Most teams use separate tools for analytics, observability, and Web Vitals.
Raah combines all of it together with user-side logs.
What you get:
→ Real user traffic + Web Vitals
→ API & page latency
→ ISP-level diagnostics
→ Session data
→ User- Journey
→ AI chat that answers based on your data
Plug with your Coding Agents
One simple script for setup.🔥
Try now → https://t.co/Fs2vkMY6L8
Your observability bill shouldn't cost more than your infra.
That's why we built @raahdotdev
Analytics and observability for your website, in one place.
Try Now: https://t.co/HEkl3tX08R
Today we're launching Raah.
Analytics and observability for your website, in one place.
→ Real traffic, errors, and Core Web Vitals from actual users
→ Page and API latency tracking
→ Session replays
→ An AI Chat that tells you what's broken based on your production data
Try Now: https://t.co/XVQdFbhx4B
Today we're launching Raah.
Analytics and observability for your website, in one place.
→ Real traffic, errors, and Core Web Vitals from actual users
→ Page and API latency tracking
→ Session replays
→ An AI Chat that tells you what's broken based on your production data
Try Now: https://t.co/XVQdFbhx4B
.@NVIDIAAI dropped Cosmos3 Super Reasoner yesterday.
So I built a debate council where the model argues with itself 🪐
Give it any motion:
• Advocate argues FOR
• Skeptic argues AGAINST
• Pragmatist stress-tests both
• Arbiter scores and delivers a verdict
Built with @LangChain + @nebiustf + @streamlit
Each round feeds into the next. Real rebuttals, not parallel monologues.
100% Open Source!
Everyone's building personal agents. But they're solving the wrong problem.
We've seen it with OpenClaw going viral, Hermes agents, all these harnesses popping up that let you run your own agent.
But everyone is missing one very important thing!
The harnesses are solid. The models aren't personalized. That's the actual bottleneck.
Every person uses agents differently. Different tasks, different workflows, different preferences. Your taste matters here.
If you want a truly personal agent, the harness is only half of it. The LLM itself needs to be tuned to how YOU work.
I think we're headed toward a future where personalized LLMs become the norm. Not just generic models with fancy wrappers.
Open-source models are closing the gap fast. The infrastructure is there.
So, how do you personalize your model?
Your inference logs.
That's it. Every interaction you have with the model, every way you prompt it, every task you run. It's all sitting there in your logs.
You can take that data and fine-tune directly on it.
This makes building a real personal agent way more practical than people think.
Your best dataset is already in your logs.
Data Lab is live in Nebius Token Factory: explore inference logs, filter production signal, and turn it into reusable datasets for post-training.
Model improvement should be a loop, not a cleanup project.
👇
Built a real-time voice agent that listens and responds instantly.
- @SarvamAI STT for speech input
- GPT-OSS via @nebiustf for processing
- Sarvam TTS for voice output
Wired everything together with @pipecat_ai into one streaming pipeline.
Runs locally. No complex setup.
Full tutorial:
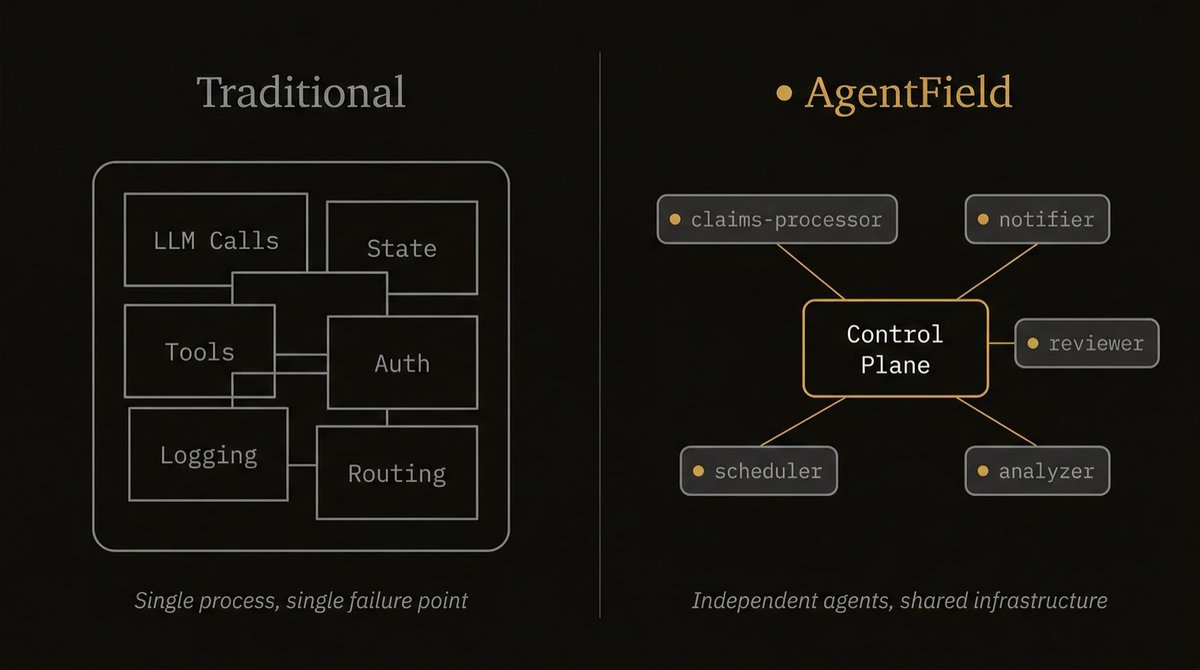
I was going through AgentField today.
Interesting idea.
Instead of building messy agent pipelines, you define agents as typed Python functions, and the framework turns them into callable APIs.
Infrastructure handles routing, identity, async execution, and logs.
Feels closer to backend engineering than prompt hacking.
Had a great time speaking at @gdgkolkata's Build with AI event yesterday.
Built a voice agent with web access using @livekit, @GeminiApp & @olostep.
The energy in the room was amazing. People were genuinely excited about the possibilities.
Here's the demo I showed:
I'll be speaking at Build with AI Kolkata by @gdgkolkata tomorrow.
Will walk through building real-time voice agents with Gemini 3.1 Flash + Livekit that process audio directly for natural flow
📅 Apr 25 | 9:30 AM IST
📍 SNU, A Block Seminar Hall
See you there!