@The_New_Roman@CharlieIceman2@WallStreetApes Right, depending on age range. For infants (the cost we have up there) its 3 kids per adult. I suspect that for 4 year olds the cost is maybe half that.
@Zhero00@CharlieIceman2@WallStreetApes For infants, the ratio is mandated at 1:3, toddlers is 1:4, and preschool is 1:10 which is why costs get cheaper the older your kids are. Factor in floating teachers to cover breaks, janitors, rent, health insurance, liability insurance... cost checks out... and is also so high!
@LaurieM65533565@lindawiliams@JeffJacksonNC Of course, it is published and has been published for decades now if you just care to look. Here you are: https://t.co/5ez49QGzbF
@cmclymer It’s less what and more how. OP is right that on, say, a video game podcast, many of the ads are for right wing podcasts who advertise themselves as reasonable but are not. I’ve NEVER heard a single ad from the left on one of them, so of course the pull is in one direction.
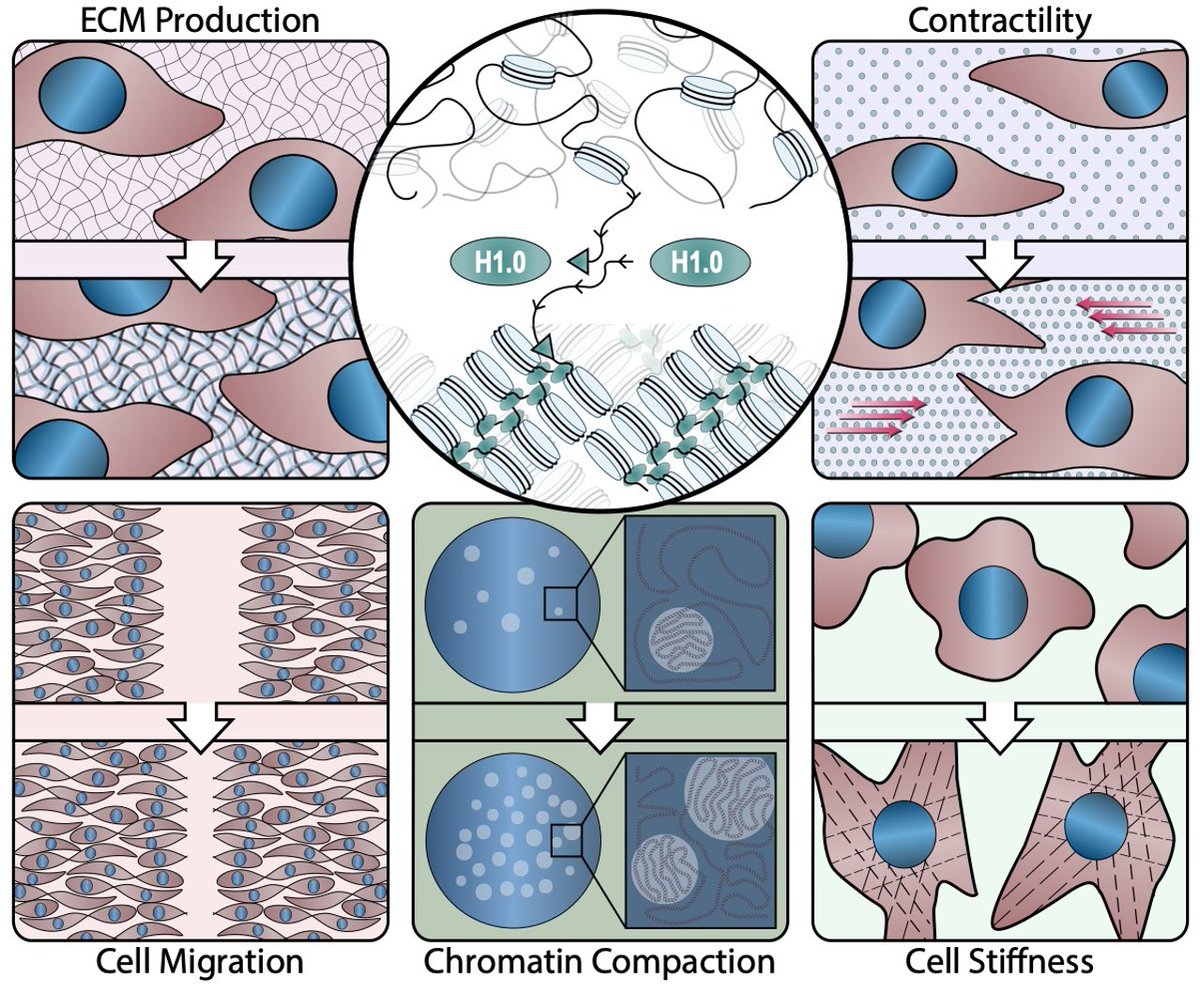
Check out our latest from the Patterson Lab - a method to assess cardiomyocyte division along with many other useful metrics all from the same heart: https://t.co/TwdUTwxmLw
Hoping the bench top protocol is not far behind! @ScientistSwift
Myocardial infarctions change both cell-specific expression and cell-type abundance. Can we algorithmically disentangle these two signals in bulk RNAseq data?
Yes!
Excited to share the first paper from the Rau lab, led by @BrianGural!
https://t.co/GQqx9u2SLB
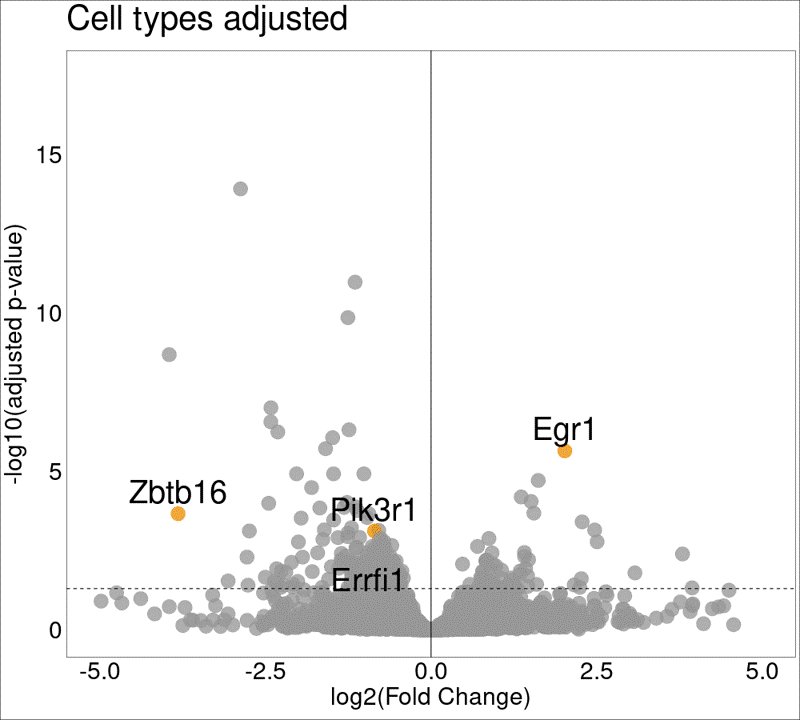
He then showed that the initial enriched GO terms in the DGE b/t WT MI and KO MI mice, largely genes associated with fibroblast abundance (which was old news!) lost significance while novel genes involved in fundamental heart integrity were highlighted as crucially important!
Thanks again to @BrianGural who led this project, along with all our collaborators in the Brian Jensen, Tom Vondriska, Michaela Patterson, and Caitlin O'Meara labs.
https://t.co/GQqx9u3qB9
We have a lot more happening with this approach, with exciting results to share shortly about what happens when you apply this algorithm to-scale across 100s of RNAseq datasets. We want to understand the noise that cell-type composition adds to our analyses!