$BRUN disclosed a major GPU compute deal with Thinking Machines Lab.
Boost Run will provide managed GPU compute and cloud infrastructure under a 36-month agreement with a total contract value of ~$471.7M.
The order covers 5,000 NVIDIA B300 GPUs across Boost Run data center facilities, plus related shared storage and CPU node services.
Boost Run, Inc. $BRUN is a specialized provider of bare-metal AI and high-performance computing infrastructure, purpose-built for enterprise and regulated workloads. While larger players like CoreWeave chase raw scale and AI labs, Boost Run has deliberately targeted a more demanding but highly defensible segment: banks, healthcare systems, government agencies, and other organizations that must meet strict compliance standards.
Boost Run is the easiest and safest for the most valuable and slowest-moving customers (the ones who control trillions of dollars and handle the most sensitive data in the world)
By combining:
• Enterprise-grade compliance
• Bare-metal performance and isolation
• Extremely fast deployment
…they solve a real pain point that general clouds and pure-scale players like CoreWeave don’t fully address.
1. Regulated Industries Have Extremely Strict Rules
- Banks, hospitals, insurance companies, pharmaceutical firms, and government agencies cannot just throw their data into any cloud.
- They must follow strict regulations such as:
• HIPAA (healthcare – protects patient data)
• SOC 2 / ISO 27001 (security and privacy standards)
• PCI-DSS (credit card data)
• FedRAMP or government-specific rules
• Data residency and sovereignty laws (data must stay in certain countries or regions)
- Why this creates a moat: Most general-purpose clouds (even AWS and Azure) are “shared responsibility” models. The customer still has to do a lot of extra work to become compliant.
- Boost Run builds compliance in from the start, which their entire platform is already certified. This saves enterprises months of audits, custom configurations, and legal reviews.
2. Bare-Metal = Maximum Performance + Security + Control
- Bare-metal means the customer gets the entire physical GPU server with no virtualization layer in between.
- Why this is critical for regulated workloads:
• Performance: AI training and inference run at full speed (no 5–15% overhead from virtualization).
• Security & Isolation: No “noisy neighbor” problem. Sensitive data and models are completely isolated, which is extremely important for banks (fraud detection) and governments (national security AI).
• Predictability: Workloads run consistently every time. Regulated industries hate surprises.
• Compliance: Easier to prove exactly where data lives and who has access.
3. “AI Infrastructure in Minutes” = Massive Speed Advantage
- Traditional enterprise IT projects often take weeks or months to provision new servers and get approvals.
- Boost Run’s platform lets customers:
• Spin up thousands of GPUs
• Set up managed Kubernetes clusters
• Add high-speed storage and networking
…all through a simple console or API in minutes.
- Why speed matters so much:
• Enterprises move slowly because of bureaucracy and risk. Anything that reduces deployment time from months to minutes gives them a huge edge.
• AI projects are time-sensitive (competitors are moving fast).
• It lowers the barrier for non-technical teams (compliance officers, risk managers) to approve and use AI.
This combination of compliance-certified + bare-metal performance + lightning-fast deployment is rare.
Citadel takes 5.5% stake in $BRUN
Just 10 days after Nasdaq debut, Ken Griffin’s firms disclose 1.74M shares in the NVIDIA-backed AI GPU cloud play.
Passive 13G. Strong signal
This chart is insane...
Currently retesting a 25 year range breakout
This company collects $$ from every single fast growing sector in AI from memory to photonics and everything in between
$VECO
This is how the SpaceX Raptor engines have changed over the years
Here's some of the things that have improved:
Chamber pressure:
Raptor 1 (2019): ~250 bar
Raptor 2 (2022): ~300 bar
Raptor 3 (2024): ~350+ bar
Thrust:
Raptor 1: ~185 tf
Raptor 2: ~230 tf
Raptor 3: ~280 tf (target)
Reuse target:
Raptor 1: Limited testing
Raptor 2: High reuse target
Raptor 3: 100+ flights
(Photo Credit: @JarsyInc)
Veeco Instruments $VECO plays a strong enabling role in $INTC Intel’s ISSCC 2026 breakthroughs, particularly in the areas that require precise thermal processing, defect-free patterning, and advanced materials. While Veeco is not mentioned directly in the presentations (as they are Intel’s internal R&D), its technologies are foundational to making these innovations manufacturable at scale.
1. 3D Stacked RibbonFET + PowerVia (Strongest Direct Link) Intel highlighted vertically stacked NMOS/PMOS nanosheets with shared gates and backside power delivery (PowerVia/PowerDirect). These structures demand low thermal-budget annealing for dopant activation, contact formation, and material modification without damaging delicate 3D stacks.
- Veeco’s Role: Its Laser Spike Annealing (LSA/NSA) platforms are Production Tool of Record (PTOR) at leading-edge logic manufacturers for gate-all-around (GAA/RibbonFET) nodes and backside power delivery applications. The NSA500 specifically targets low thermal-budget needs like backside contacts and PowerVia.
- Validation: Veeco won Intel’s EPIC Supplier Award for Excellence in Anneal Technology in both 2025 and 2026, Intel’s highest supplier honor. Back-to-back wins signal deep collaboration on exactly these transistor and power delivery innovations.
2. High-NA EUV Lithography (21nm pitch, <1nm LWR) Intel demonstrated industry-leading High-NA EUV results with ultra-clean post-etch lines.
- Veeco’s Role: Veeco’s NEXUS IBD-LDD Ion Beam Deposition systems are the established standard (near-monopoly position) for depositing Mo/Si multilayers and Ru capping layers on EUV photomask blanks. High-NA EUV requires even stricter defect control and precision, directly boosting demand for Veeco’s mask tools.
3. 2D TMD Channels (MoS₂, WSe₂) Intel is advancing ultra-thin 2D materials for sub-nm scaling.
- Veeco’s Role: Veeco’s ALD (Atomic Layer Deposition) and MBE systems enable high-quality deposition of 2D materials like MoS₂. A 2025 University of Michigan study using Veeco’s Fiji G2 PEALD system demonstrated novel synthesis routes for integration into commercial devices. This positions Veeco for longer-term opportunities as Intel moves these toward fab production.
Overall Impact
- Strategic Supplier Status: Intel’s repeated EPIC Awards + PTOR wins confirm Veeco as a Tier-1 partner for Intel’s 18A, 14A, and future Angstrom-era nodes.
- Bullish for $VECO : Intel’s public progress accelerates industry-wide adoption of these architectures, expanding the addressable market for Veeco’s annealing, mask, and deposition tools. Orders typically follow R&D demos by 12–24 months as nodes ramp into high-volume manufacturing.
In short, Veeco doesn’t invent the transistors. Veeco provides the critical process equipment that makes Intel’s ISSCC-demonstrated breakthroughs production-viable. This reinforces Veeco's growth narrative in advanced logic and 3D/AI semiconductor manufacturing.
Imec just announced the world’s first working 3D charge-coupled device (CCD) memory with IGZO channels, built using a 3D NAND-style “punch-and-plug” process (announced today, May 12, 2026).
Key highlights from the article:
• It’s designed as a high-density, low-cost CXL Type-3 buffer memory specifically for AI/ML workloads.
• It moves large blocks of data super-fast to multiple AI processors through CXL switches.
• Huge advantages over future DRAM: much higher bit density (projected 5×+), lower cost-per-bit, unlimited endurance, long retention, and low-voltage operation.
How this connects straight to Penguin Solutions ($PENG):
Penguin’s fastest-growing business is exactly this kind of AI memory solution. Their MemoryAI™ KV Cache Server, CXL add-in cards, and big-memory expansion systems are built to break the “memory wall” in AI inference by giving GPUs a giant, fast, affordable extra “backpack” of memory.
Penguin doesn’t manufacture the raw memory chips. Penguin designs the modules, appliances, and full AI infrastructure that use them. So when (or if) Imec’s tech gets commercialized by big memory partners (like SK hynix, Samsung, or Micron), Penguin is perfectly placed to plug the denser/cheaper 3D CCD memory into future versions of their CXL products
$NOK is becoming an X favorite
But many people still don’t know all the potential that they have
I’ve created a lot of content around Nokia the past few months
So I am going to compile it all, condense it to the most critical pieces, and post a full article on X this weekend!
If you are interested in the company or at least want to understand why it’s been ripping, follow along!
Share this and get the word out!
LightCounting’s March 2026 Ethernet Optics Report: The core thesis is that annual sales of optical interconnects (primarily Ethernet optical transceivers) used in AI clusters have a reasonable chance of reaching $100 billion by 2030
Key highlights from the document:
- **Recent performance**: Ethernet optical transceiver sales **doubled in 2024** and grew another **70% in 2025**, beating expectations. InP laser suppliers added capacity, and shortages for many transceiver components are easing.
- **2026 outlook**: Enough capacity to double sales again, but growth is expected to be limited to ~**60%** due to shortages of XPU (e.g., GPUs/TPUs) and switch ASICs limiting AI cluster expansion (unless customers build deep inventory).
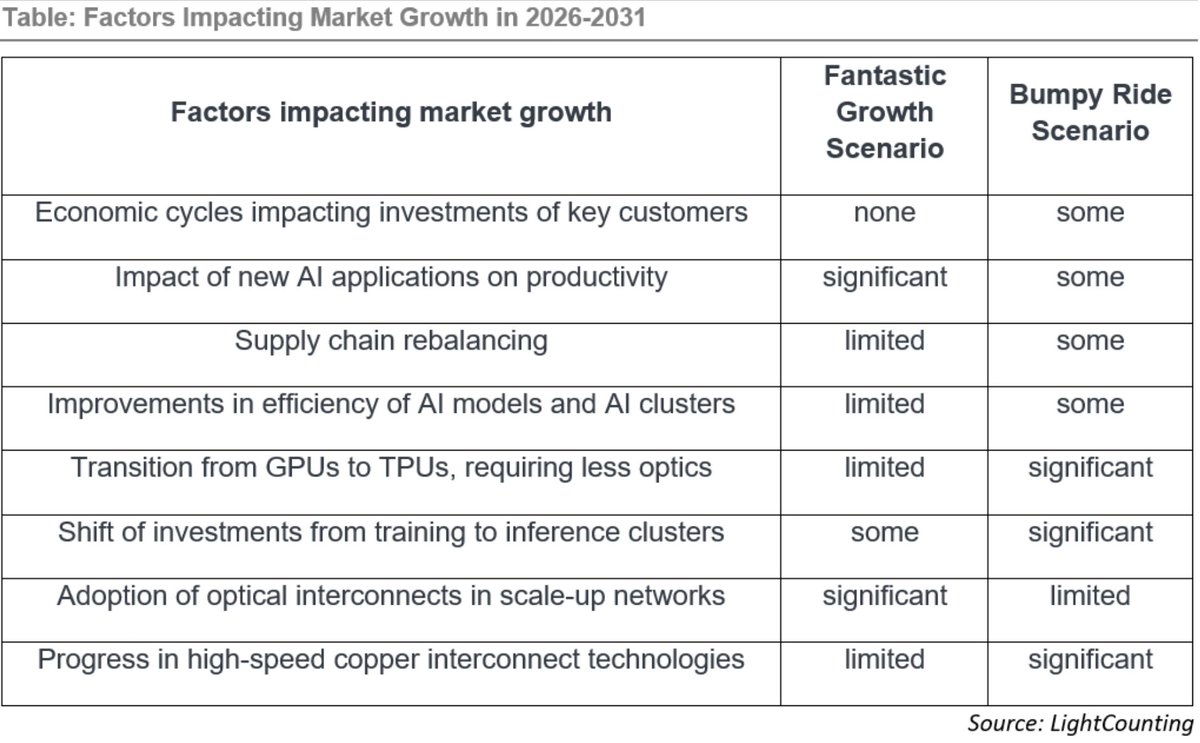
- **2027–2031 uncertainty**: The market has historically shown 2–3 year growth cycles interrupted by flat/negative years (often due to supply chain rebalancing). The base forecast is a "**Soft Landing**," but a "**Bumpy Ride**" correction is possible. The "**Fantastic Growth**" scenario (reaching ~$100B+) is described as looking "like a fantasy" compared to history, though AI changes everything.
- **Tailwinds for AI cluster optics**: Larger clusters require more transceivers per GPU (up to 6 in scale-out networks); optical connectivity in scale-up networks (needing ~10x more bandwidth) opens new opportunities. The top 4 cloud hyperscalers (Amazon, Google, Meta, Microsoft) already dominate spending.
- **Report scope**: Detailed forecasts (units, prices, sales) through 2031 for 100+ product categories of high-speed Ethernet transceivers (100GbE to 3.2T, including retimed, LPO/LRO, CPO/NPO) sorted by reach and form factor, focused on AI/cloud data centers.
**How this relates to $VECO (Veeco Instruments Inc., NASDAQ: VECO) and positive/negative impacts:**
**$VECO is strongly positively positioned** by the trends in this report. Veeco is a leading supplier of specialized semiconductor process equipment used to manufacture **Indium Phosphide (InP) lasers** - a critical component (and recent bottleneck) in high-speed optical transceivers (especially 800G and 1.6T+) for AI/hyperscale data centers.
Veeco's key relevant products:
- **Lumina MOCVD systems** → for InP epitaxy (laser wafer growth).
- **Spector Ion Beam Deposition (IBD)** → for high-performance, low-absorption laser facet coatings.
- **WaferEtch/WaferStorm wet processing** → supporting overall InP laser production.
**Positive impacts on VECO** (already materializing):
- Veeco announced **>$250 million in multi-customer equipment orders** (May 2026) for exactly these InP laser tools, with deliveries starting in 2026 and **significantly accelerating in 2027**—directly tied to 800G/1.6T transceiver ramps for AI clusters.
- Earlier orders (e.g., March 2026 Lumina + Spector wins) established Veeco tools as "production tool of record" at leading optical laser makers.
- Veeco projects its compound semiconductor served available market (SAM, heavily driven by silicon photonics/InP lasers) growing from ~$1B in 2026 to **$2B by 2030** (15% CAGR), with InP lasers alone reaching ~$700M.
- This has already driven strong order momentum, revenue guidance ($740–800M for FY2026), and stock reactions on the news. The "Fantastic Growth" or even strong Soft Landing scenario in the PDF would fuel multi-year equipment capex as transceiver makers scale production.
**Negative or risk impacts on VECO** (if the Bumpy Ride scenario plays out):
- Any slowdown, correction, or flattening in optical transceiver demand (e.g., due to supply chain rebalancing, major efficiency gains in AI models/clusters, shift from training to inference clusters, GPU→TPU transition requiring less optics, or faster progress in high-speed copper alternatives) would reduce the need for new InP laser manufacturing capacity after the initial 2026–2027 ramp.
- The report's historical cyclicality warning applies: equipment orders are front-loaded (buildout phase), so a "Bumpy Ride" dip post-2027 could lead to order pauses.
- Near-term limits (e.g., 2026 ASIC shortages slowing cluster builds) could delay Veeco's revenue ramp slightly, though Veeco's orders already provide multi-year visibility.
**Overall**: The LightCounting report is **highly bullish for VECO** in the near-to-medium term. It validates the AI-driven optical interconnect boom that Veeco is already capitalizing on with record InP-related orders. The upside is clearest in the Fantastic Growth or strong Soft Landing paths; downside risk is mainly a severe Bumpy Ride correction or faster-than-expected copper displacement. Veeco is essentially a "picks-and-shovels" play on the exact market expansion.