@KL_Div Felt nostalgic. 2018, I was trying something like IMLE in the other KL direction, and was trying to find a way to prevent collapse. Then I stumbled upon IMLE. Cool idea! Will check this out.
World models are hot these days, but I don't think JEPA and other efforts will really go all the way. People should take cues from Rodriguez-Sanchez, Allen, and Konidaris.
https://t.co/DZknICSGPp
Dynamical system methods are effective for reactive motion generation, but tasks that require different motions from similar states at different stages of execution remain challenging.
We address this with Phase-varying Neural Potential Functions (PNPF).
1/8
Reinforcement learning on visual first-person environments is costly: rendering engines are expensive!
Enter JAXenstein: a lightning fast benchmark of first-person environments based on a pure JAX reimplementation of the Wolfenstein 3D rendering engine.
(1/n)
Can BC policies be quickly improved through real world experience?
Our new #RSS2026 paper proposes Q2RL, a method that bridges BC and RL for on-robot learning.
Q2RL improves BC policies by up to 3.75x with just 1-2 hours of online interaction!
So when life gives you BC, make Q-functions! 🍋
Details in thread 🧵
🚨Submissions to GenPlan 2026 close May 1.
This is one of my favorite workshops--it brings together folks from so many communities around the shared problem of sequential decision making. Held at ICAPS in Dublin, June 28/29.
https://t.co/J6xwMAKPx0
Residual RL is a powerful strategy for adapting a pretrained base policy, but it struggles when:
❌ Exploration is uncontrolled
❌ Base policies are stochastic
We tackle this in our new RAL paper “Accelerating Residual Reinforcement Learning with Uncertainty Estimation”
(1/5)
Our new paper develops robots that don’t just complete tasks: they anticipate how their actions impact what comes next.
Example: when putting objects away, organizing them neatly isn’t just aesthetic—it makes future retrieval faster and easier. 📝🧵👇
Learning accurate World Models for long horizon planning is hard.
So what minimal aspect of world dynamics must a model capture to achieve complex goals?
We find a simple and effective solution in our #ICLR2026 paper, which we will present as an Oral at @worldmodel_26.
(1/n)
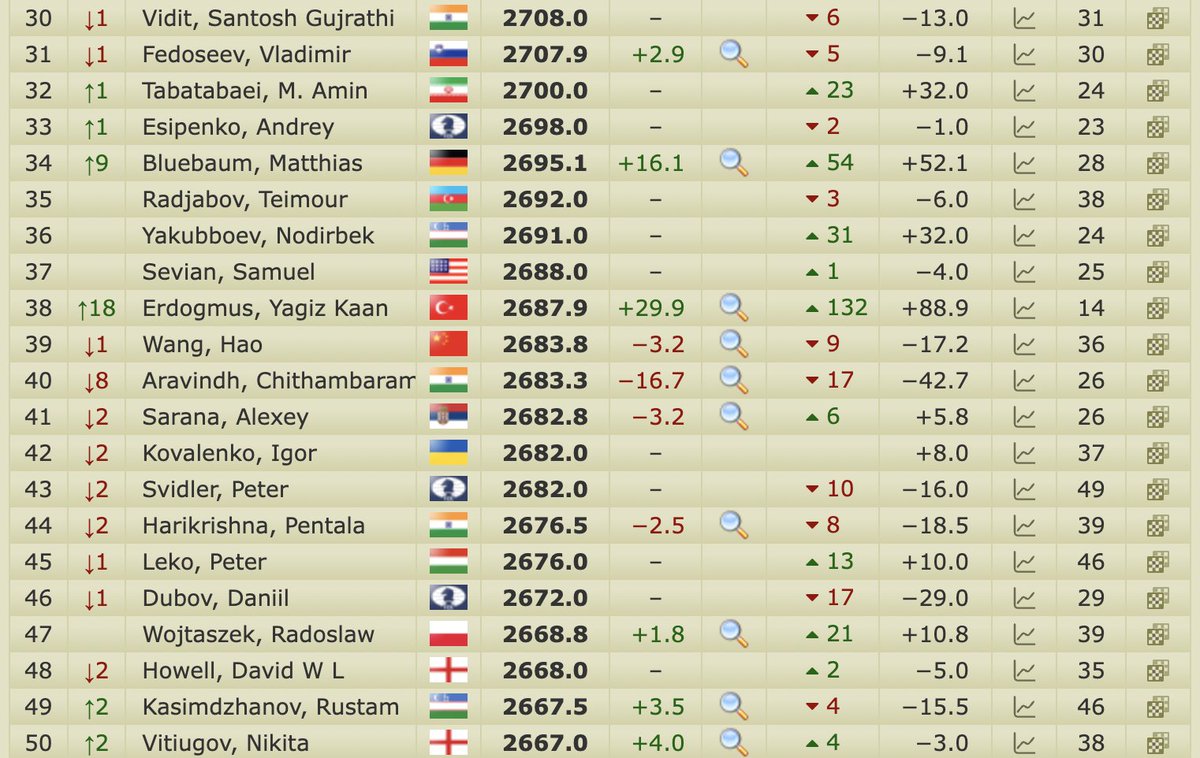
Yağız Kaan Erdoğmuş'un başarısının ne kadar algılandığından emin değilim.
Şu anda 14 yaşında ve "satrancın Wimbledon"ı denilen Tata Steel'de üçüncü sırada. Dünya sıralamasında 38'inciliğe çıktı, bundan tam bir yıl önce 170'inci sıradaydı! Çocuk olduğu için çok hızlı yükseliyor ve hâlâ 14 yaşında.
Ulaşacağı tepenin neresi olduğunu göremiyoruz. Ama Dünya Şampiyonu ve hatta satrancın yeni Carlsen'i, Kasparov'u olma ihtimali, gerçek bir ihtimal.
This week's #PaperILike is "Robot Task Planning Under Local Observability" (Merlin et al., 2024).
LOMDPs are a very natural middle ground between MDPs and POMDPs with enough structure for interesting planning and learning.
PDF: https://t.co/iiyUczgWjP