Introducing Nex-N2 — true Agentic Thinking, built with @NexEcosystem 🚀
Thinking is now standard in foundation models, but it sits in an awkward position in Agent tasks: either the performance gains aren't significant, or it's verbose, and switching scenarios means readapting all over again. The root cause is that thinking from the o1/R1 era was built around RLVR for math and code tasks, not for long-horizon Agent tasks—there's a layer of separation between thinking and action.
Nex-N2 introduces a complete Agentic Thinking framework, split into two parts: Adaptive Thinking and Coherent Thinking. The former achieves adaptive reasoning intensity, improving speed (which really matters in long-horizon tasks spanning hundreds of steps) and saving unnecessary token expenditure. The latter unifies thinking patterns across different tasks, making actions more stable, consistent, and robust.
- Adaptive Thinking, auto-scales reasoning depth per step. Saves ~20% tokens, zero performance loss.
- Coherent Thinking, one thinking paradigm across search, coding, and tool use. No more fragile mode-switching.
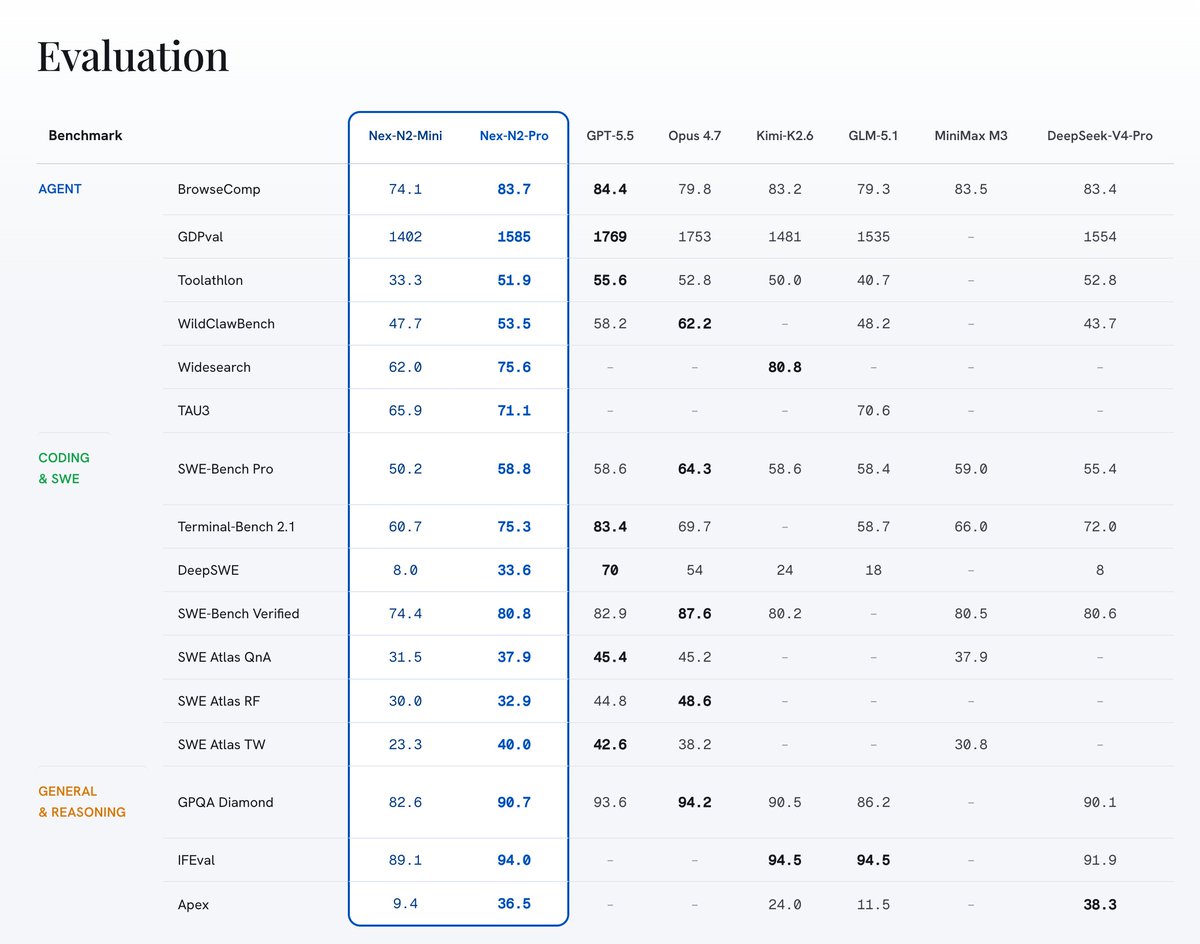
On coding and Agent tasks, Nex-N2 ranks in the top tier of open-source models. The model is fully open-sourced and available simultaneously on Hugging Face, ModelScope, and SiliconFlow. We welcome everyone to try it out.
Official website: https://t.co/8j4ZvLAQZt
Huggingface: https://t.co/UEx20Th3wQ
@_m0se_ It seems in hybrid models linear and full attentions take on different roles as full attentions capture long term dependencies more easily leaving linear attention to focus on local mixing.
This is growth-hacking dressed up in open-source language, @radixark please stop doing it immediately.
Paying people in platform credits to star a GitHub repo and repost a marketing tweet isn't "fueling the community" — it's laundering paid promotion through the trust signals open source depends on. Stars are supposed to mean someone found a project useful. Attach a $200 bounty and the number means nothing. GitHub's own policies prohibit this for exactly that reason.
New modded-NanoGPT optimization benchmark result: @wen_kaiyue has improved upon both the Muon and AdamW baselines, by replacing their weight decay with hyperball optimization. The new record is 3325 steps.
The massive kv cache reduction of deepseek may unlock agent scaling as an economical choice...Imagine defaulting to 4 parallel agents solving one of your problem with each agents calling 10~20 subagents in parallel to explore different choices.
@_ueaj it may be due to increased parameters instead of increased kv cache rank from enlarged projections. What if you enlarge MLP layers for smaller kv cache rank models to balance the two models' params? Or do an mlp style expansion in projections?
@facontidavide I suggest checking the code rigorously for hacking perhaps by asking another code agent like codex to do it. They have very creative ways to game the benchmark and get high scores.