Reinforcement learning on visual first-person environments is costly: rendering engines are expensive!
Enter JAXenstein: a lightning fast benchmark of first-person environments based on a pure JAX reimplementation of the Wolfenstein 3D rendering engine.
(1/n)
You can check out (and contribute to!) the framework here:
https://t.co/L7QnWf1Hu5
For more details, our preprint is here:
https://t.co/RGjalFqwHc
(n/n)
Can BC policies be quickly improved through real world experience?
Our new #RSS2026 paper proposes Q2RL, a method that bridges BC and RL for on-robot learning.
Q2RL improves BC policies by up to 3.75x with just 1-2 hours of online interaction!
So when life gives you BC, make Q-functions! 🍋
Details in thread 🧵
Learning accurate World Models for long horizon planning is hard.
So what minimal aspect of world dynamics must a model capture to achieve complex goals?
We find a simple and effective solution in our #ICLR2026 paper, which we will present as an Oral at @worldmodel_26.
(1/n)
That being said, the current model at top tier conferences is unsustainable too. I’m not sure what the correct answer is, but we shouldn’t ignore visibility.
I’ve heard similar takes before and people like to bring up the incentive systems behind publishing at top tier conferences (jobs, positions etc.). I would argue that this often ignores one of the biggest up sides of submitting to a top tier conference: visibility.
This was one of the dangers of the RL community starting our own conference as well. We lose visibility from the wider ML community, which I still think is very important.
AI/ML publication venues are broken beyond fixable. I genuinely believe the only way to fix them is to completely devalue them (best to do that immediately, but perhaps slowly overtime since people have inertia). Then, start something new that encourages quality over quantity.
The correct answer to "what online RL algo should you use" has always been and will always be "whatever you know how to tune the hyper parameters for best"
THIS! Working with LLM folk and there seems to be a deep misunderstanding of how reinforcement learning works. I suspect it’s because of the simplified Monte Carlo algorithms (like GRPO) that have become so prevalent, where credit assignment over time isn’t even under consideration.
The issue in the first paragraph is real when learning without bootstrapping (e.g., with reinforce). TD learning methods can already learn along the way and figure out what went well and what didn't if the value function has a good understanding of the world. This works even if rewards are delayed by hours.
Adding planning updates to the mix allows agents to reason about actions that it did not take and could try in the future.
A huge shoutout to my co-authors @KaichengGuo27, @camall3n and George Konidaris.
POBAX is available on Github. If you’re curious to learn more, check out our paper (https://t.co/G0lD2wwwhI) or come chat with us at RLC 2025!
We’ll be presenting this at the Track 4: Evaluation, Benchmarks session on August 6th. Come say hi!
🧵5/5
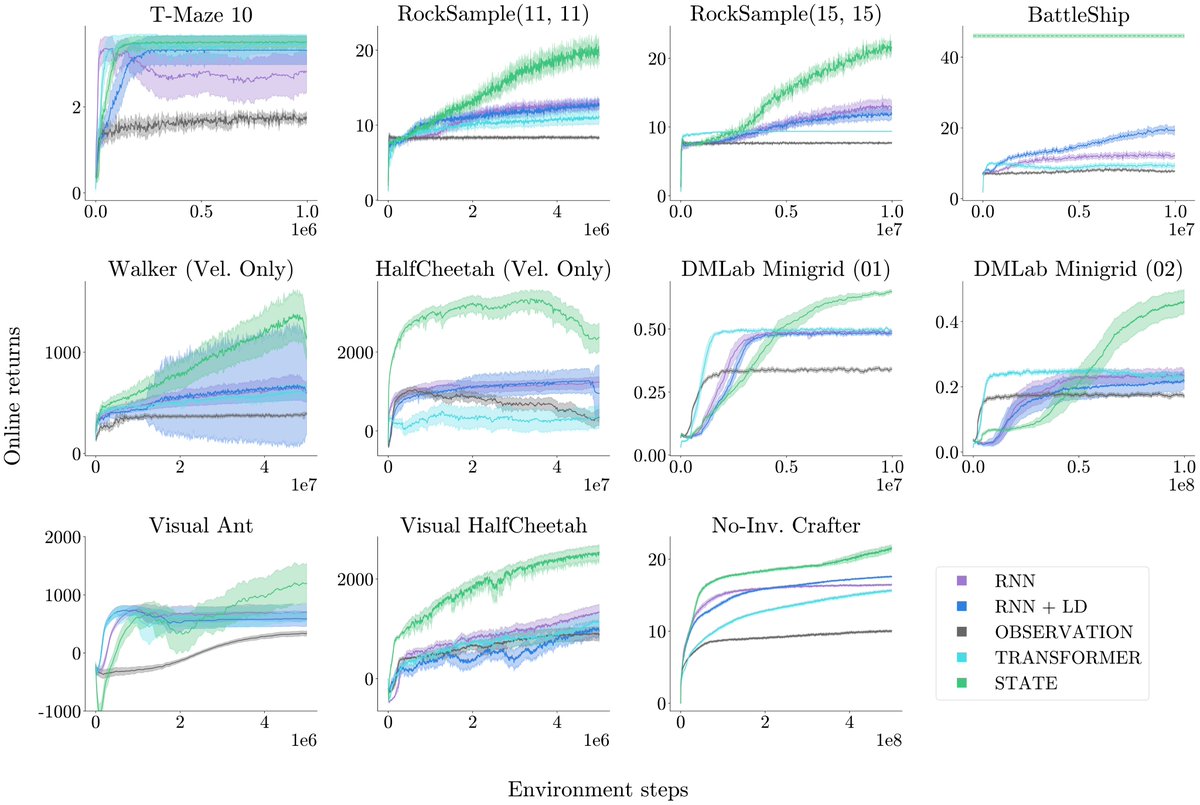
What does it mean to be “better at” partial observability in RL? Existing benchmarks don't always provide a clear signal for progress. We fix that.
Our new work (at RLC 2025 🤖) introduces a new property that ensures your gains are from learning better memory vs other factors. AND we provide a new JAX benchmark with environments that all have this property!
🧵1/5
We introduce POBAX: an open-source benchmark on partial observability that includes a diverse range of memory-improvable environments. POBAX is entirely written in JAX for extremely fast, GPU-scalable hyperparameter sweeping and experimentation.
🧵4/5