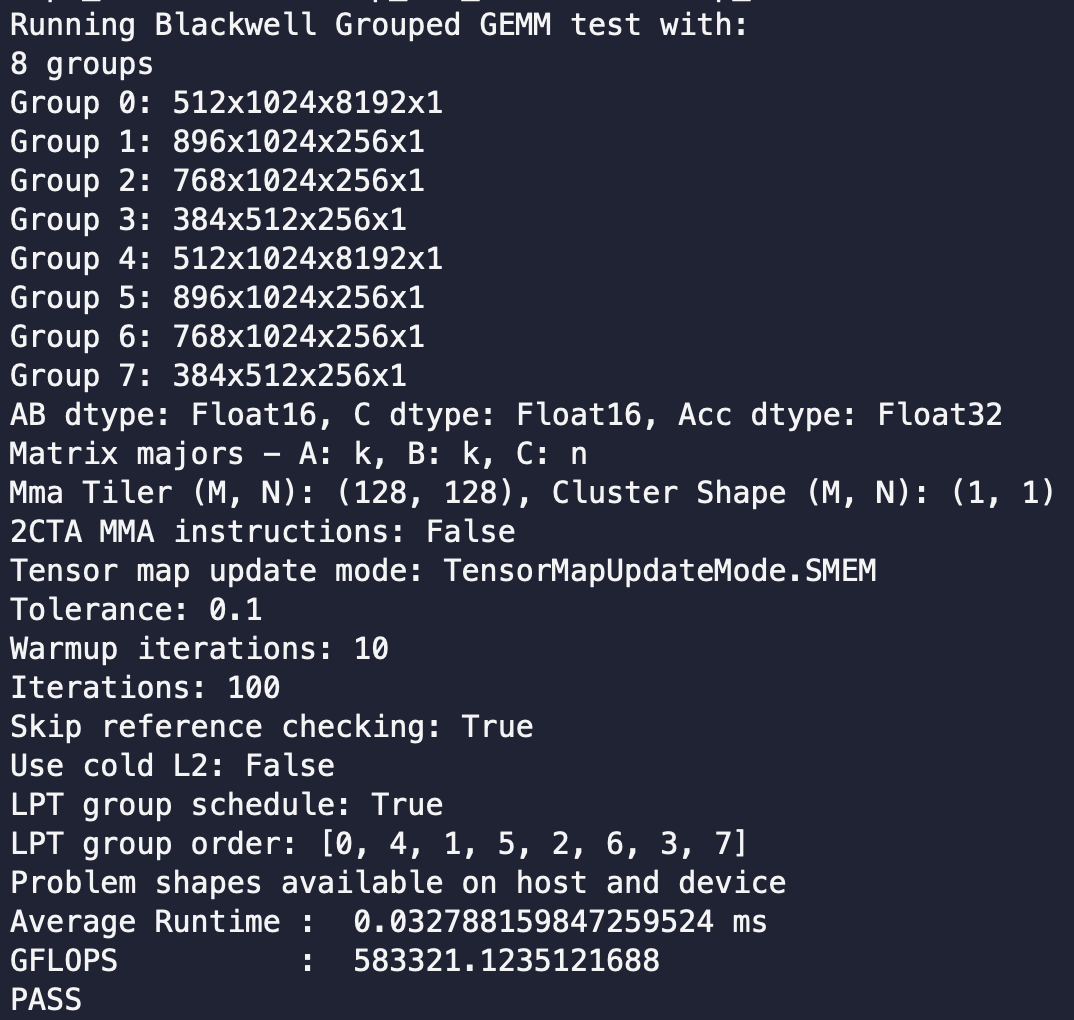
clever, I think descending only matters because the scheduler is dynamic. on a static strided persistent scheduler, it should be symmetric against reversal, so asc should give similar speedups? though won't call it LPT anymore would be just grouping equal-K tiles to balance CTA bands.
FA4's SingleTileLPTScheduler exploits that causal attention work grows with block index, so it just visits blocks in reverse (block = num_block - 1 - block).
So why not try something similar on grouped gemm! In grouped GEMM the analog is that a tile's mainloop time is proportional to its group's K, and StaticPersistentGroupTileScheduler visits tiles in group-metadata order. So LPT = order groups by descending K.
Result is 1.74x speedup in grouped gemm, just by sorting the scheduling path.
If you're buying a UGREEN NVMe enclosure for anything chip-specific (atleast in india), there new batches atleast on there USB3.x enclosures come with an RTL chip (RTL9210) even though they mention ASM chips on some of there enclosures, might just be silicon lottery across there batches, this is for USB3.x, there USB4 enclosures might still come with an ASM chip
Pixel-space autoregressive generation.
The model demonstrates strong generative performance while maintaining high linear probing accuracy. Can we unify image understanding and generation with AR?
https://t.co/l9QA5vFerA
we love @Etched 🚀
congrats @robertwachen@UbertiGavin and the entire team. @LoganPaul and I @antifund saw the early demos last winter and what this team is building is insane.
excited to run my own frontier inference cluster in my garage 😂
step 11600, changed a lot of stuff, had a measurement bug on PSNR (it is the only metric i have however bullshit it might be), I thought it was undersampling so added a 50 step sample (It wasn't), added a decode recon test in order to measure the right PSNR, and more importantly made the run true to the paper, fixed LR, global BS 64, and much more balanced sigma selection, I feel its just underconverged the paper mentions 100k steps I'm not even close to being done but its good to remove all paths to failure.
[compare the images to the quoted once, noticeably less noisy now]
more details on Github [https://t.co/sw0uiNFDmG]
5800, moving slowly ofc, no visible changes, though I finally got to writing the readme for it and everything is in its place now !
links to everything below ofc, using the readme as a report here on what worked and the progress of it all.
finally got time to play around with krea 2 and yeah it does blow my mind how much this does out of the box, always wanted to make something similar to "into the spiderverse" inspired something, I guess lets see how well it can replicate those.
btw I'm using it with the layer scaling from here https://t.co/PEDKXDdi8A
So some progress on this, got a decent overfit run, Using 6/6 blocks rather then 3/3 i think in the paper cause that just works better on my runs, the thing does memorizes the images in pixel space, single step recon is pretty gooood.
from pure noise is a little soft but hey it was a small run, does plateau after a while but could be just a scaling thing. training more on low-noise steps does make it plateau a little later but it does plateau after a while.
I remember talking to @NagaSaiAbhinay about Muon a few days back so tried that as well, Muon on 2D attn/mlp weights and AdamW for embeddings, norm and decoder did not quite beat AdamW on my test runs - could be cause most of the work is being done by the detailer head here and Muon just doesn't finetune an Adam-pretrained model well.
attached a couple of samples from the overfit run and loss for adam and muon runs, sudden jumps in the loss is due to low sigma.
5800, moving slowly ofc, no visible changes, though I finally got to writing the readme for it and everything is in its place now !
links to everything below ofc, using the readme as a report here on what worked and the progress of it all.
4600, there were no GPUs where I wanted for the whole of yesterday lets see how today goes, still on 2 GPUs I'm seriously thinking of setting grad accum to 2 to match the paper,
also on the second image the guy started walking the right direction now (look at the same image in the quoted post below)
We release TIRx today, a minimal compiler stack and hardware-native DSL for frontier ML kernels, built around storage-first tensor layouts and reusable tile primitives.
https://t.co/V1yHdxlpCi
On NVIDIA B200, TIRx delivers up to ~1.08× over cuBLASLt on dense GEMM, outperforms DeepGEMM on all FP8 blockwise workloads with up to ~1.09× speedup, keeps FlashAttention-4 (FA4) typically within ~±2% of CuTeDSL, and remains competitive with cuBLASLt/FlashInfer on NVFP4 GEMM.
Through our past experiences building frontier ML kernels, megakernels, and agentic kernel systems, we kept seeing the same boundary problem: new operators and new hardware require new optimization strategies that often break old programming models or compiler passes.
TIRx builds on top of Apache TVM and moves toward a simple goal: let users and agents express the best-performing program, even for future hardware generations, while keeping the engineering effort for new kernels and new hardware as low as possible.
4600, there were no GPUs where I wanted for the whole of yesterday lets see how today goes, still on 2 GPUs I'm seriously thinking of setting grad accum to 2 to match the paper,
also on the second image the guy started walking the right direction now (look at the same image in the quoted post below)
started the final (maybe) run, using the same 6/6 block with a BS of 16 across 2xH200s for now its on spot and the ladder should check for 8/4 x H100/H200 from here, attaching some samples from the latest step (2200)
been traveling around kerala for a while now, pretty much the reason there are no updates on the L2P training.
Though I did try deploying it on runpod 8xH100 spot ofc and for some reason I could not, I remember it being pretty nice not really sure what happened I was bidding like more then the on demand instances to atleast deploy something but it just did not let me.
So I migrated to verda, again spot instances, going good as of now though I can only find like 2xH200 everytime like 4x and 8x instances does pop here and there but the 2x I have has been working for like 8-9 hours now without degradations for some reason.
I might remove the 2x from the ladder, though waiting for a 4x or a 8x to be available and with its relativly quick degradation period it might just be fine running the 2x for the whole time I'm not sure maybe tell me in the comments.
Here are some not so related pictures from here.

![Shauray7's tweet photo. Distilling Qwen-Image-2512 using TwinFlow, student sucking up knowledge from a monster teacher I think qwen-image is capable of doing far more then Z-image atleast on the realistic front (personal observations). Slashed batch times with MP and custom augs, 8xH200 pinned at max pretty much. Also added RL to the loop in theory it should get better then the teacher but that remains to be seen since the RL kicks in after 2k steps. The loss wont be very indicative of how the training is working I guess since its a distillation run, attaching some results on how it's going [at 1100 and 1600].](https://pbs.twimg.com/media/G_nPB-gbsAAkwgT.jpg)
![Shauray7's tweet photo. Distilling Qwen-Image-2512 using TwinFlow, student sucking up knowledge from a monster teacher I think qwen-image is capable of doing far more then Z-image atleast on the realistic front (personal observations). Slashed batch times with MP and custom augs, 8xH200 pinned at max pretty much. Also added RL to the loop in theory it should get better then the teacher but that remains to be seen since the RL kicks in after 2k steps. The loss wont be very indicative of how the training is working I guess since its a distillation run, attaching some results on how it's going [at 1100 and 1600].](https://pbs.twimg.com/media/G_nOi67bAAEejqc.png)
![Shauray7's tweet photo. Distilling Qwen-Image-2512 using TwinFlow, student sucking up knowledge from a monster teacher I think qwen-image is capable of doing far more then Z-image atleast on the realistic front (personal observations). Slashed batch times with MP and custom augs, 8xH200 pinned at max pretty much. Also added RL to the loop in theory it should get better then the teacher but that remains to be seen since the RL kicks in after 2k steps. The loss wont be very indicative of how the training is working I guess since its a distillation run, attaching some results on how it's going [at 1100 and 1600].](https://pbs.twimg.com/media/G_nOU_3asAECRO2.jpg)




![Shauray7's tweet photo. step 11600, changed a lot of stuff, had a measurement bug on PSNR (it is the only metric i have however bullshit it might be), I thought it was undersampling so added a 50 step sample (It wasn't), added a decode recon test in order to measure the right PSNR, and more importantly made the run true to the paper, fixed LR, global BS 64, and much more balanced sigma selection, I feel its just underconverged the paper mentions 100k steps I'm not even close to being done but its good to remove all paths to failure.
[compare the images to the quoted once, noticeably less noisy now]
more details on Github [https://t.co/sw0uiNFDmG]](https://pbs.twimg.com/media/HL-D12xbcAAl8SM.png)
![Shauray7's tweet photo. step 11600, changed a lot of stuff, had a measurement bug on PSNR (it is the only metric i have however bullshit it might be), I thought it was undersampling so added a 50 step sample (It wasn't), added a decode recon test in order to measure the right PSNR, and more importantly made the run true to the paper, fixed LR, global BS 64, and much more balanced sigma selection, I feel its just underconverged the paper mentions 100k steps I'm not even close to being done but its good to remove all paths to failure.
[compare the images to the quoted once, noticeably less noisy now]
more details on Github [https://t.co/sw0uiNFDmG]](https://pbs.twimg.com/media/HL-D12la0AAzfwI.png)
![Shauray7's tweet photo. step 11600, changed a lot of stuff, had a measurement bug on PSNR (it is the only metric i have however bullshit it might be), I thought it was undersampling so added a 50 step sample (It wasn't), added a decode recon test in order to measure the right PSNR, and more importantly made the run true to the paper, fixed LR, global BS 64, and much more balanced sigma selection, I feel its just underconverged the paper mentions 100k steps I'm not even close to being done but its good to remove all paths to failure.
[compare the images to the quoted once, noticeably less noisy now]
more details on Github [https://t.co/sw0uiNFDmG]](https://pbs.twimg.com/media/HL-D12db0AAR6Td.png)
































![Shauray7's tweet photo. Distilling Qwen-Image-2512 using TwinFlow, student sucking up knowledge from a monster teacher I think qwen-image is capable of doing far more then Z-image atleast on the realistic front (personal observations). Slashed batch times with MP and custom augs, 8xH200 pinned at max pretty much. Also added RL to the loop in theory it should get better then the teacher but that remains to be seen since the RL kicks in after 2k steps. The loss wont be very indicative of how the training is working I guess since its a distillation run, attaching some results on how it's going [at 1100 and 1600].](https://pbs.twimg.com/media/G_nPB-_WUAAwVvB.jpg)





![Shauray7's tweet photo. step 11600, changed a lot of stuff, had a measurement bug on PSNR (it is the only metric i have however bullshit it might be), I thought it was undersampling so added a 50 step sample (It wasn't), added a decode recon test in order to measure the right PSNR, and more importantly made the run true to the paper, fixed LR, global BS 64, and much more balanced sigma selection, I feel its just underconverged the paper mentions 100k steps I'm not even close to being done but its good to remove all paths to failure.
[compare the images to the quoted once, noticeably less noisy now]
more details on Github [https://t.co/sw0uiNFDmG]](https://pbs.twimg.com/media/HL-D12zbcAAURsD.png)