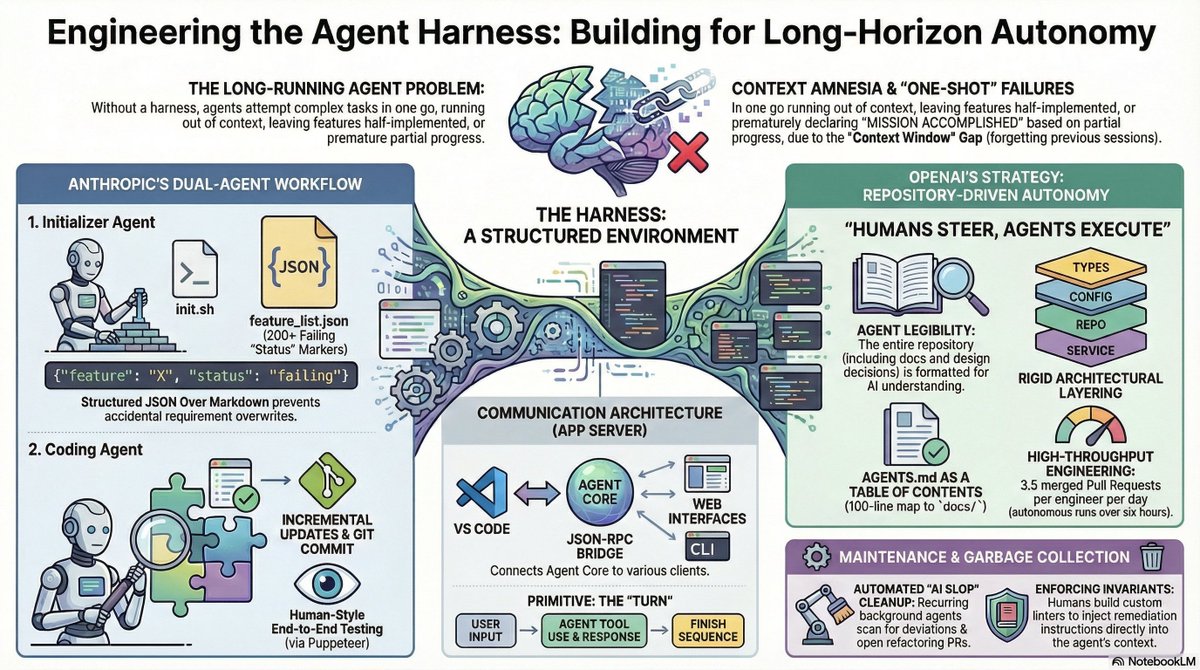
Everyone's debating which model codes better. Meanwhile OpenAI and Anthropic both dropped guides on the same thing: harness engineering. The model isn't the bottleneck. Your scaffolding is.
🧵
UPDATE: Came up with an even better version of this prompt after the feedback
Ask Codex to look across your sessions, Memories, and Chronicle, identify patterns, reuse what already exists, and only create the smallest useful skill, subagent, or automation.
"Look back over my recent work from the last 30 days, or all available history if shorter, and identify repeated manual workflows worth packaging.
Use available evidence in this order:
- Recent Codex sessions and task summaries.
- Codex Memories and rollout summaries to find patterns repeated across sessions.
- Chronicle, if enabled, to spot repeated work outside Codex. Use Chronicle for discovery only; confirm important details in the relevant source system when possible.
- Existing skills, custom agents, and automations, so you reuse or extend what already exists instead of duplicating it.
Look broadly for work that is repeated, time-consuming, error-prone, context-heavy, or benefits from a consistent process. Include workflows across coding, research, writing, planning, communication, operations, analysis, and personal administration.
Only act on a candidate when it:
- occurred at least twice, or is clearly likely to recur and costly to repeat;
- has stable inputs, a repeatable procedure, and a clear output or stopping condition;
- would materially improve speed, quality, consistency, or reliability;
- is not already adequately covered.
Choose the smallest appropriate form:
- Skill: a reusable workflow or playbook.
- Custom subagent: a bounded specialist role or investigation task suitable for delegation.
- Automation: a scheduled or recurring check, report, reminder, or monitor.
- Skip: work that is too one-off, ambiguous, sensitive, or poorly evidenced to package.
First produce a compact shortlist with:
- repeated workflow
- supporting evidence and dates
- frequency/confidence
- recommended form: skill, subagent, automation, extend existing, or skip
- why it is or is not worth creating
Then create only the high-confidence missing items. Keep them narrow, practical, source-aware, and easy to validate. Do not create speculative, overlapping, or overly broad assets.
Finish with:
- what you created or extended
- what you deliberately skipped
- what needs more evidence before packaging"
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
You can now ask Gemini to create Docs, Sheets, Slides, PDFs, and more directly in your chat. No more copying, pasting, or reformatting, just prompt and download.
Available globally for all @GeminiApp users.
“most people could comfortably manage three to five sessions at a time before context switching became painful. Beyond that, productivity dropped”
https://t.co/AaCqBi4qj4
ACE just showed us the future of AI engineering.
No more one dev + 20 isolated agents creating chaos.
GitHub Next built the missing piece: realtime multiplayer agents in shared sandboxes with Slack-style chat + GitHub-style versioning.
This is how serious software gets built when agents scale.
@Mappletons nailed it 👇
🆕Collaborative AI Engineering: One Dev, Two Dozen Agents, Zero Alignment — @mappletons
https://t.co/7SEayJwZLe
Agentic engineering so far has been a solo story: one developer and a dozen agents moving at warp speed. But speed without thoughtful planning and team alignment is just wasting tokens. When everyone on a team is directing agents alone in their personal CLI tools with no shared context, you get duplicate work, conflicting changes, poorly-designed solutions, surprise features nobody else agreed to build, and everyone pulling in different directions.
Serious software still requires serious collaboration. You need multiple perspectives and types of expertise to build great things. We need agentic environments where people can plan together, think critically together, and share the same context. In this talk I'll demo how we've tackled these design problems in Ace, a multiplayer agent environment from GitHub Next that uses real-time collaboration, proactive agents, and sandboxed micro VMs for rapid prototyping and exploration.
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
That’s the one cool feature: each Droid gets its own forever-running computer that actually remembers files, credentials, and context instead of resetting every time
Today we're opening access to Droid Computers: persistent machines for remotely orchestrating Droids.
Spin one up in Factory's cloud or turn your machine into a Droid Computer. Either way, Droids have a dev environment with its own filesystem, credentials, and configurations.
The Local LLM cheat sheet for your 16GB RAM device
I pulled together a lineup of small models that can run comfortably on a Mac Mini or personal laptop while still leaving room for context without melting your machine.
Models for Daily Use
Qwen3.5 9B / GGUF / Q4_K_M
Daily driver. General chat, drafting, research, translation. If you're keeping only one, keep this.
DeepSeek-R1 Distill Qwen 7B / GGUF / Q4_K_M
Reasoning engine. Math, logic, step-by-step problems. Slower, but worth it when you need actual thinking.
Models for Specialty Work
Qwen2.5 Coder 7B / GGUF / Q4_K_M
Code specialist. Completions, refactors, debugging, repo Q&A. Better than a generalist when the task is code.
Llama 3.1 8B / GGUF / Q4_K_M
Long context worker. RAG, doc chat, codebase Q and A. The output isn't top tier, but the context is strong for its size.
Phi-4 Mini Reasoning / GGUF / Q4_K_M
Compact thinker. Logic, structured answers, math, and short coding bursts. Smaller context is the catch.
Models for Efficiency
Gemma 4 E4B / GGUF / Q4_K_M
Light all-rounder. Writing, chat, light agents, structured output.
Phi-3.5 Mini / GGUF / Q5_K_M
Pocket sidekick. Summaries, extraction, background doc chat. Easy to pair with a bigger model.
Qwen3.5 2B / GGUF / Q4_K_M
Useful for summaries, tagging, rewrites, and lightweight sidekick work.
Micro Models
Qwen3.5 0.8B / GGUF / Q5_K_M
Classification, keyword routing, binary decisions, triage.
Gemma 4 E2B-it / GGUF / Q4_K_M
Lightweight chat, quick Q and A, summaries, tiny agents.
My personal choice for a single model is Qwen3.5 9B
For two models use Qwen3.5 9B + Qwen2.5 Coder 7B for code, or Qwen3.5 9B + Phi-3.5 Mini for support tasks.
Let me know in the comments your experience with these models, or any I have left out.
Convex now has fully flexible cloud deployments. You can create a bunch of them to test out new features. You can split your prod workload across multiple deployments. They can even be set to auto-expire. Your agent is going to want to know about this.