Agents aren't just prompts, tools, & RAG glued together.
You need a reference architecture.
@openclaw makes the design decisions behind modern AI agents visible — orchestration, memory, tooling, and how it all fits.
See it unpacked live with @_nerdai_ & @ProfTomYeh on 2/19, 1pm EST: https://t.co/qtlHbJ9ykm
Dive deeper with Build a Multi-Agent System (From Scratch): https://t.co/lZsGlGOWn9
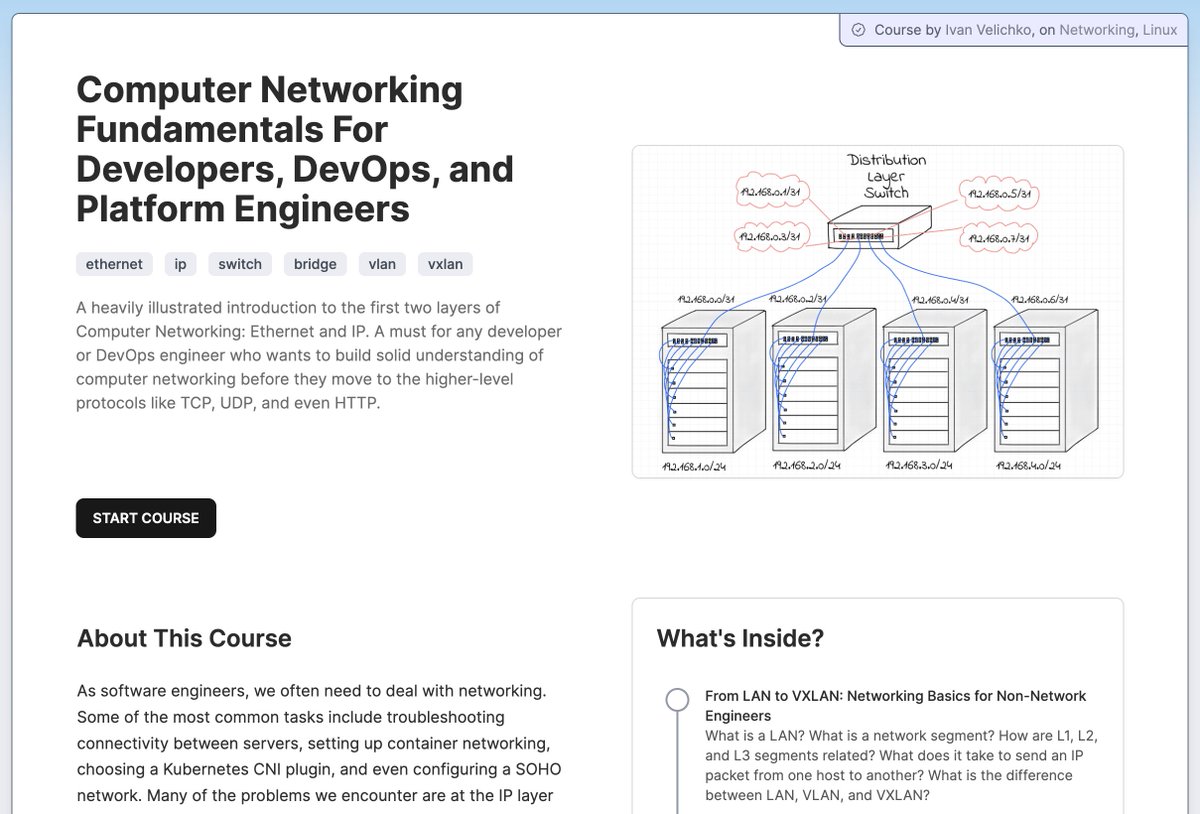
Computer Networking Fundamentals (mini-course)
Everyone who wants to understand container and Kubernetes networking should start from the basics. This heavily illustrated free course walks you through the first two layers of Computer Networking: Ethernet and IP.
A must for any developer or DevOps engineer who wants to build a solid understanding of computer networking before they move to the higher-level protocols like TCP, UDP, and even HTTP.
https://t.co/Cm4NTgcjK9
You can memorize patterns and still build systems that fall apart.
Because real system design comes in levels.
⬆️level 0 Fundamentals:
• Clients send requests
• Servers handle logic
• Databases store data
• Auth & Input validation
You learn HTTP methods, status codes, and what a REST API is.
You pick between SQL and NoSQL without really knowing why.
You're not a backend dev until you've panic-fixed a 500 error in production caused by a missing null check.
⬆️level 1 Master the building blocks:
• Load balancers for traffic distribution
• Caches (Redis, Memcached) to reduce DB pressure
• Background workers for async jobs
• Queues (RabbitMQ, SQS, Kafka) for decoupling
• Relational vs Document DBs; use cases, not just syntax differences
You realize reads and writes scale differently.
You learn that consistency, availability, and partition tolerance don't always play nice.
You stop asking "SQL or NoSQL?" and start asking “What are the access patterns?”
⬆️level 2 Architect for complexity:
• Separate read and write paths
• Use circuit breakers, retries, and timeouts
• Add rate limiting and backpressure to avoid overload
• Design idempotent endpoints
You start drawing sequence diagrams before writing code.
You stop thinking in services and start thinking in boundaries.
⬆️level 3 Design for reliability and observability:
• Add structured logging, metrics, and traces
• Implement health checks, dashboards, and alerts
• Use SLOs to define what “good enough” means
• Write chaos tests to simulate failure
• Add correlation IDs to trace issues across services
At this level, you care more about mean time to recovery than mean time between failures.
You understand that invisible systems are the most dangerous ones.
⬆️level 4 Design for scale and evolution:
• Break monoliths into services only when needed
• Use event-driven patterns to reduce coupling
• Support versioning in APIs and messages
• Separate compute from storage
• Think in terms of contracts, not code
• Handle partial failures in distributed systems
You design for change, not perfection.
You know your trade-offs.
You know when to keep it simple and when to go all in.
What’s one system design lesson you learned the hard way?
Learn Model Context Protocol [MCP] with Python — Build Agentic Systems in Python with the new standard for AI Capabilities: https://t.co/FxvLXu4sNd by @chris_noring v/ @PacktDataML
𝓦𝓱𝓪𝓽 𝓨𝓸𝓾 𝓦𝓲𝓵𝓵 𝓛𝓮𝓪𝓻𝓷:
🟠Understand the MCP protocol and its core components
🟣Build MCP servers that expose tools and resources to a variety of clients
🔵Test and debug servers using the interactive inspector tools
🟠Consume servers using Claude Desktop and Visual Studio Code Agents
🟣Secure MCP apps, as well as managing and mitigating common threats
🔵Build and deploy MCP apps using cloud-based strategies
Also... Purchase of the print or Kindle book includes a free PDF eBook copy
📣 Deal of the Day 📣 Jan 30
New liveProject series! HALF OFF today!
Build Your LLM and Fine-Tune it for Real Tasks & selected titles: https://t.co/vJJTnDMlf3
For intermediate Python programmers who understand both data processing and machine learning basics, and are keen to adapt these skills to creating and tuning Large Language Models. #LLMs #UnSloth #FineTuning #LLM #llama3 #llama4
In this #liveProject series, you’ll take on the role of a data scientist at X Education, tasked with building a self-hosted LLM to cut costs and boost productivity. You’ll code the Llama 3.2 architecture from scratch to master transformers, then work to fine-tune it for lead classification for the marketing team, and adapt it for HTML code generation to support your overworked developer colleagues. #ManningPublications
The Top 26 Essential Papers (+5 Bonus Resources)
for Mastering LLMs and Transformers
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck ;)
It is dangerously easy to build a neural network today without actually understanding how it works.
We live in an era of 'import torch'. You can train a model in three lines of code, but the moment you need to debug a collapsing loss function or a vanishing gradient, syntax won't save you. You need first principles.
I recently went through this notebook collection by Simon J.D. Prince, and it is the antidote to tutorial hell.
Instead of just showing you the code, it forces you to visualize the mechanics:
1./ The Math => It builds the intuition for shallow networks and regions before adding complexity.
2./ The Optimization => It doesn't just use an optimizer; it compares Line Search, SGD, and Adam so you see why they behave differently.
3./ The Modern Stack => It connects the dots from basic backpropagation all the way to Self-Attention and Graph Neural Networks.
Move from running code to engineering systems => this is a goldmine.























![KirkDBorne's tweet photo. Learn Model Context Protocol [MCP] with Python — Build Agentic Systems in Python with the new standard for AI Capabilities: https://t.co/FxvLXu4sNd by @chris_noring v/ @PacktDataML
𝓦𝓱𝓪𝓽 𝓨𝓸𝓾 𝓦𝓲𝓵𝓵 𝓛𝓮𝓪𝓻𝓷:
🟠Understand the MCP protocol and its core components
🟣Build MCP servers that expose tools and resources to a variety of clients
🔵Test and debug servers using the interactive inspector tools
🟠Consume servers using Claude Desktop and Visual Studio Code Agents
🟣Secure MCP apps, as well as managing and mitigating common threats
🔵Build and deploy MCP apps using cloud-based strategies
Also... Purchase of the print or Kindle book includes a free PDF eBook copy](https://pbs.twimg.com/media/HAiCSuCXAAAJtJz.jpg)