We use previous generations of Composer to train future ones.
Our autoinstall system has earlier Composer models set up dev environments for RL training. That way, the next generation can focus on learning to solve harder problems.
https://t.co/GbZILEfhAt
SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI.
The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models.
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
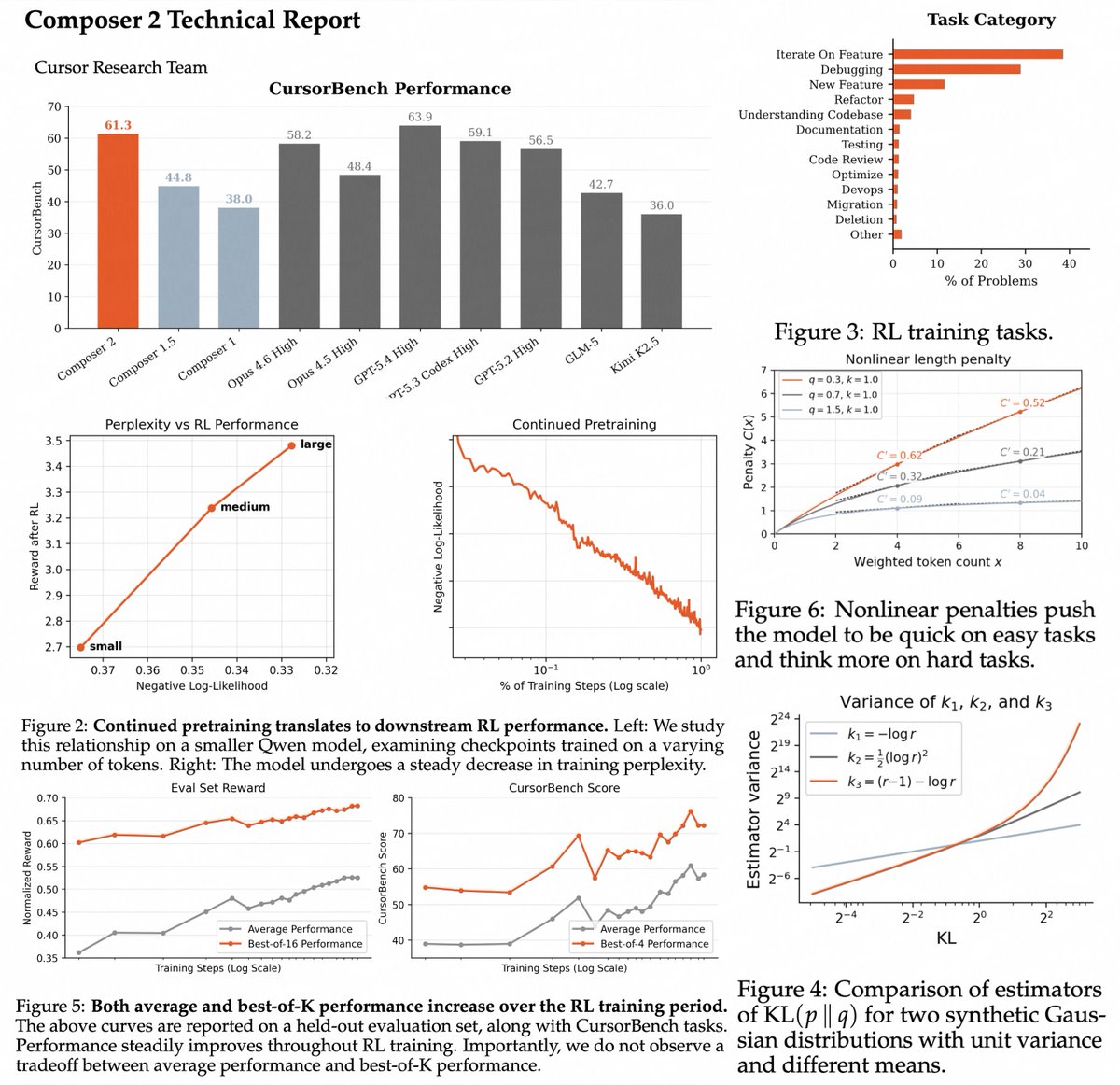
Earlier this week, we published our technical report on Composer 2.
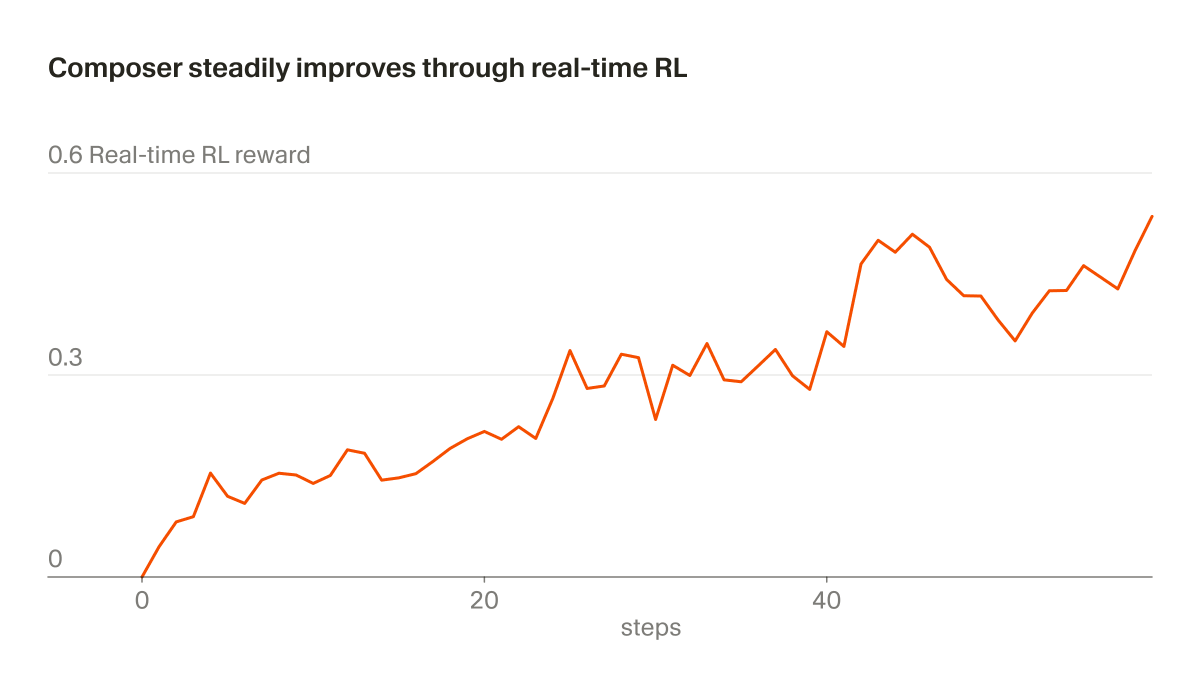
We're sharing additional research on how we train new checkpoints. With real-time RL, we can ship improved versions of the model every five hours.
cursor composer 2 tech report is VERY VERY nice
some of the things i found interesting:
> nice "scaling" study of how rl performance is impacted by continual pretraining (more flops => lower ppl => higher RL perf)
> they added mtp head to k2.5 for speculative decoding, they use self distillation objective which is not standard i think for mtp training
> they added length penalty RL to force the model to think more on long tasks and less on easy ones
> they use self summarization (introduced in a previous blog post). cursor mentions the model has a 200k context window but the tech report mentions ctx extension to 256k, so it means they reserve 50k for the compaction/self summarization? it's a bit higher than the 33k token in claude code.
> nice that they report improvement on both best of k and average perf
> very very nice infra section on kernels, parallelism, quantization and muchhh more (i need to read this more in depth!)
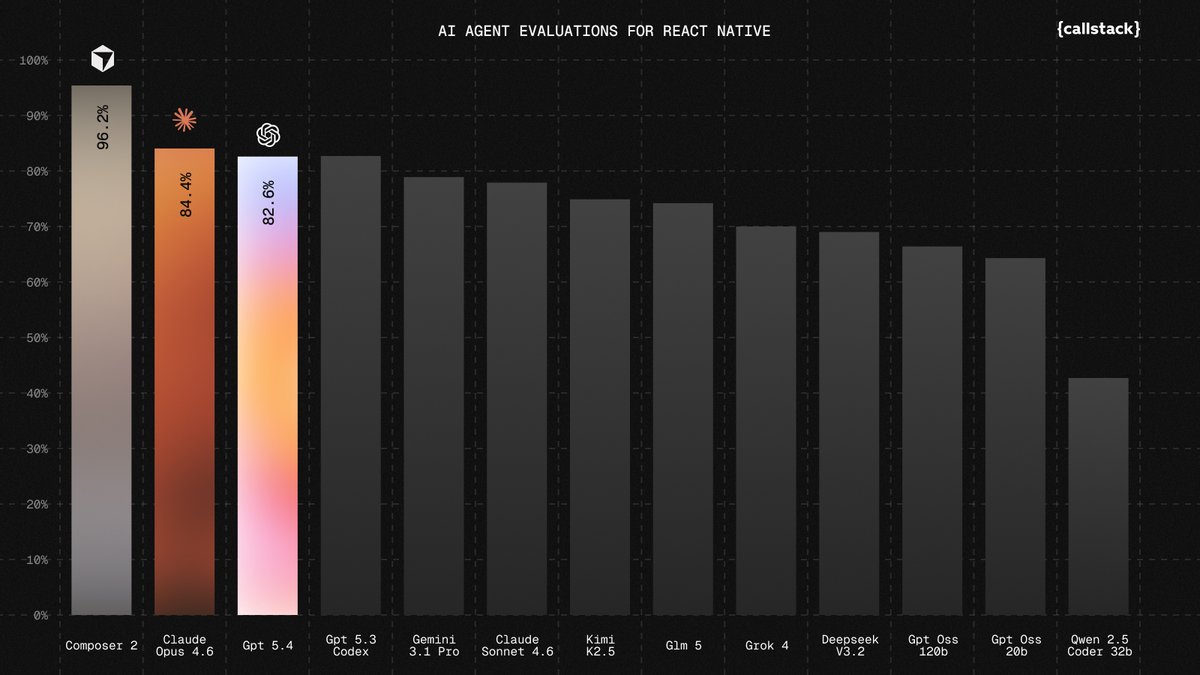
Cursor's Composer 2 just took second place on the Next.js evals leaderboard, beating both Opus and Gemini.
See the full rankings ↓
https://t.co/9lEr5K7lUT
Composer 2 marks the one-year anniversary of our large model training efforts. Since then, we've built an exceptionally talent-dense team of ~40 people with some of the best researchers and engineers from the labs, academia, industry, and more heterogeneous backgrounds.
And we are exclusively focused on coding. We don't care about models that can respond to emails, do your tax returns, or be your friend.
Every FLOP, token, parameter, and researcher is entirely dedicated to software engineering.
New post: how we do evals at @cursor_ai. Takeaways:
1. Online metrics from real Cursor requests provide construct validity
2. CursorBench: a dynamic offline suite distilled from online learnings
3. Multi-axes evals -- correctness, efficiency, agent interaction behavior
Composer-1 required an enormous amount of science, infra, ML perf, and data/reward work to build. And far more ahead of us!
We're growing our small and exceptionally talent-dense RL team. Join us, to shape the future of coding!
One personal reflection is how interesting a challenge RL is. Unlike other ML systems, you can't abstract much from the full-scale system. Roughly, we co-designed this project and Cursor together in order to allow running the agent at the necessary scale.
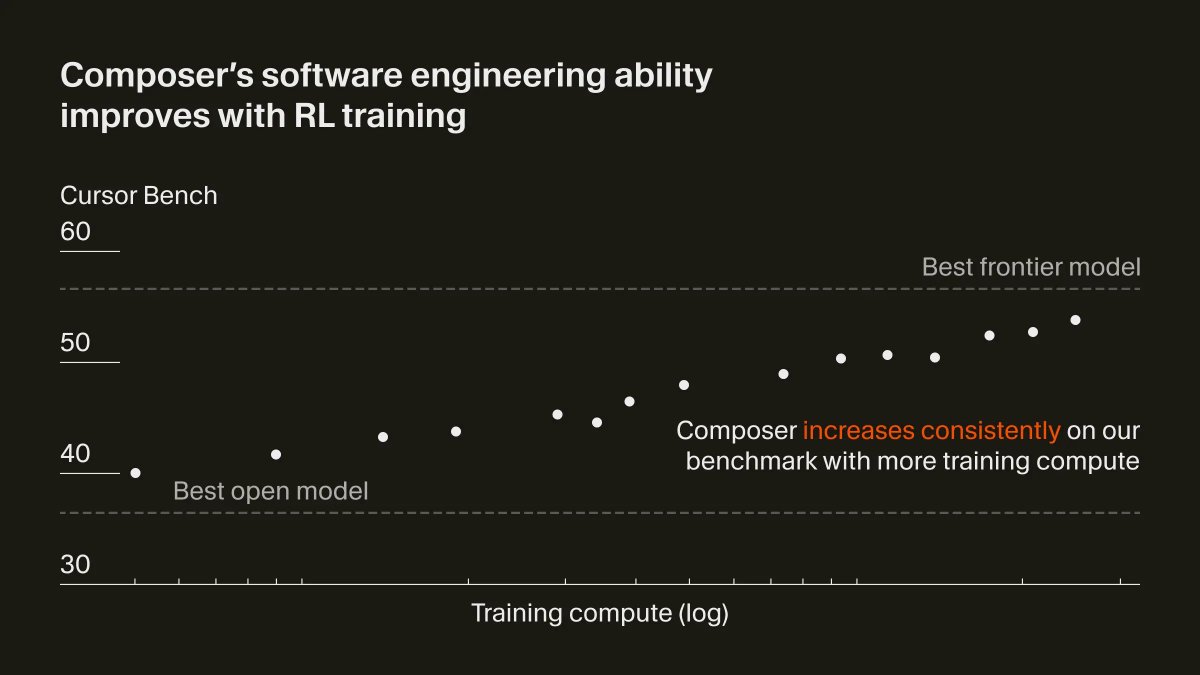
Composer is a new model we built at Cursor. We used RL to train a big MoE model to be really good at real-world coding, and also very fast.
https://t.co/DX9bbalx0B
Excited for the potential of building specialized models to help in critical domains.