Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO + SOUL.
Paper: https://t.co/G0cEHr53h0
Code: https://t.co/6osJizwUDi
Model: https://t.co/yIAvpbKPSd
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO + SOUL.
Paper: https://t.co/G0cEHr53h0
Code: https://t.co/6osJizwUDi
Model: https://t.co/yIAvpbKPSd
Exactly, we have similar findings in our new work!
Many OPD variants actually collapse in our setting, which partially drove to DITTO: a more straightforward way to let the teacher actively "work" on the task, then have the student better learn from that.
https://t.co/PjXF9GX9cf
@shwiy1558125 Totally agree! LLM simulators are already quite useful in controlled settings like entertainment / data generation. For higher stakes use cases we may need more careful validation against real human data
@techietaro Good point! We’ve seen our method reach SOTA on many theory-of-mind tasks too, and we’re actively expanding to more evaluations. Verbal feedback can also be a pretty useful hint for guiding the model’s reasoning
Excited to share our new work on Reinforcing Human Behavior Simulation via Verbal Feedback.
Can human simulators learn from feedback, not just rewards?
Most RL for LLMs turns feedback into a single score. But human behavior is rarely just right or wrong. It is social, contextual, subjective, and multi-dimensional.
A score can tell the model what is better. Verbal feedback can tell it why.
Meet DITTO + SOUL.
Paper: https://t.co/G0cEHr53h0
Code: https://t.co/6osJizwUDi
Model: https://t.co/yIAvpbKPSd
Wondering how we can better simulate human behavior with reinforcement learning?
Introducing DITTO: RL with verbal feedback for subjective tasks like user simulation, student modeling, character role-play, and theory of mind.
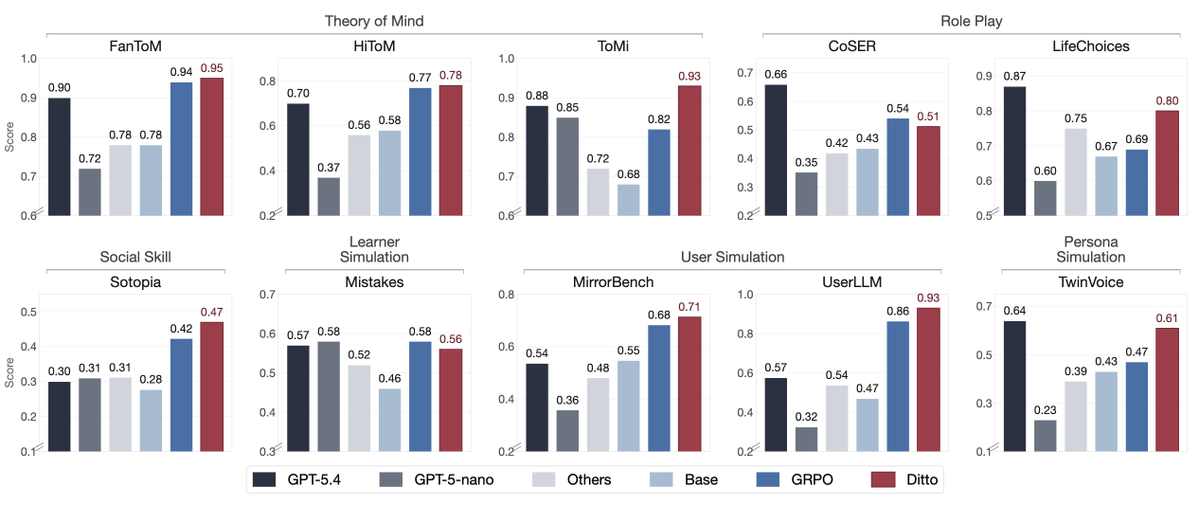
The result: an 8B model that performs on par with GPT-5.4 on the new SOUL benchmark suite.
Results: with an 8B model, DITTO improves over the base model by 36% on average, outperforms standard GRPO on 8/10 SOUL tasks, and matches or exceeds GPT-5.4 on 6/10 benchmarks.
The takeaway is simple: to train human-like simulators, we need training signals that are more human-like too.
Excited to share our new paper 🧵MIXSD: Mixed Contextual Self-Distillation for Knowledge Injection
Supervised fine-tuning is the common way to teach LLMs new knowledge, but it often catastrophically forgets existing capabilities. We introduce MixSD: a simple, external-teacher-free method to inject knowledge with far less forgetting.
📄https://t.co/qRpaTiI9EU
Why does SFT forget? Targets written by humans or external systems diverge from the model's own autoregressive distribution, forcing the optimizer to imitate low-probability tokens. That's what drags pretrained capabilities down.
MixSD: We hypothesize that keeping supervision close to the model's own distribution is key to avoiding forgetting. Instead of training on fixed, externally authored targets, at every token we mix between two conditionals of the base model itself: an expert conditional that sees the injected fact in context, and a naive conditional reflecting the model's prior. The result is supervision the model already finds high-probability, while still carrying the new factual signal. A Bernoulli rate λ controls the balance between memorization and retention.
Findings: SFT only retains as little as 1% of held-out capability. MixSD retains far more, up to ~100% on larger models, with near-perfect training accuracy. It also beats on-policy self-distillation at a fraction of the compute, and holds across Qwen3 1.7B, 4B, 8B and Llama-3.2.
Sub-agents are a promising inference-time scaling primitive:
• Expand an agent's working memory
• Divide-and-conquer hard problems
• Solve problems faster with parallel execution
But how do we train a model to best take advantage of sub-agents and make sure we get these benefits?
Very excited to release RAO: Recursive Agent Optimization.
RAO is an end-to-end reinforcement learning approach for training LLM agents to spawn, delegate to, and coordinate with recursive copies of themselves (that can themselves spawn other agents) - turning recursive inference into a learned capability.
1/10
Introducing XGrammar-2: structured generation for complex agent harnesses.
Strict tool-calling formats. Built-in DeepSeek-V4 and Qwen-3.6 support. Up to 80x speedup over XGrammar. Ready-to-use integrations with vLLM, SGLang, TensorRT-LLM, and more! ⚡
From Claude Code to OpenClaw, agents are defining more complex harnesses. XGrammar-2 ensures LLMs always interact with them in the right way.
Built in collaboration with DeepSeek, Databricks, and leading frontier AI labs to bring XGrammar-2 into latest models and products.
🧩 Structural Tag: one unified abstraction to describe any format your agent needs
🚀 Scales to 500+ strictly typed tools for complex agent harnesses
🌐 Native APIs in Python, C++, Rust, and JS, running everywhere from cloud to edge
🛠️ Integrated with vLLM, SGLang, TensorRT-LLM, and more
Excited to see what agent builders create with it!
Blog: https://t.co/N0Tbl588BH
GitHub: https://t.co/lo4yScuI2f
Context engineering is key to building LLM agents. Can we let agents actively manage their own context?
We introduce Context-Folding, giving agents the ability to branch and compress their context.
Trained with RL on Search and SWE task, it beats ReAct using 10× less context.