just published FeedbackNet V1: Enhancing Transformers with Feedback Loops on @ZENODO_ORG
this work introduces a feedback transformer for iterative reasoning tasks, showing preliminary improvements over standard transformers.
paper: https://t.co/shnWxZzSvW
#MachineLearning
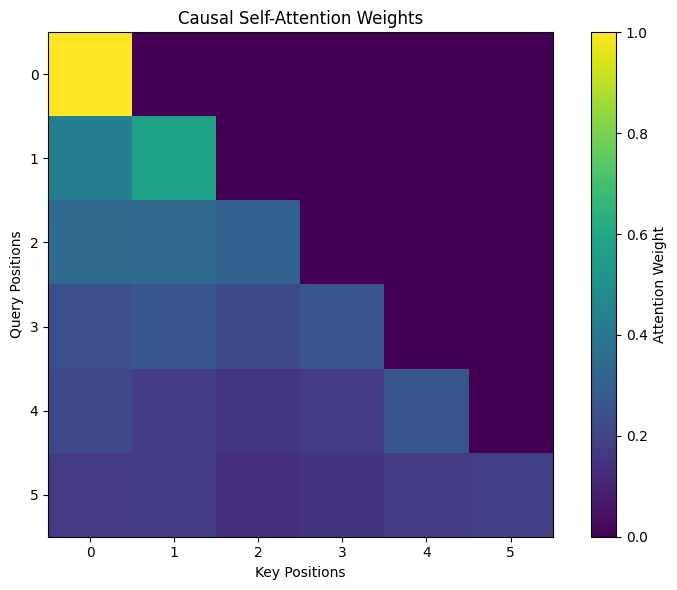
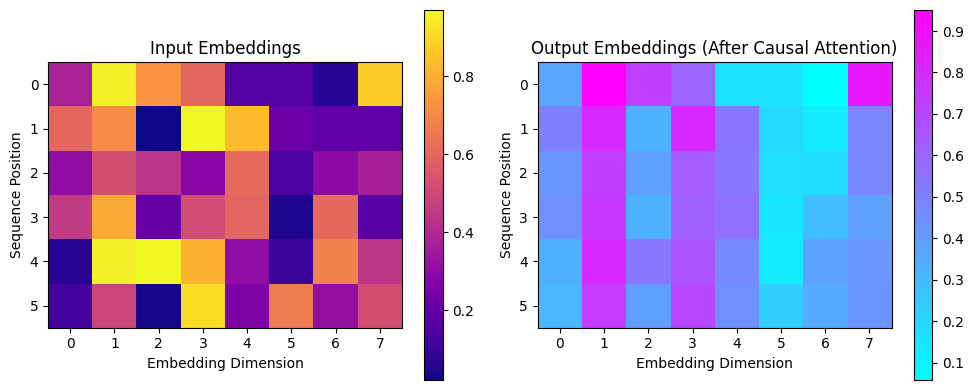
Causal (Masked) Self-Attention
Causal (Masked) Self-Attention is a special form of self-attention used when a model must predict the next word based only on past words, not future ones. It enforces the natural left-to-right flow of language.
In normal self-attention, every word can look at every other word in the sentence. But in causal attention, each word is only allowed to attend to:
• Itself
• Words that come before it
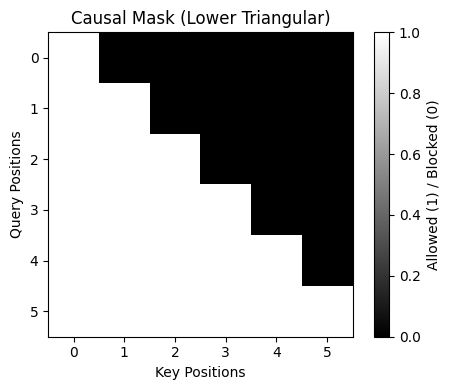
Words are not allowed to look at future words. This is done using a mask that blocks attention to later positions.
Why this is important:
• Prevents the model from “cheating” by seeing future words during training.
• Makes the model behave like real text generation, where future words are unknown.
• Ensures correct learning for tasks like text generation and autocomplete.
Key characteristics:
• Maintains autoregressive behavior (predicting one token at a time).
• Preserves the temporal order of language.
• Still allows parallel processing during training (unlike RNNs).
Used in:
• Decoder-only models like GPT.
• Language generation, chatbots, story writing, and code completion.
source code: https://t.co/hKimKuaGDT
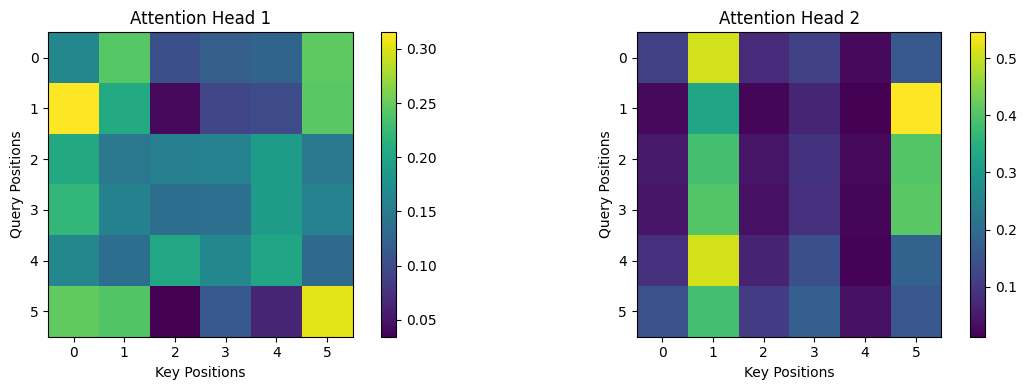
Multi-Head Self-Attention
Multi-Head Self-Attention is an extension of self-attention that allows a model to look at the same sentence in multiple ways at the same time. Instead of using a single attention mechanism, it uses several attention “heads” in parallel, each focusing on different types of relationships.
Self-attention means every word can attend to every other word in the same sentence, including itself. This helps the model understand context, meaning, and structure without processing words sequentially.
Multi-head means:
• Each head learns a different perspective of the sentence.
• One head might focus on grammar (like subject–verb relationships).
• Another might focus on meaning (like synonyms or topic words).
• Another might capture long-distance dependencies.
All these views are then combined to form a richer and more informative representation of each word.
Key benefits:
• Captures multiple types of relationships simultaneously.
• Improves understanding of complex language patterns.
• Makes the model more expressive and powerful than single-head attention.
Why it matters:
• A single attention view is limited.
• Multiple heads allow the model to see the same data in different ways, leading to better learning and performance.
Multi-Head Self-Attention is a core component of the Transformer architecture and is essential for models like BERT, GPT, and T5, enabling them to understand language deeply and efficiently.
source code: https://t.co/shMD864B2d
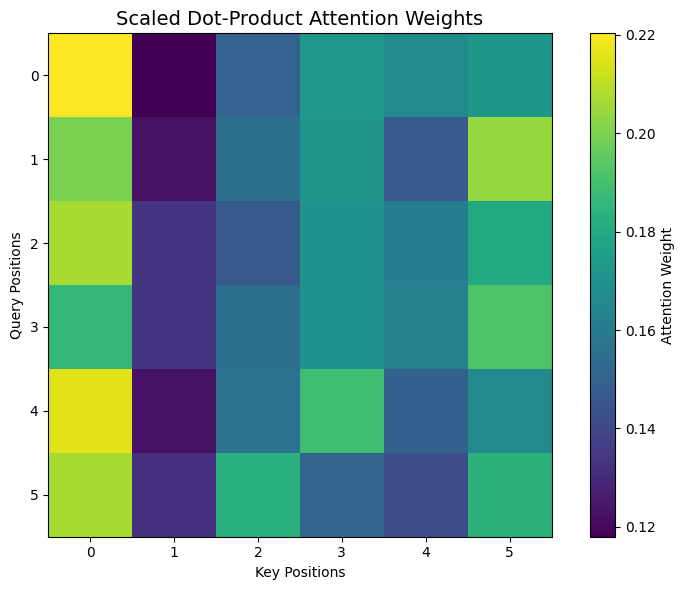
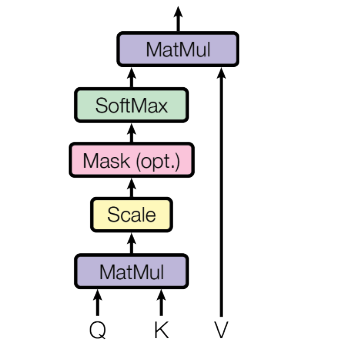
Scaled Dot-Product Attention
Scaled Dot-Product Attention is a mechanism that allows a model to decide which parts of a sentence are most relevant when processing a particular word. Instead of reading words one by one, the model looks at the entire sequence at once and assigns importance to each word based on how much it should influence the current word.
At a high level, each word in the input is represented in three different ways:
• One representation asks a question (Query),
• One represents what the word contains (Key),
• One represents the actual information to pass forward (Value).
The attention mechanism compares these representations to determine how strongly each word is related to every other word. Words that are more relevant receive higher importance, and their information is emphasized in the final representation.
The term “scaled” means the raw similarity scores are adjusted so they stay within a reasonable range. This prevents any one word from dominating too much and helps the model learn more stably and effectively during training.
Unlike traditional models that only look at nearby words, scaled dot-product attention allows each word to:
• Attend to any other word in the sentence,
• Capture long-distance relationships,
• Understand meaning based on global context, not just local neighbors.
This mechanism is:
• Parallelizable (all words processed at once),
• Efficient for large sequences,
• The foundation of self-attention in Transformers.
In short, scaled dot-product attention is how Transformers learn what to focus on, how strongly, and from where, enabling deep understanding of language structure and meaning without relying on sequential processing.
source code: https://t.co/iwdtvO3aeN
Building Neural Language Model (MLP-based) from Scratch
• A Neural Language Model (MLP-based) uses a feedforward neural network to predict the next word.
• It replaces count-based n-gram tables with learned word embeddings and neural weights.
Core idea
• Given the previous k words, the model predicts the next word.
• Words are first converted into vectors (embeddings).
• These vectors are concatenated and passed through an MLP (Multi-Layer Perceptron).
Architecture
1. Input: last k words → token IDs
2. Embedding layer → dense vectors
3. Concatenation of embeddings
4. Hidden layer(s) with activation (ReLU, tanh, etc.)
5. Output layer → softmax over vocabulary
Advantages
• Handles data sparsity better than n-grams.
• Learns semantic relationships via embeddings.
• More accurate than count-based models.
Disadvantages
• Still has a fixed context window.
• Cannot model long-range dependencies well.
• Slower than simple n-gram models.
Used in
• Early neural NLP models.
• Foundations for RNNs, LSTMs, and Transformers.
• Educational implementations of neural language modeling.
source code: https://t.co/mnEMzkHwuw
strong men creates C language.
C creates goodtimes.
goodtimes creates python, python creates ai, ai creates vibe coding, vibe coding creates weak men, weak men creates bad times, bad times creates strong men
Implementing Unigram Language Model from scratch
• A Unigram Language Model assumes that each word/token appears independently of others.
• The probability of a sentence is the product of individual word probabilities.
Core idea
• Each token has a probability based only on its frequency in the corpus.
• No context or word order is considered.
Advantages
• Very simple and fast.
• Easy to implement and understand.
• Good baseline model.
Disadvantages
• Ignores word order and context.
• Produces unrealistic sentences.
• Low accuracy compared to n-gram or neural models.
Used in
• Basic NLP education.
• Tokenizer training (Unigram LM tokenizer).
• Baseline language modeling experiments.
source code: https://t.co/y1fctpHHfv
Implemented the distributed inference arch for GPT2 125M from HuggingFace on my homemade compute cluster !!!
>cluster of 3 Mac Minis 16 gigs each connected via thunderbolt 4
>used the concept of simple pipeline parallelism and distributed the model layers across the nodes
>from scratch using socket library to handle the comms between the worker and server nodes
>its based on classic SyncPS arch which is synchronous parameter server with 1 server and 2 worker nodes
>support for distribution of layers across nodes even if num_layers % num_nodes not divisible
Code: https://t.co/TNCqyCrT6y