Your agent remembers everything and understands nothing.
Most agent memory systems optimize for recall. The harder problem is what to forget, or more precisely, what to never store in the first place.
The default agent memory pipeline hands an LLM raw text and asks it to extract entities and relationships. The model decides the types, the labels, the attributes, all on its own.
The result is a knowledge graph that behaves like an expensive vector store. Entity types collapse into generic labels. Relationships flatten into a single "RELATES_TO."
The graph has the data, but no query can reach it with precision.
The problem is not retrieval. It is structure. And the fix is the same pattern that already works everywhere else in the AI stack: constrain the output space before generation, not after.
𝗘𝗻𝘁𝗶𝘁𝗶𝗲𝘀 define what the agent is allowed to remember. Pydantic models with typed fields and descriptive docstrings replace the LLM's guesswork with domain vocabulary it was never trained on.
𝗘𝗱𝗴𝗲𝘀 define how things connect. Source/target constraints on relationship types mean the graph can only form valid connections. If your schema has no edge connecting Project to Competitor, that relationship cannot exist in memory.
𝗧𝗲𝗺𝗽𝗼𝗿𝗮𝗹 𝗿𝗲𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻 handles what was true versus what is true. Fact resolution invalidates outdated edges while preserving history, so the graph never silently serves stale state.
The schema guides extraction at two points in the pipeline (entity extraction and fact extraction) while resolution and temporal processing run automatically downstream.
You define what to look for. The system handles deduplication, contradiction detection, and time-windowing without additional configuration.
A useful constraint: 10 entity types, 10 edge types, 10 fields per type. That forces you to model the 80% that matters rather than attempting completeness. Start with 3-4 of each and expand only when retrieval fails.
Zep AI's Graphiti does all of this as a fully open-source temporal knowledge graph library. Pydantic-based ontology definition, schema-guided extraction, entity resolution, fact resolution, and temporal windowing out of the box.
If you are building agent memory with any kind of domain specificity, it is worth looking at before rolling your own.
Check this out: https://t.co/8CboBlWffX
(don't forget to star 🌟)
Agent memory without schema discipline is storage without structure. The schema is what turns a pile of facts into a queryable model of your domain.
I covered this topic in more depth in the article quoted below.
Microsoft just open-sourced SkillOpt!
A framework for training agent skills like neural networks:
SkillOpt treats a plain markdown file as the trainable parameter of a frozen LLM agent, applying the same optimization discipline used in weight training: learning rates, validation gates, batch sizes, and epoch schedules.
The analogy maps precisely. The skill document is the parameter. Trajectory-derived edits are the gradient direction. An edit budget is the learning rate. A held-out split is the validation check.
Here's how it works.
A frozen model runs tasks with the current skill and produces scored trajectories. A separate optimizer model analyzes failures in minibatches, proposes structured add/delete/replace edits, and ranks them under a budget cap.
If the candidate skill improves performance on a held-out split, the edit is accepted. If not, it's rejected and stored so the optimizer avoids repeating failed changes.
The deployed output is a single best_skill. md file, typically 300 to 2,000 tokens. No weight changes, no extra inference-time calls.
The learned rules are compact and readable. These read like rules a thoughtful engineer would write after a day with the benchmark, except they were discovered automatically.
Learn more:
Paper: https://t.co/sdj5DW7t9h
GitHub: https://t.co/W3DcpBCni0
SkillOpt isn't the first system to treat skills as something you can optimize.
Hermes Agent independently built the same idea through a combination of skill_manage, Curator, and an optimization loop called GEPA that scores, mutates, and promotes skill documents across runs.
Two teams, different architectures, same conclusion: the skill file is the highest-leverage thing to optimize in a frozen-model agent.
I wrote a deep dive on how the Hermes agent works and covered all of these topics briefly.
The article is quoted below.
Introducing the newest Coral board, for efficient, on-device AI!
Check out the demos in the video:
- On-board speech translation
- Natural language controlling hardware
- Vision & sound generating music
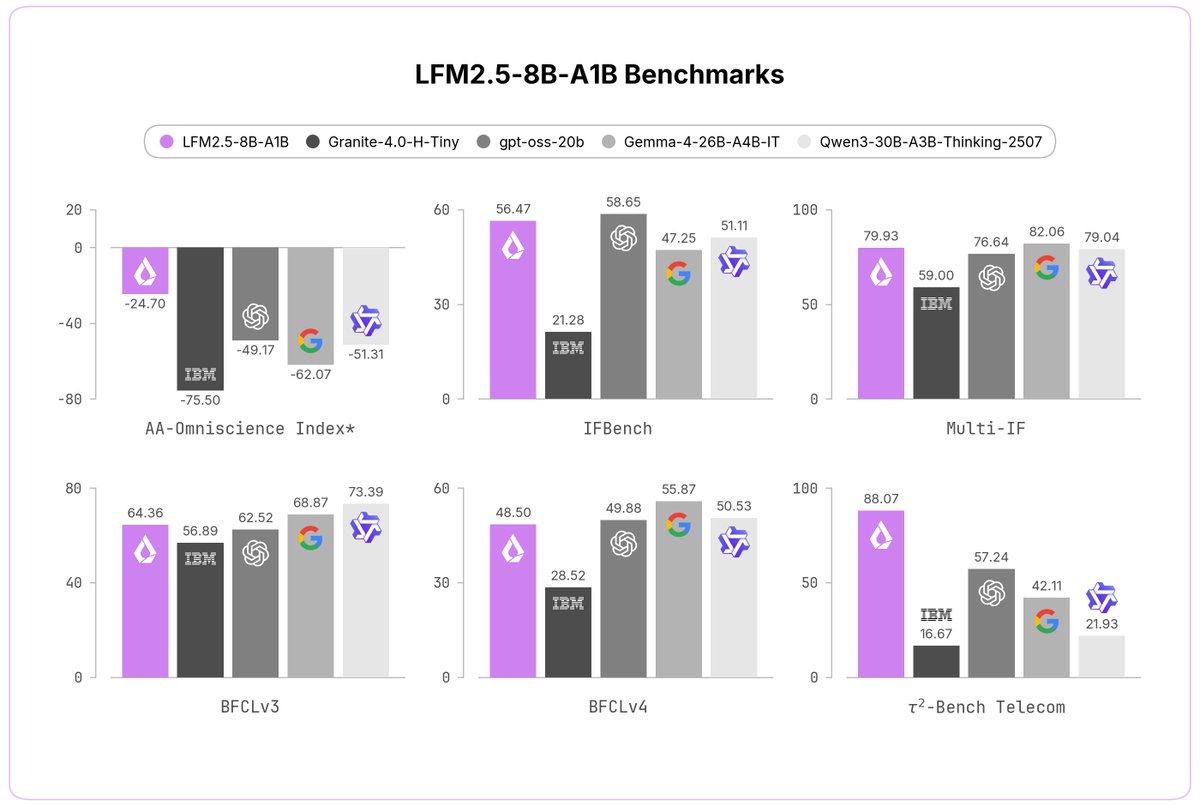
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟
Private MCP servers 🤝 OpenAI products
Your team can keep MCP servers inside your network while ChatGPT, Codex, and the Responses API connect through outbound-only HTTPS.
🔗 https://t.co/UVq0KpT0km
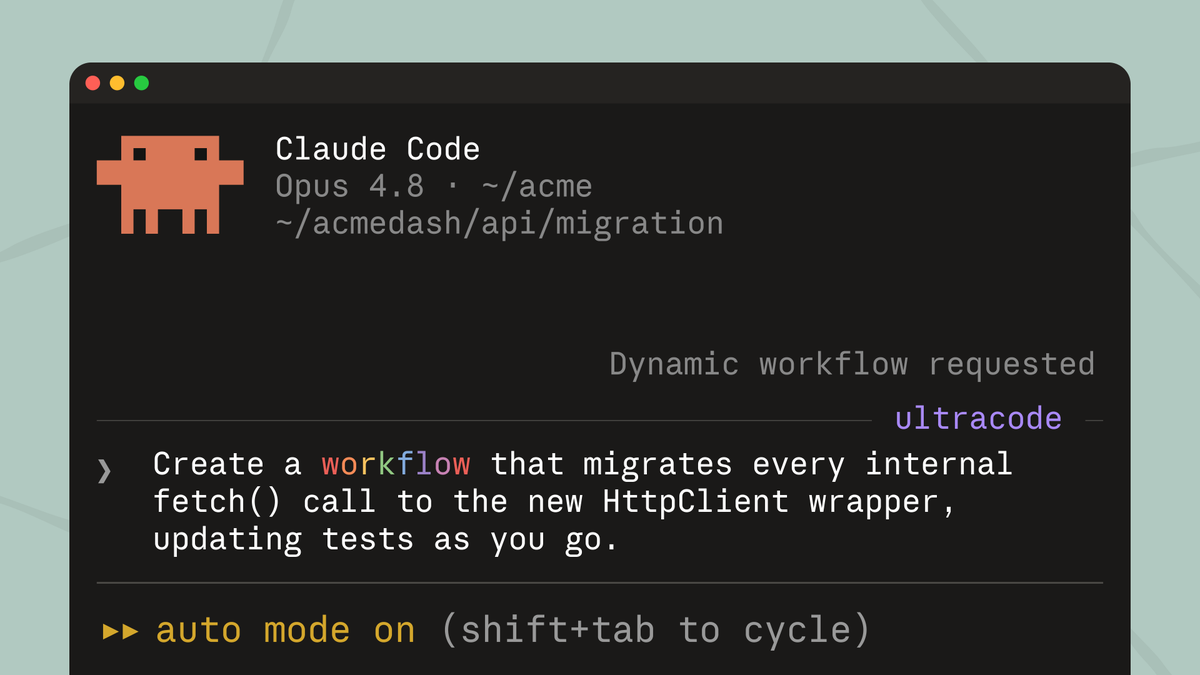
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
ANTHROPIC 🔥: Claude will soon receive a new file-based memory upgrade, offering users the option to choose between Memory Files and Classic memory.
> Organized notes Claude writes as you chat and reads when they're relevant. Browse and edit them anytime.
This feature appears to be a new iteration of the previously discovered "Knowledge Bases" and more closely resembles what memory works in always-on agents like OpenClaw and Hermes.
Considering a potential future debut of Claude Conway, Memory Files feature is likely an important preparation step.
We doubled max context length in Antigravity for Gemini 3.5 Flash.
Some of you have been hitting compaction many times for hard tasks, which hurt performance. This should help in those cases. Was going to reset quotas but just did a couple hours ago 🙂
Thanks for all of the Antigravity feedback over the last couple of days, especially around the IDE. Our intention was never to remove the IDE support for developers, and we should have been clearer with that in the product from the beginning.
We’ve made it clearer in 2.0 on how to connect to the IDE, fixed issues with opening the IDE on Windows machines, provided instructions to restore IDE settings & extensions, and more.
New releases for the Antigravity IDE and Antigravity 2.0 have rolled out with these changes.
We should have done better so we’re going to reset everyone’s Gemini quota for the week again.
PSA: the IDE in Antigravity 2.0 is alive and well, we just landed an update to the UI which makes it more clear (see top right).
Sorry for the confusion on this (pls keep feedback coming), we also just reset everyone’s weekly limits. Enjoy the weekend : )
Hermes Agent now has access to hundreds of browser skills through @browserbase’s new https://t.co/SZ93w9Z0mk hub, so agents can more reliably perform any task on the internet. You can try a skill from their catalog or contribute your own.
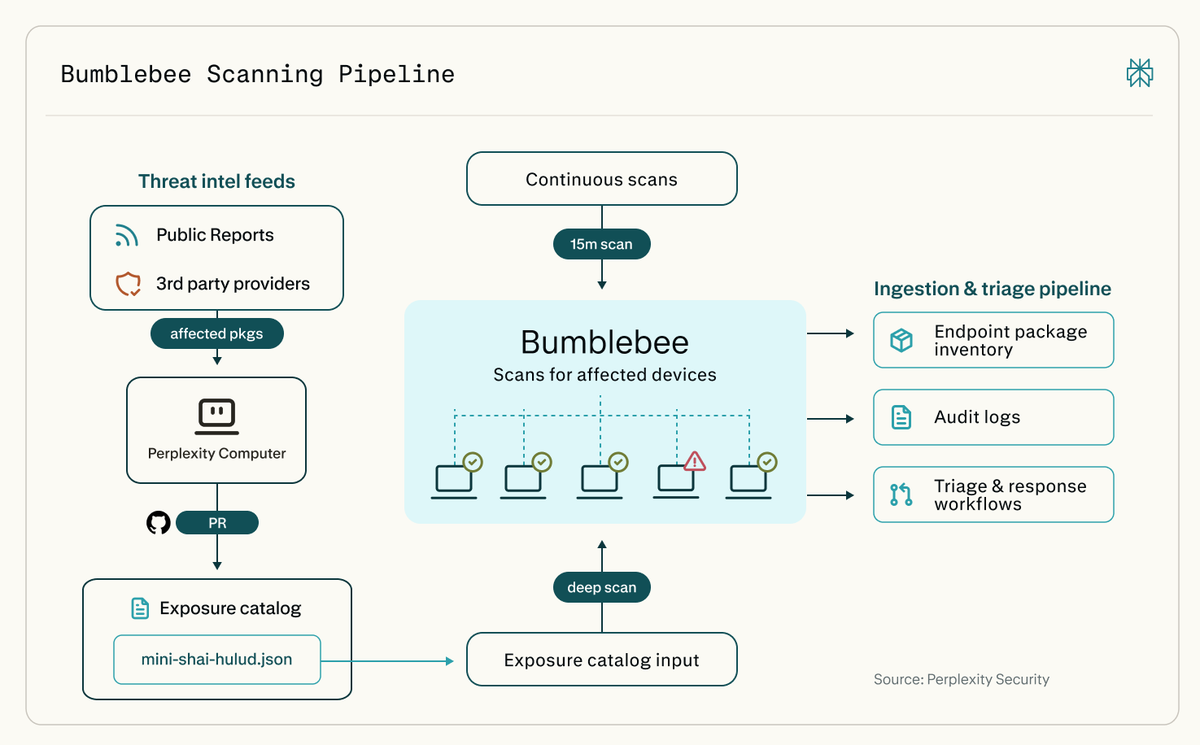
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
https://t.co/FOaWnF1yQy
Codex anywhere and everywhere, all the time.
Now your Mac doesn’t have to be unlocked for Codex to use your computer.
From your phone, Codex can securely use apps on your Mac, even when the screen is off and locked.
https://t.co/PCGK4i7FSF
Say hello to open source deep research for your favorite agent harness.
Our AI-Q agent skill packages the work of building a research pipeline into a portable skill. Drop it into your harness, and the agent delegates a research task to a local or hosted AI-Q server and gets back a detailed report with citations. See it in Codex below 👇
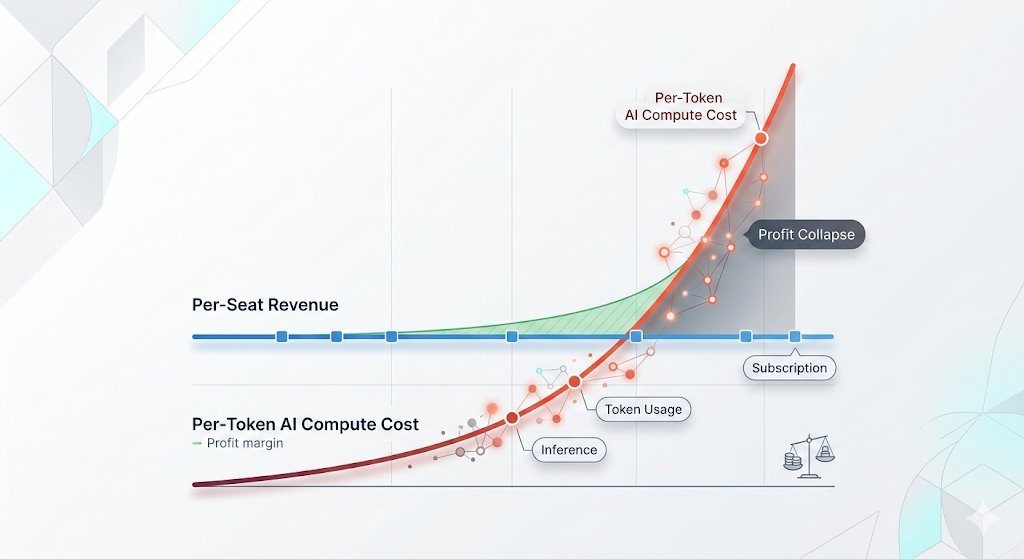
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
Karpathy's prediction about RL is coming true now!
He called reward functions unreliable and argued that a single reward number is too low-dimensional to teach an agent what "good" means for complex tasks. To solve this, Agents need a knowledge-guided review as a higher-dimensional feedback channel.
Every major AI lab trains models with RL today (OpenAI, Anthropic, DeepSeek).
And their key bottleneck has always been the reward functions.
GRPO by DeepSeek worked well for math and code because the environment gave a binary signal.
But for real agent tasks, someone still has to hand-code the scoring function. That takes days and breaks every time the pipeline changes.
RULER (implemented in OpenPipe ART, 10k stars) addresses the exact problem Karpathy identified.
The reward criteria are defined in plain English, and an LLM evaluates each trajectory against that description to provide feedback for training.
I trained a Qwen3 1.4B agent that plays 2048 using GRPO with this exact workflow.
In this case, the agent saw the board, picked a direction, and RULER evaluated the outcome, all from this natural language definition.
You can see the full implementation on GitHub and try it yourself.
Here's the ART Repo: https://t.co/fsoLXDK4Zu
(don't forget to star it ⭐ )
Just like RLHF replaced manual rankings and GRPO replaced the critic model, natural language rewards are replacing hand-coded scoring functions.
RL reward engineering is now prompt engineering.
I wrote a full walkthrough covering RL for LLM agents, from RLHF to GRPO to RULER, in the article below.