Your RAG system is only as good as the data you feed it. If the parser messes up tables, headers, and reading order, your multi-million dollar LLM gets garbage in, garbage out.
🚨 The biggest bottleneck in RAG isn't your fancy AI model. It's the humble document parser. 90% of teams are optimizing the wrong thing. #RAG#AI#DataEngineering
Open-source doc parsing vs TextIn xParse closed-source:
🟢 OSS: Good for testing
🔵 xParse: Built for SCALE & SECURITY
Why? Production RAG systems need:
• Zero accuracy drift
• Bank-grade data control
• No infrastructure overhead
Under the hood:
✅ Dynamic model updates (no community wait!)
✅ Hybrid deployment: Cloud/SaaS/On-prem
✅ Various doc type support (contracts/tables/schematics)
✅ Audit trails & RBAC for enterprises
OSS can't match this ops maturity. 📈
⭐️xParse Updates for June
1. Table Model Enhancement: Added tangent detection for improving table parsing accuracy.
2. Cross-Page Cell Semantic Merging: Enabled semantic merging of cells across pages for complex, multi-page tables.
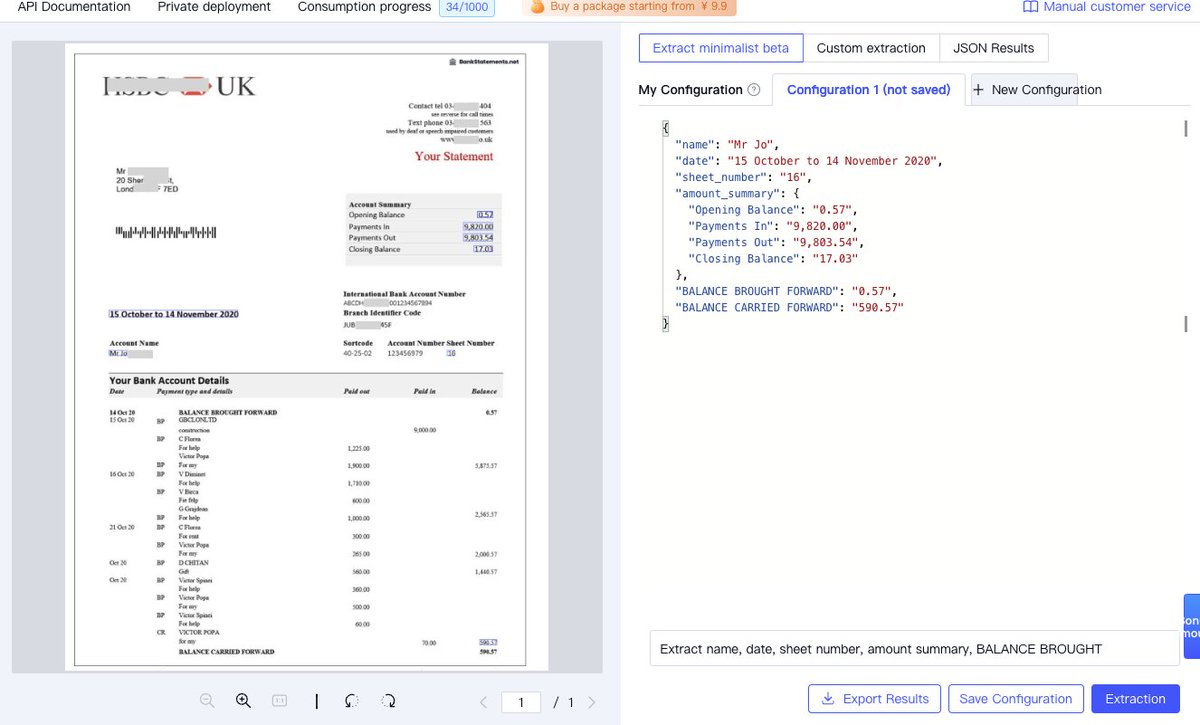
Why settle for traditional extraction tools when you can use AI? With Textin, your document data extraction needs are just a sentence away. Try the future now! #AIForBusiness#TechInnovation
🔍 Extracting data from documents has never been this easy. With TextIn, just type a prompt and get structured data like JSON without the complexity. Imagine the possibilities! #DataAutomation#AI
From contracts to bank statements, TextIn's solution enables real-time extraction, saving businesses from costly manual data entry. It’s automated efficiency at its best! #BusinessTech#Textin
Textin's technology uses LLM (large language models) to understand your needs in natural language, delivering precise outputs every time. It's never been easier to automate document processing. #AI#TechInnovation
⚡️Tired of complex extraction setups? With TextIn's AI-driven solution, you just need a simple prompt to extract info from invoices, contracts, or reports—no code, no hassle. #AI#Automation#Textin
Gone are the days of manual configurations! Just tell Textin what to extract (e.g. contract amounts, invoice numbers), and get it in structured data—fast. 🔄 #DocumentAutomation#DataExtraction
The future of SEO ≠ keywords. It’s trust + structure + entity alignment.
Credit to @OtterlyAI — their guide is a goldmine for AI-native marketers.
🔁 Save this. Share with your team. Your traffic depends on it.
#GEO#LLMO#AISEO#OtterlyAI#DigitalMarketing#ChatGPTSEO
Just read the OtterlyAI - Generative Engines Optimization Guide.
📌 Here's a distilled GEO/LLMO Checklist you must review if you're optimizing for AI-first search (ChatGPT, Perplexity, Gemini, etc) 👇
✅ Entity audits
✅ LLM-ready SEO strategies
✅ PR alignment with AI topics
✅ Wikipedia listing
✅ UGC on Reddit
✅ Credible citations
✅ Authority quotes
✅ Unique stats
✅ High readability
✅ Simple language
✅ No keyword stuffing
✅ No black hat tactics
Different DPI settings (72, 144, 216) change the scale of coordinates. Learn how to convert them correctly to maintain table quality across various platforms. #TechSolutions#API#DPI
Why do we need table image extraction? In digital offices, we often need to extract tables from documents (like PDFs) to ensure accurate formatting and data integrity. #TableExtraction#API
But here's the challenge: DPI—the dots per inch setting—affects how coordinates are mapped. Understanding DPI is crucial for accurate extractions! #DPI#TechChallenge