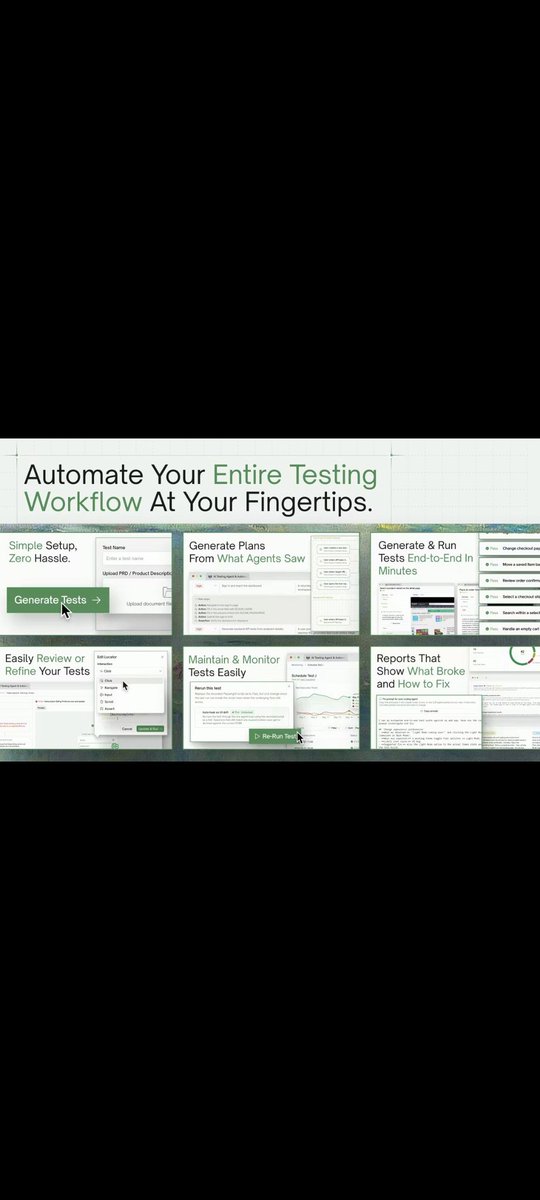
TestSprite 3.0 is live. A fleet of parallel AI agents that use your app like real users — in minutes. This is the release we've been building all year.
The numbers tell the story of our completely overhauled engine:
- Accuracy jumped by nearly 40% on the hardest, most complex projects.
- Coverage increased significantly across the board for every E2E run.
- Reliability is locked in—stable and consistent across multiple runs.
We rebuilt our entire engine around these performance gains so you can ship fast and ship confident.
AI tools like Claude Code and Codex made writing syntax a solved problem. The real bottleneck now is validation.
Spoke at DevSummit 2026 in Mongolia about why the future of software engineering isn't about generating code — it's about building the scaffolding to prove it actually works.
Huge thanks to @UnreadToday for capturing the event and @BELLEfounders for backing builders worldwide.
For years, software delivery was constrained by one thing:
Writing code.
Now that's changed.
AI can generate features, refactors, tests, and even entire applications in minutes.
But there's a new bottleneck emerging:
Confidence.
How do you know the code actually works?
Most teams still rely on a familiar workflow:
→ Generate code with AI
→ Run CI/CD checks
→ Review the PR
→ Merge
The issue is that passing tests doesn't necessarily mean the user experience works.
Broken flows, missing edge cases, UI regressions, and unexpected interactions often don't show up until real users hit them in production.
That's why I found @Test_Sprite interesting.
Instead of only analyzing source code, it launches your application and actively interacts with it like an end user would.
The platform coordinates multiple AI agents that explore the product, build test scenarios, execute them, and document exactly what happened.
A few capabilities that stood out:
• Autonomous application exploration
• AI-generated test plans
• Replayable execution videos
• End-to-end API visibility
• Automatic adaptation to UI changes
• GitHub workflow integration
We're entering a world where creating software is becoming increasingly automated.
The real challenge is verifying that what was created actually behaves the way users expect.
That's the gap TestSprite is tackling.
This is the thread I send people when they ask why we obsess over test quality.
The agent did exactly what agents do: optimized the metric it could see. Your hand-written version came from understanding the system, not the loop.
We think a lot about this at TestSprite, the agent's output is only as trustworthy as the tests measuring it, and most people are generating neither carefully.
"Think. Analyze. Learn." is the entire job.
We know, we know... sorry for the long wait. 🤫 But Season 03 is going to be worth it.
We’ve thrown out the old rules. Expect brand-new tools designed to push your code quality to the absolute limit.
Drop your mystery prize pool guesses below! 👇
@DesignByMaeL@ProductHunt You are completely right about the dev trust, keep an eye on our CEO @yunhaojiao since he might drop a deep-dive thread on this😉
#1 Product of the Day on @ProductHunt 🏆
May 22 — TestSprite.
To the developers testing with TestSprite every day, the teams who told us what was broken, and everyone who showed up on launch day — thank you.
You shipped this with us
TestSprite 3.0 is live. A fleet of parallel AI agents that use your app like real users — in minutes. This is the release we've been building all year.
The numbers tell the story of our completely overhauled engine:
- Accuracy jumped by nearly 40% on the hardest, most complex projects.
- Coverage increased significantly across the board for every E2E run.
- Reliability is locked in—stable and consistent across multiple runs.
We rebuilt our entire engine around these performance gains so you can ship fast and ship confident.
Try it free → https://t.co/DYZBVrPoCF
We're on Product Hunt → https://t.co/SgQKBgS0f2
Tell us what you'd want it to break on. We're reading every reply.
Is anyone doing feature flag development with agents?
Not tried it, but in theory feature flagging is an alternative model to PR's to getting work on main.
1. Put it on main, disabled by a flag
2. Deploy with the rest of the system
3. Unflag to selected users early
4. Fix bugs for those users
5. Unflag to more users
6. Repeat until shipped
Feels like a perfect strategy to pair with agents
This is exactly how the modern AI workflow should look. General agents handling their own basic post-fix reviews, which frees up your dedicated testing agents to focus purely on complex test coverage and edge cases. The ecosystem is maturing fast
Woke up to see that Grok Build finished my feature build from last night.
But what's the most interesting to me, is that it has a set of suggestions for what to do to really make sure everything is done right.
This is different from any other agentic coding agent I've used. Normally, coding agents just end when they finish a task, but with Grok Build, it always ends by suggesting things like small targeted fix rounds.
Really neat. Almost like a senior dev who says, hey - I know you think you're done, but if you really want to do it right, here's what I would do.