Excited to share as many details on what we @MicrosoftAI have been working on. Building a LLM from scratch is an awesome journey with pain and suffering battling unknowns but also many cool moments to see it (somehow) works out every stage! https://t.co/WTRRRRwUGu
Thanks for the question!
We didn’t try masked diffusion in our work, as this is not standard for combinatorial optimization, but would be meaningful to try for diffusion language model in the future.
The mode collapse did happen a lot, but also quite dependent on the neural architecture (like normalization helps alleviate it a lot). One of the techniques, as in my prior work, is Regularized Langevin Dynamics, https://t.co/qoPZWSraT4, where forcing a certain level of exploration could help model to escape a local optimum.
Introducing Combinatorial Adjoint Matching (CAM)🚀, a paradigm shift from Reinforcement Learning to Adjoint-Method for unsupervised discrete diffusion models!
Highlight🌟: training signals from
- a single trajectory
- the terminal gradient
No labels, no RL, no dense rewards.
🇰🇷Despite rapid progress in AI agent research, Korean agentic benchmarks remain largely absent!
To narrow this gap, we release K-BrowseComp, a benchmark that requires searching across Korean websites and Korean-language content.
https://t.co/kuHby48uif
Thanks for the question!
In fact, our original objective has already been defined as an integral. Here c_t is a cost measuring the instant KL divergence to a reference process. The objective I showed before is for practical implementation only.
For the navigation task, I would replace the second line as the direction to reduce the geodesic distance to the locally improved state at the terminal. The key spirit should be exactly the same!
Looped Transformers, Diffusion Models, and Latent Reasoning all share a powerful core mechanism: global iterative refinement.
But how do we make LTs lightweight to achieve performance AND high efficiency? Enter Linear Attention.
Check out our latest work led by @ChunyuanDeng!
Excited to introduce AdaExplore 🚀✨
AdaExplore teaches LLM agents to improve GPU kernel generation by learning from past execution failures (Adapt Stage) and searching over diverse optimization paths (Explore Stage).
With GPT-5-mini as the base model, AdaExplore achieves 3.12×/1.72× speedups on KernelBench Level-2/Level-3 within 100 evaluation steps ⚡ and outperforms existing baselines such as OpenEvolve.
Project Page & Demo: https://t.co/cGoUkg5JnV
Arxiv: https://t.co/CpyvPgFBC8
Code: https://t.co/dZFayAk3EY
More in the thread 👇
New paper: Spend Less, Fit Better
Fitting scaling laws for LLMs can cost millions💰-but what if you can get the same insights with just ~10% of the budget?
We frame scaling-law fitting as budget-aware experimental design and propose a method to pick the most valuable runs.#LLM
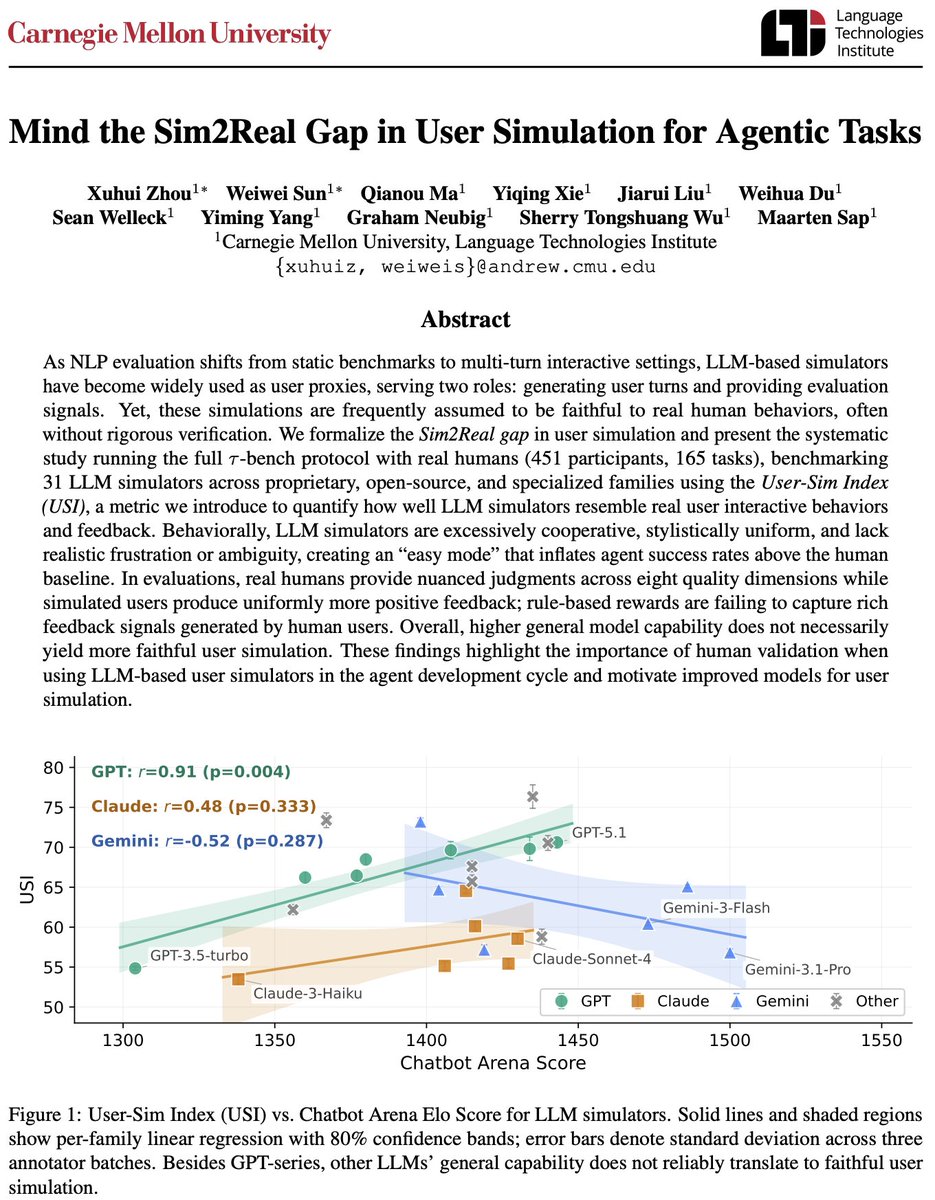
Creating user simulators is a key to evaluating and training models for user-facing agentic applications. But are stronger LLMs better user simulators?
TL;DR: not really.
We ran the largest sim2real study for AI agents to date: 31 LLM simulators vs. 451 real humans across 165 tasks.
Here's what we found (co-lead with @sunweiwei12).
Excited to announce our workshop on flow-based generative models at CMU:
Frontiers of Flows for Generative AI
March 26-27, Pittsburgh PA
https://t.co/U52Mx5vIYf
We have an amazing lineup of featured talks, panel discussions, and lightning talks. Registration is now open!