Founding Engineer at Sumble. Senior ML Research Scientist at Meta. CS PhD at UIUC. Previous DL intern at LinkedIN. Deep Learning. Natural Language Processing.
Looking at job posts over the last year, it looks like Amazon is making the broadest AI investment. 228 teams across the company posted jobs with GenAI projects over the past year, considerably more than any other company. https://t.co/aOYjKfD6OJ
Most interest is the breadth of teams and use cases. They made posts from the core research teams, Alexa, customer service, seller experience, fulfillment, and catalog selection teams (full list: https://t.co/1UnE6iY9IE).
Some examples:
- Creative X Team: generating high-quality text, images and video for advertisers (https://t.co/ymi1eMXrba)
- Geospatial Science Team: for global address parsing and validation (https://t.co/UtSm8AX6DD)
- Selection and Catalog Systems Team: improve the completeness and correctness of product data for Amazon shoppers (https://t.co/3Ll3SYFYli)
The overlooked GenAI use case: cleaning, processing, and analyzing data.
https://t.co/j9hFXWJvvF
Job post data tell us what companies plan to do with GenAI. The most common use case is data analytics projects. Examples:
- AstraZeneca: using LLMs on freeform documents to structure results from their Extractables & Leachables testing (https://t.co/wbamJnQEEN)
- Trafigura: The Document AI team is using LLMs to extract data from a corpus of commodity trading documents to generate credit reports
(https://t.co/mujn0ksa90)
The startup ecosystem is overlooking this use case, instead focusing on other areas such as customer support, sales & marketing and code gen.
Apply using the links shared below, or if you know talented engineers or data people who could be a great fit, I would appreciate referrals.
https://t.co/K1LNzIekq3
https://t.co/SfvlZquPVO
📷
We're hiring several backend/data/ML engineers for our new(ish) company Sumble, which is focused on building high-quality structured data from raw, noisy inputs.
We have a founding engineering team of 7, which we built over the past year. We have funding, revenue, and users, and we just hit milestones that make us want to move faster.
I've seen many reports of people struggling to finetune Gemma. We are using Alpaca-style instruction formats over conversational style and we are now getting superior performance out of Gemma-2b compared with Mistral-7b for our NER task (see screenshot to see our task).
The approach was inspired by @maximelabonne https://t.co/E3hJh0alLO
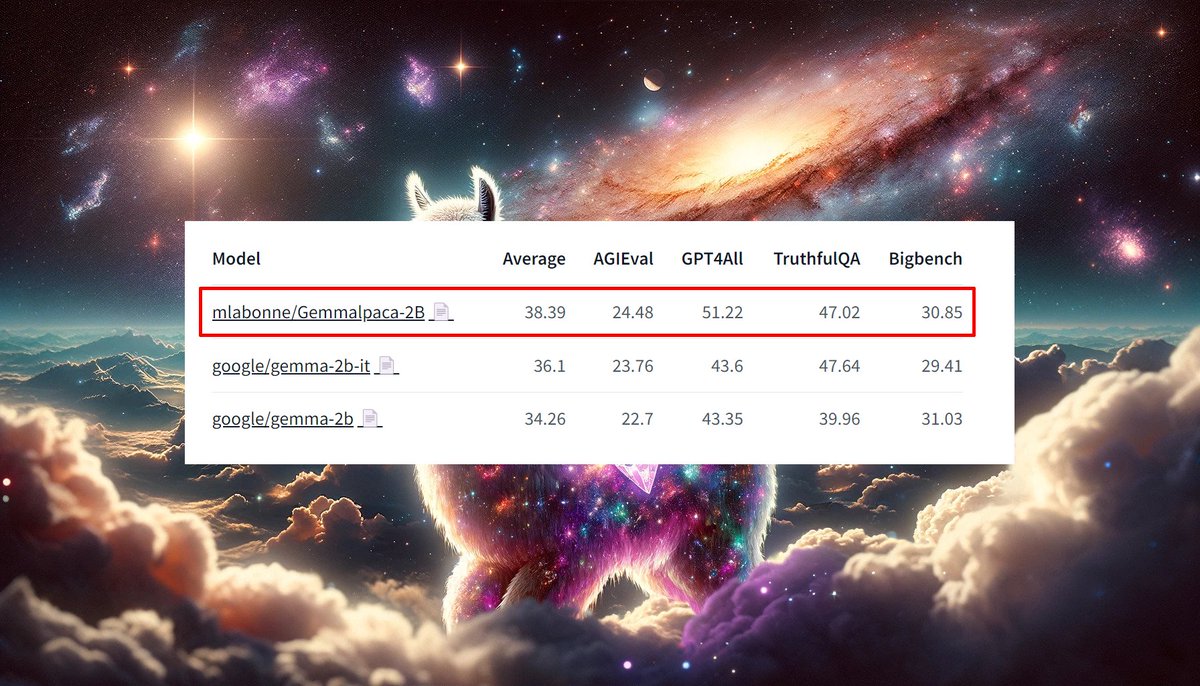
💎 Gemma + Alpaca > chat model
The chat model (gemma-2b-it) looks pretty bad, so I ran a quick experiment and retrained gemma-2b on the Alpaca dataset.
It's only 52k samples but it already shows better performance on Nous' benchmark suite. Looks quite promising for the Gemma models.
🤗 Model: https://t.co/96I7V8zoCU
📊 Leaderboard: https://t.co/GnqMupLIQR
I've seen many reports of people struggling to finetune Gemma. We are using Alpaca-style instruction formats over conversational style and we are now getting superior performance out of Gemma-2b compared with Mistral-7b for our NER task (see screenshot to see our task).
The approach was inspired by @maximelabonne https://t.co/E3hJh0alLO
A conversation style tuning format as adopted in UniNER(https://t.co/X6TrXcJnQG) project seems to confuse Gemma. We use an instruction format instead as shown in the attached screenshot below.
We assume inference cost improvements are because of the smaller model size.
And assume increased performance on Asian languages are due to Gemma’s vast vocabulary which leads to fewer tokens for Asian languages(Gemma: 158 vs. Mistral: 272 for Japanese text in previous screenshot). Denser inputs and better representation in the transformer as pointed out by @karpathy (
https://t.co/IOai7MiQbH)
New (2h13m 😅) lecture: "Let's build the GPT Tokenizer"
Tokenizers are a completely separate stage of the LLM pipeline: they have their own training set, training algorithm (Byte Pair Encoding), and after training implement two functions: encode() from strings to tokens, and decode() back from tokens to strings. In this lecture we build from scratch the Tokenizer used in the GPT series from OpenAI.
1/ In 2021, we shared next-gen language + conversation capabilities powered by our Language Model for Dialogue Applications (LaMDA). Coming soon: Bard, a new experimental conversational #GoogleAI service powered by LaMDA.
https://t.co/cYo6iYdmQ1
What if you could talk to the Bible?
Try now: https://t.co/sL7dtiyneD
Describe your situation or ask a question! Cites specific verses from the Bible. Works in English and Spanish.
Made with @OpenAI and domain via @Porkbun!
#biblegpt#chatgpt#gpt3