RL for language models works best when answers can be verified exactly, like math or code. We argue that most real-world tasks are only partially verifiable and shows that turning prompts into checklists gives models a much richer learning signal than a single pass/fail judgment
1/ RLVR has driven big gains in math and code because many outputs admit reliable automatic checks: an answer matches the expected result, or a program passes tests.
But many real tasks are not like that. Code can be functionally correct but qualitatively terrible or a response may satisfy 4 syntactic constraints but fail 1 semantic constraint.
6/ We also study self-verification: using the same model as generator and verifier.
Naive self-verification collapses: measured reward rises, but IFEval drops from 73.9 → 55.1 as the verifier learns to always say “yes.”
Soft-SVeRL stabilizes this with verifier co-training, aggregating parallel verifier calls, and an anti-collapse penalty.
@willccbb > my instinct is you basically need to model the world
I am increasingly subscribing to this camp with the caveat of the need to co-train the generators and verifiers / world-models.
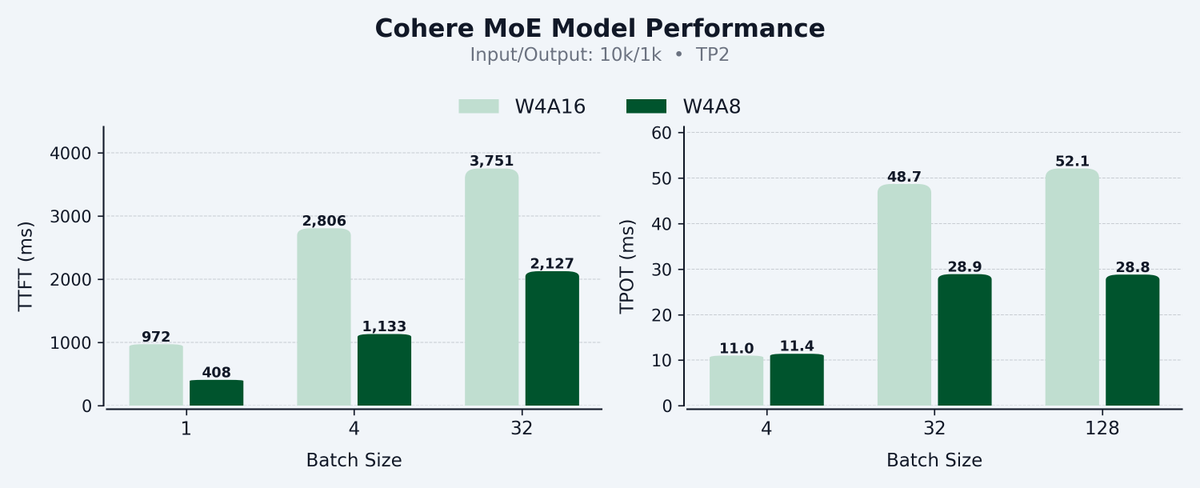
Excited to share our work on production-ready W4A8 inference, now integrated in vLLM! By combining 4-bit weights (low memory) with 8-bit activations (high compute), we hit the sweet spot for both decoding and prefill — up to 58% faster TTFT and 45% faster TPOT vs W4A16 on Hopper.