Some learnings from the last 12 months. At Aether our mission has always been to build a future of abundance for the human race. We plan on doing this by using our AI to design totally new classes of proteins that can assemble complex products in modular factories (more on this another time).
This time, I am publishing in full the album authored by TsKBEM in 1969, dedicated to the mock-up article N1-L3 №1M1, built for the comprehensive development of the rocket-space system.
1/16
Multiplexing can be thought of as "GPU-ification" of a complex biological system
Serial measurement becomes massively parallel
To turn biology digital, you need data at *scale* and *relevance*
The power of multiplexing is you get both.
Co-design is the future! Any effort to design de-novo functions must include both the protein design and the actual molecular function/target in model, awesome work here further validating that strategy
What if AI could invent enzymes that nature hasn’t seen? 👩🔬🧑🔬
Introducing 🪩 DISCO: Diffusion for Sequence-structure CO-design
14 rounds of directed evolution and over a year of wet lab work. That's what it took to engineer an enzyme for selective C(sp³)–H insertion, one of the most challenging transformations in organic chemistry.
DISCO surpasses this with a single plate. No pre-specified catalytic residues, no template, no theozyme, no inverse folding, just joint diffusion over protein sequence and structure.
📝 Blog: https://t.co/j9Za0JigfO
📄 Paper: https://t.co/ficrYNBBrM
💻 Code: https://t.co/p81sSwoaPH
Protein function models are the future! Requires massive multi-functional datasets to generalize not just to “natural” functions but also to push well beyond what nature evolved.
Progress in AI modeling of proteins leaves major gaps affecting most proteins and especially functional analysis. The opportunities to transcend them beacon:
AI models can now predict static protein structures with high accuracy. This achievement is rightly celebrated. It is equally important to recognize what remains unresolved and why those gaps matter hugely for biology.
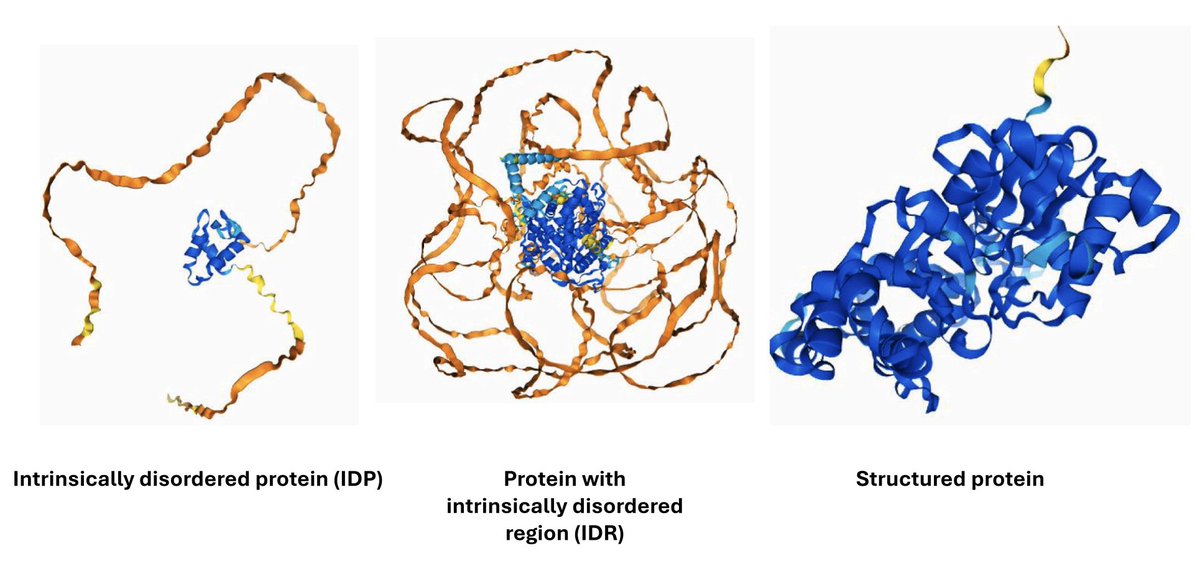
1. Modeling intrinsically disordered regions (IDRs) is a central limitation.
Roughly 30–40% of amino acid residues in the human proteome fall into this category, and ~70% of proteins contain substantial disordered segments. These regions do not adopt a single stable structure; instead, they exist as dynamic ensembles that often become structured only upon binding or under specific cellular conditions. Current AI models -- trained on static structures -- do not predict these ensembles. Instead, they either assign low confidence or produce arbitrary conformations. This is not a minor edge case; it is a large and functionally critical fraction of proteome space, deeply involved in signaling, regulation, and disease.
2. A second key limitation concerns protein function.
Biology ultimately depends on changes in conformation, interactions, and state. Many key biological processes arise from shifts between multiple conformations or from subtle perturbations induced by amino acid substitutions, post-translational modifications, or binding partners. Current models are optimized to predict a single, most likely structure. They are not designed to capture how that structure changes under perturbation, nor how populations of states shift. As a result, predicting function -- arguably the central goal -- remains a weakness in many cases.
Outlook
These two challenges point to a deeper issue: proteins are not static objects but dynamic systems governed by energy landscapes. What is needed next is not just better structure prediction, but models that can capturing ensembles, relative state populations, and the effects of perturbations on those distributions. This will likely require accurate and scalable measurements of proteins, integrating generative models, explicit or learned energetics, and dynamic sampling into a unified framework.
In this sense, the field is entering a new phase. Predicting “the structure” was a milestone. Understanding how proteins move, adapt, and function -- especially in the large, disordered fraction of the proteome -- remains the frontier.
Star Wars depicts a future where cybersecurity just doesn't work. They have AGI but they keep it bottled up in droids; they don't network anything. As soon as R2-D2 gets access to an actual network he successfully hacks the Death Star.
People keep saying FAM is turning into to The Expanse, but it's actually going to become the Red Mars trilogy.
And a space elevator on Mars was actually a major plot point for a Mars rebellion in that series.
I've said it once, I'll say it again and keep repeating myself:
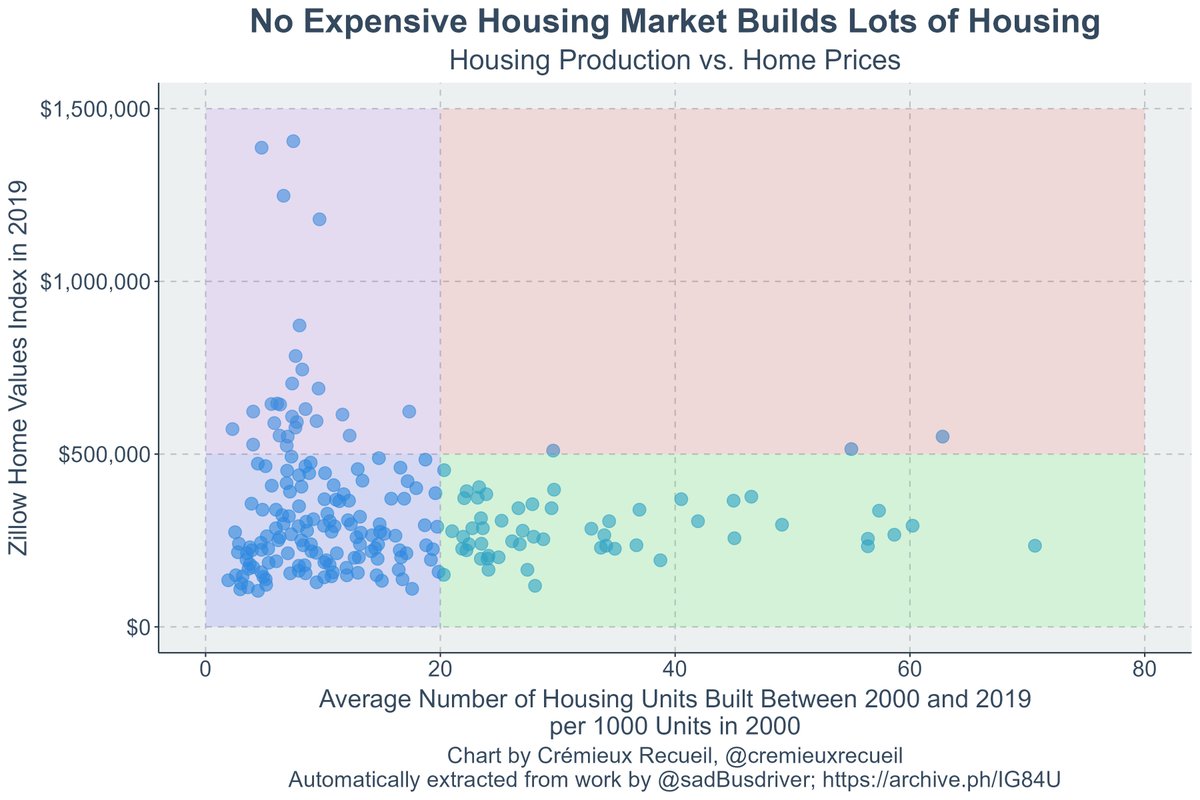
No expensive housing market builds lots of housing.
That is not a coincidence: build homes and prices are controlled!
Whenever the Big One hits San Francisco and levels vast swaths of the city, we will finally confront an uncomfortable truth: we have outlawed our own existence.
Cities built over generations cannot be rebuilt because our codes are anti-city, and most people don’t know it.
TIL about the existence of blebbisomes (large extracellular vesicles that contain everything but a nucleus) and they are named this because they, in the technical parlance, "bleb around"
it's so WHIMSICAL i'm so happy
bleb bleb bleb
This is why all these startups have generally failed, algorithmic approaches for over 10 years have been able to find targets, but the real value unlock only happens well into clinical trials when safety and efficacy are determined!
Yep!
We have so many drug targets. Finding targets is not the issue.
The issue is testing them and going through the rigamarole to get them produced and on the market.
AI-in-medicine people are missing this and talking about an area that just isn't the bottleneck to new drugs.
@Patrick_Maksoud@p_maverick_b Yeah, generated internally is the only way, but I’ve at least not seen anyone outside of Aether generating the right type (and volume) of data to train these models