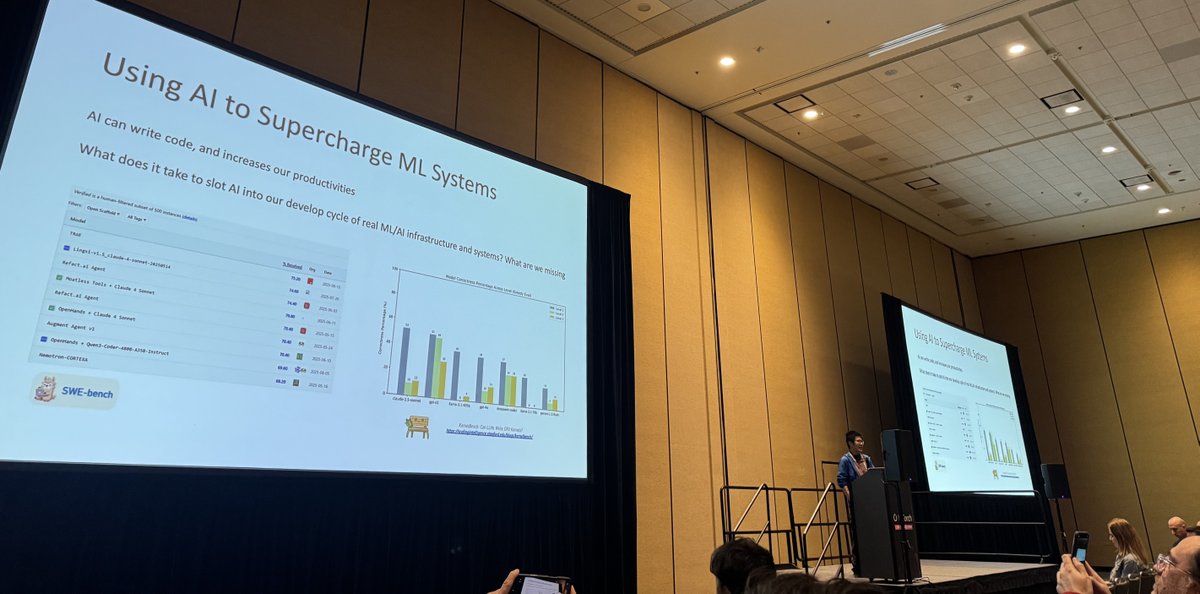
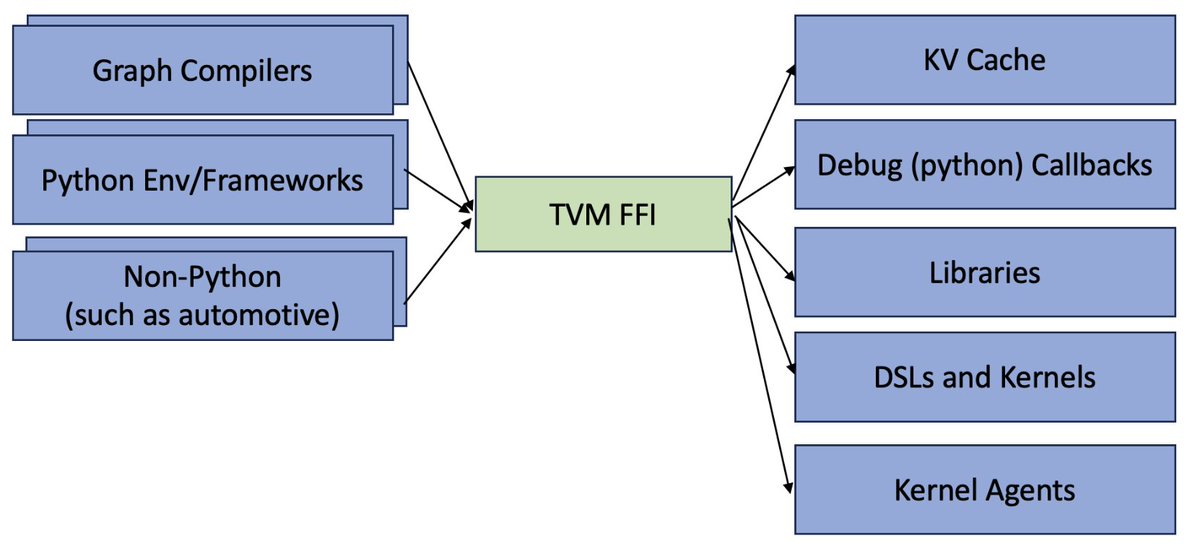
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust https://t.co/m2gHJRreol
Live from the AI Infra Summit, co-located with #PyTorchCon — Tianqi Chen (@nvidia) explores how shared ML foundations can advance interoperability across compilers, libraries, DSLs, and frameworks, while unifying workloads across edge and cloud.
🔗 https://t.co/lLaazPPW2z
#AIInfraSummit #OpenSourceAI #AIInfrastructure
Happy to announce that I joined the CMU Catalyst with three of my incoming students.
Our research will bring the best models to consumer GPUs with a focus on agent systems and MoEs.
It is amazing to see so many talented people at Catalyst -- a very exciting ecosystem!
Really thrilled to receive #NVIDIADGX B200 from @nvidia . Looking forward to cooking with the beast. Together with an amazing team at CMU Catalyst group @BeidiChen@Tim_Dettmers@JiaZhihao@zicokolter, We are looking at the innovate across entire stack from model to instructions
Thank you to @NVIDIA for gifting our Catalyst Research Group the latest NVIDIA DGX B200! The B200 platform will greatly accelerate our research in building next-generation ML systems.🚀 #NVIDIADGX#DGXB200 @NVIDIADC
Huge thank you to @NVIDIADC for gifting a brand new #NVIDIADGX B200 to CMU’s Catalyst Research Group! This AI supercomputing system will afford Catalyst the ability to run and test their work on a world-class unified AI platform.
🚀Making cross-engine LLM serving programmable.
Introducing LLM Microserving: a new RISC-style approach to design LLM serving API at sub-request level. Scale LLM serving with programmable cross-engine serving patterns, all in a few lines of Python.
https://t.co/fq78yU2HvH
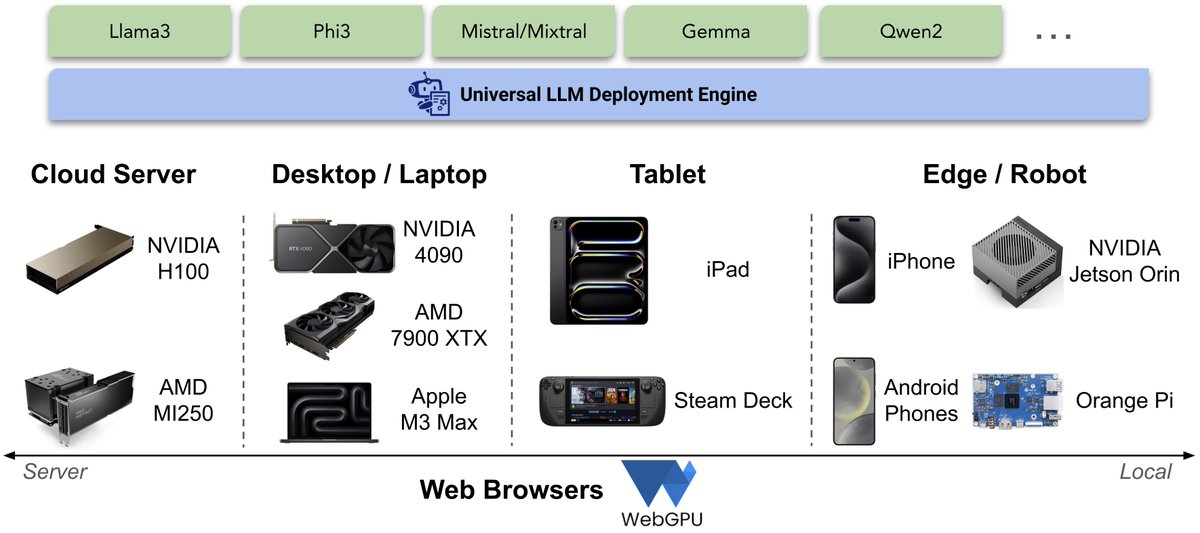
Announcing MLCEngine, a universal LLM deployment engine with ML Compilation. We rebuilt the engine with state-of-the-art serving optimizations and maximum local env portability. Fully OpenAI compatible for both cloud and local use cases. Check out the blog https://t.co/d0SqtRsBI4
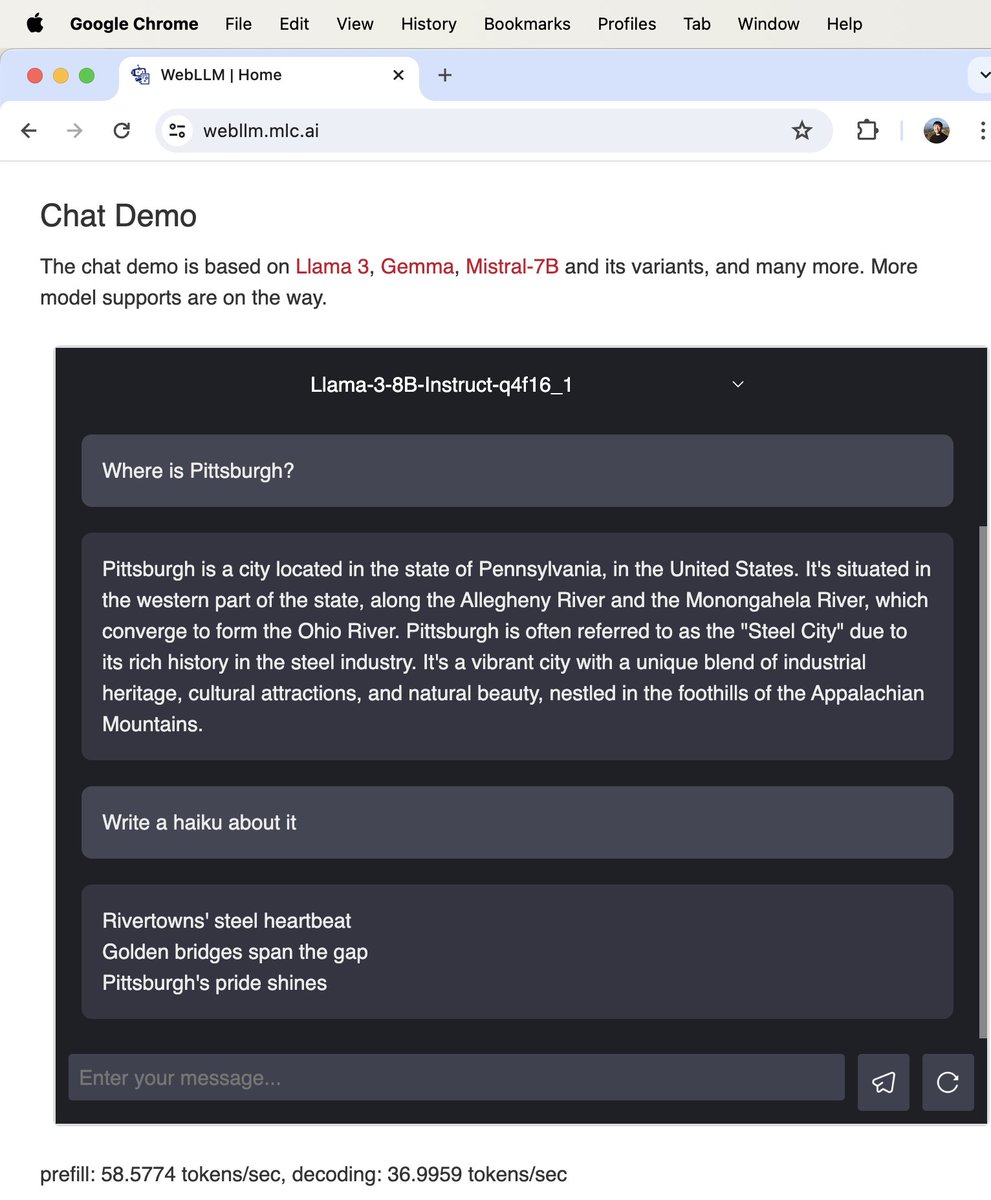
Llama 3 from @AIatMeta is now up on WebLLM!
Try it on https://t.co/NnJ7e1vPlH with local inference accelerated by @WebGPU.
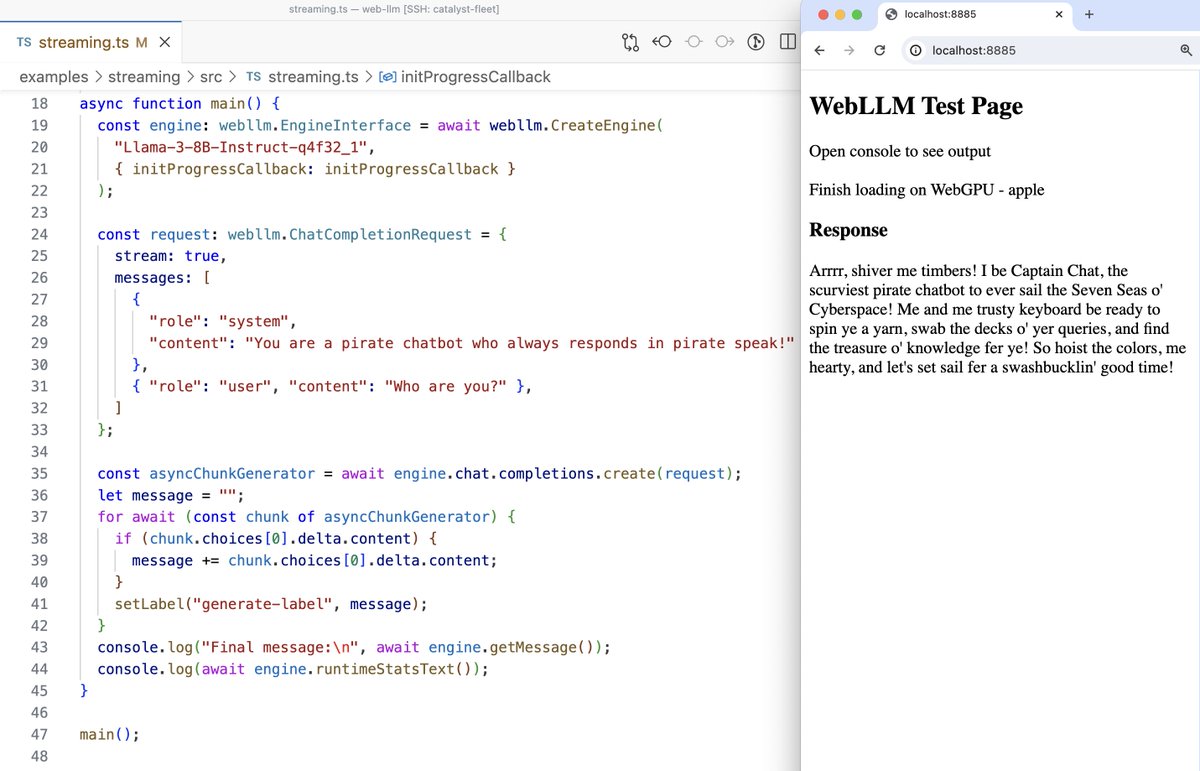
Or start building your local agent with the web-llm package -- everything in-browser!
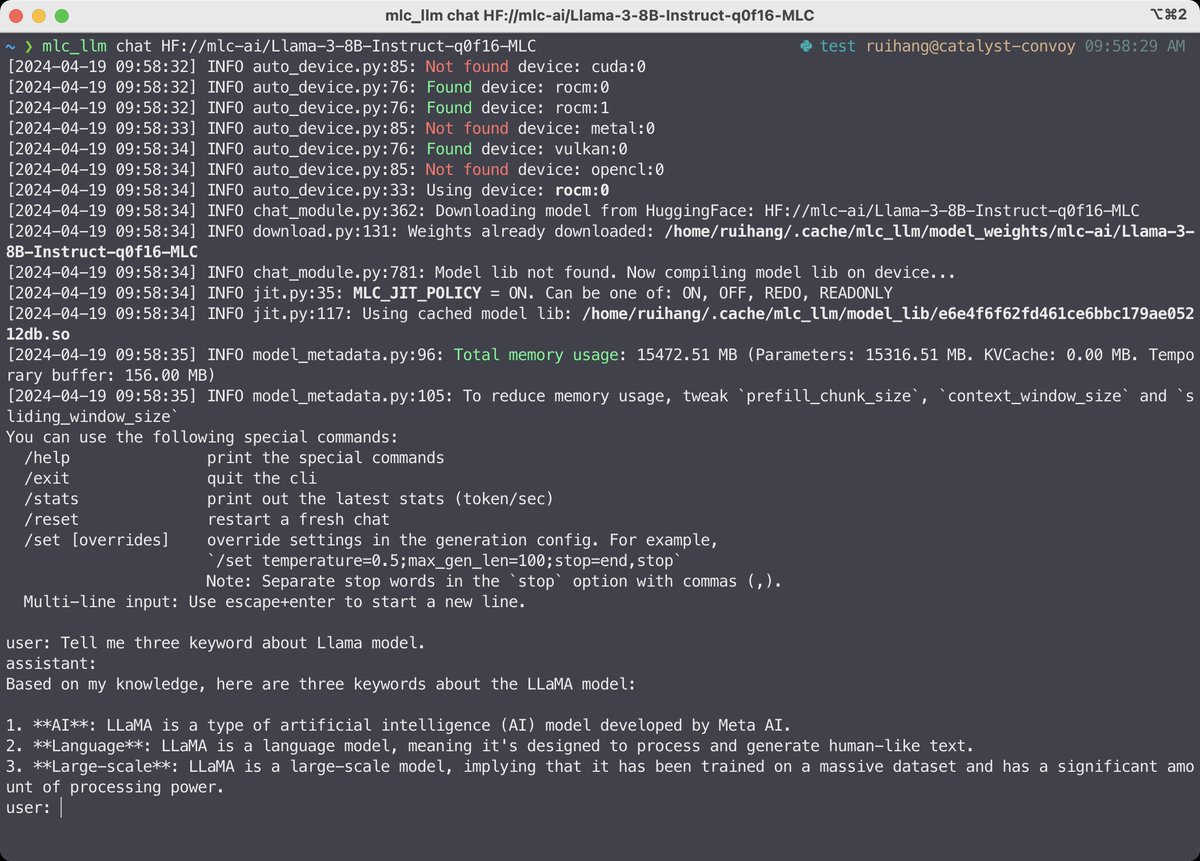
Deploy #Llama3 locally with native GPU acceleration on CUDA/ROCm/Vulkan/Metal with MLC LLM.
Check out https://t.co/xcXJlpqu5h for quick start instructions.
Please spread the words, #MLSys2024 will feature a full day single track-event young professional symposium with invited talks, panels, round tables, and poster sessions. Submit your 1-page abstract by April 1st & present your work at our poster session. https://t.co/dpTjseTZWq
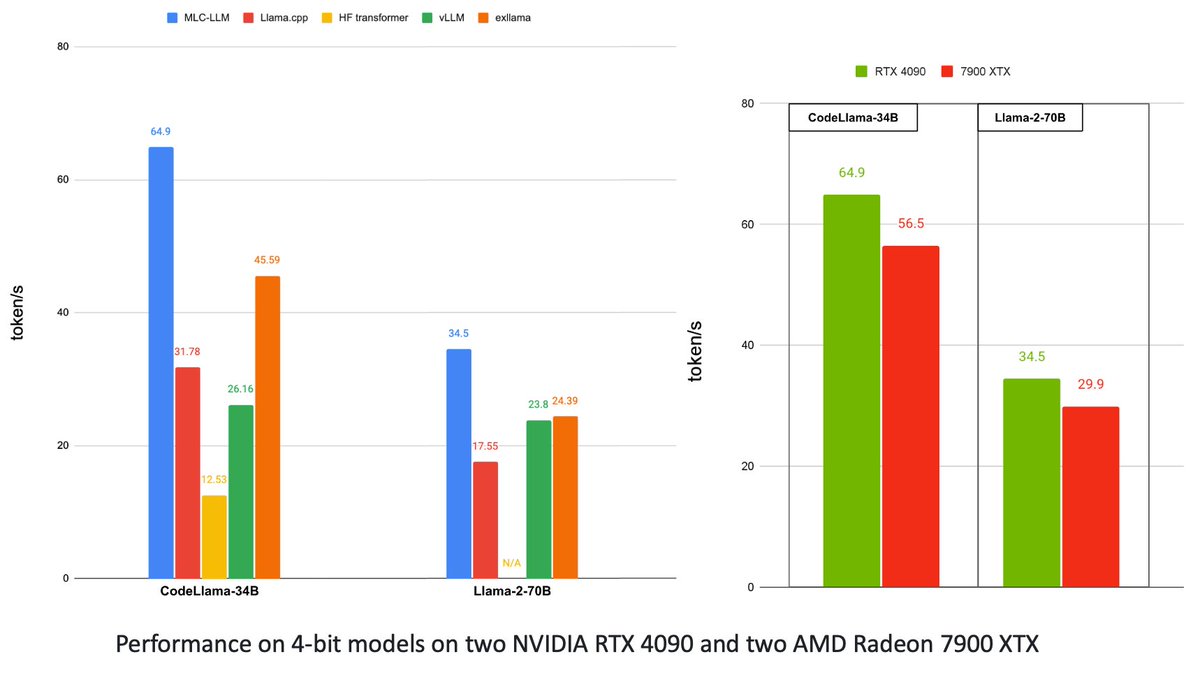
(1/3) 🦙🌟 Looking to run Llama2-70B? With two NV/AMD GPUs or more?
💥🔥 Machine learning compilation (MLC) now supports multi-GPU.
⚡️💻 We achieve 34 tok/sec on 2 x RTX 4090, the fastest solution at $3.2k.
🌐💡Two AMD 7900XTX delivers 30 tok/sec at $2k.
https://t.co/iGTHTU0xdN
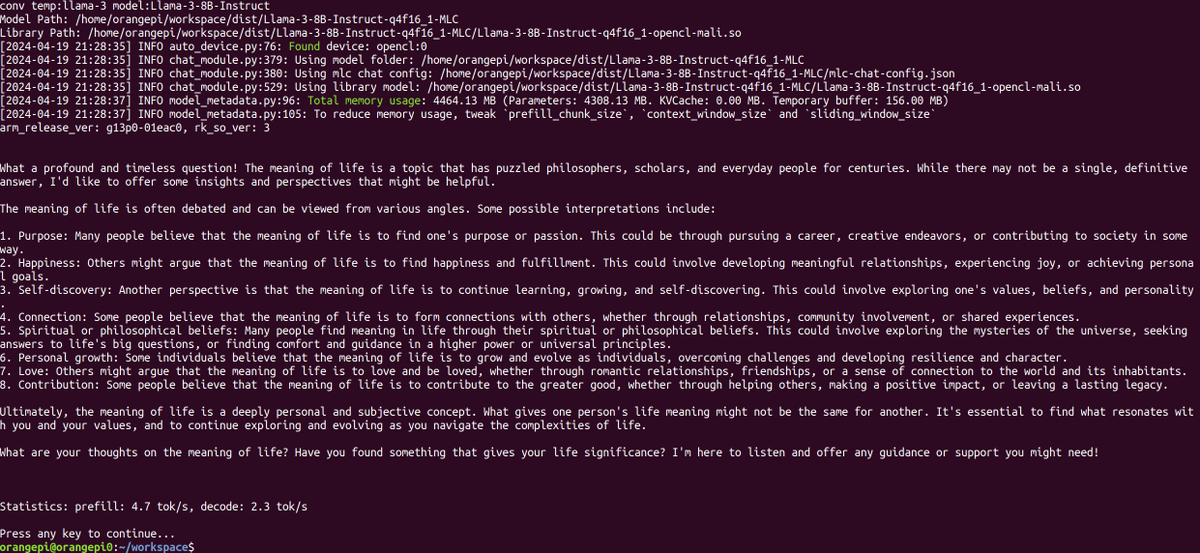
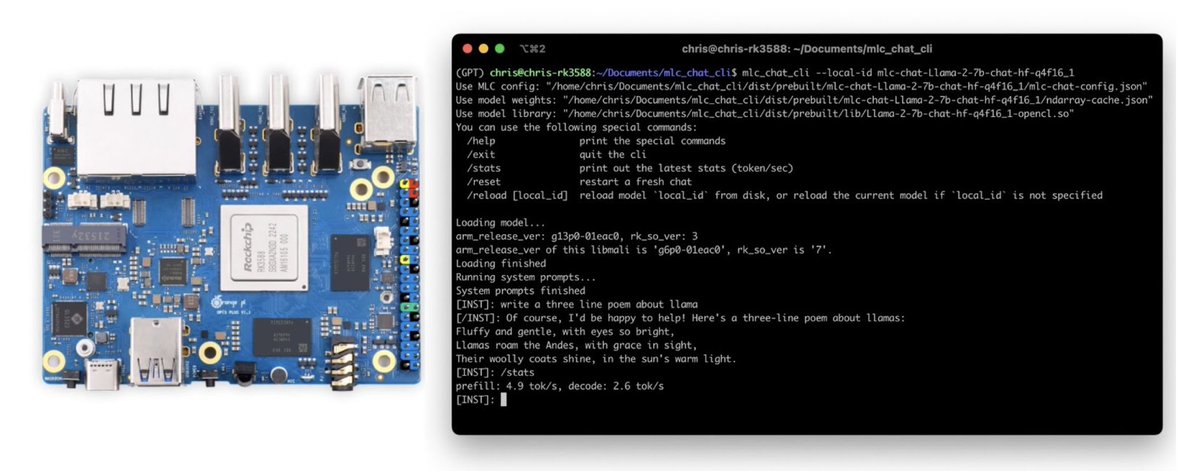
While LLM is resource hungry and challenging to run at satisfactory speed on small devices, we show that ML compilation (MLC) techniques makes it possible to actually generate tokens at 5 tok/sec on a $100 Orange Pi with a Mali GPU. https://t.co/j8a21e1EVL
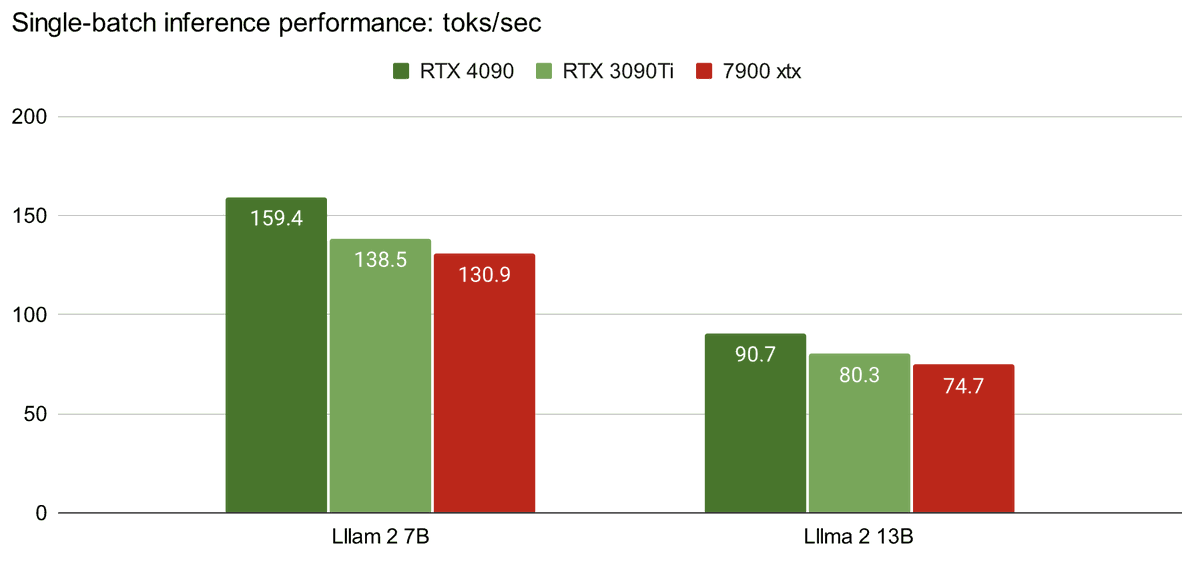
Making @AMD@amdradeon GPUs competitive for LLM inference!
130 toks/s of Llama 2 7B, 75 toks/s for 13B with ROCm 5.6 + 7900 XTX + 4 bit quantization
80% performance of Nvidia RTX 4090
See how we do this in detail and try out our Python packages here: https://t.co/IL8IFMEiQs
#Llama2 is running on iPhone, iPad📱natively with GPU acceleration. No internet connection is required.
See IOS instructions to get the test flight app now: https://t.co/dJTCjRqMWy
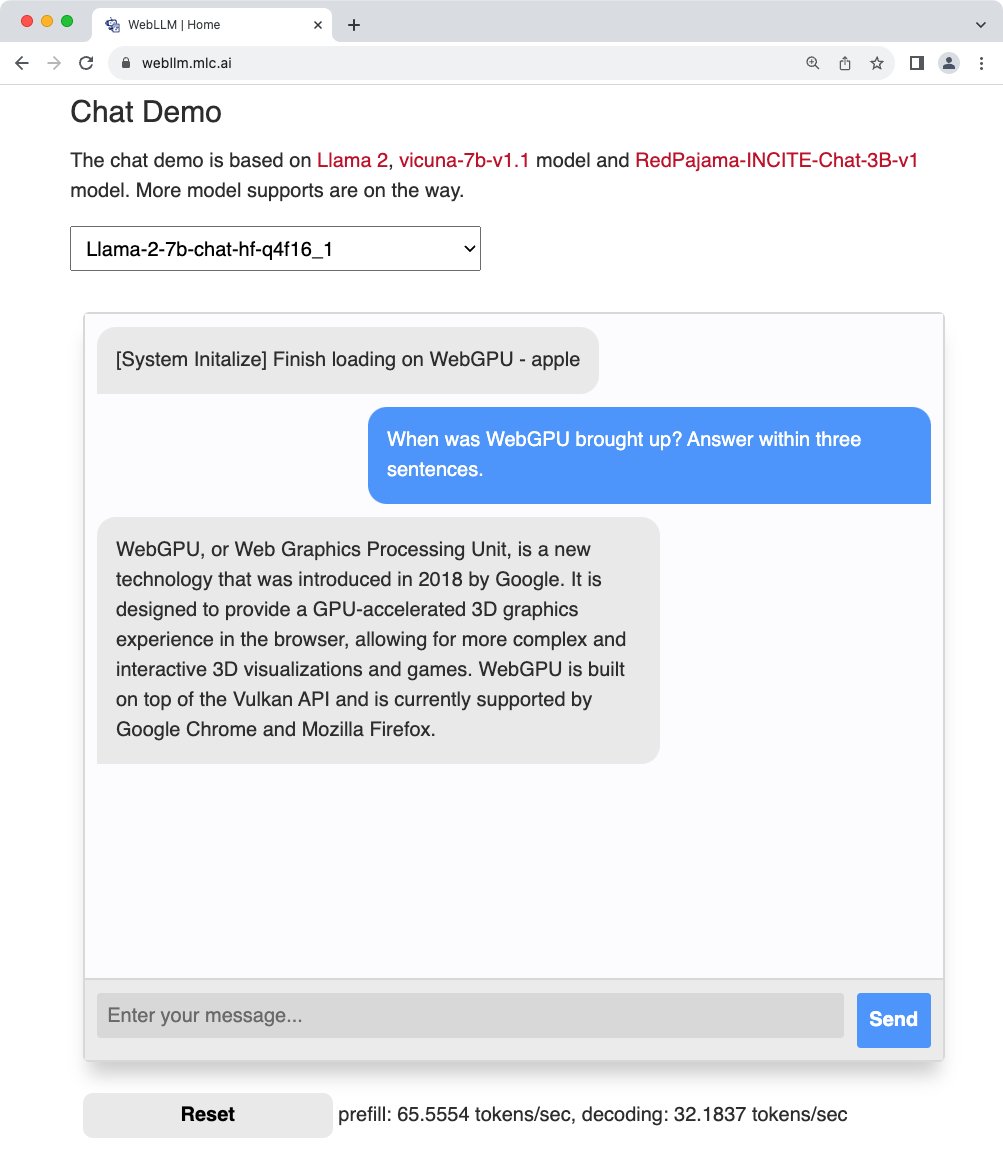
Running Llama 2 directly in web browser with @WebGPU acceleration. Try it out at https://t.co/V7smDggAB0
Build your own web app with Web LLM in 35 lines of code 👇, with npm package at https://t.co/DcGC2DfZSO