Here is a Citrini critique from a Macro-AI lens.
Citrini's "2028 Intelligence Crisis" direction of labor market impact is sensible. The velocity is wrong. His scenario timeline is off by ~ 5 years + because his AI capability assumptions are anecdotal, not grounded in the math of how models actually improve.
His core assumptions:
1) The AI feedback loop is sustained by "AI Investment Increases & AI Capabilities Improve" — implying that as long as you throw money at compute, you get better models that unlock capabilities replacing humans at a given task
2) He extrapolates from what he's observed anecdotally about AI agents to "smooth sailing" toward autonomous multi-week agents by 2027. This is a guess, not an informed view
Let's rigorize his feedback loop with some Macro-AI:
scaling laws → capabilities → task automation → displacement
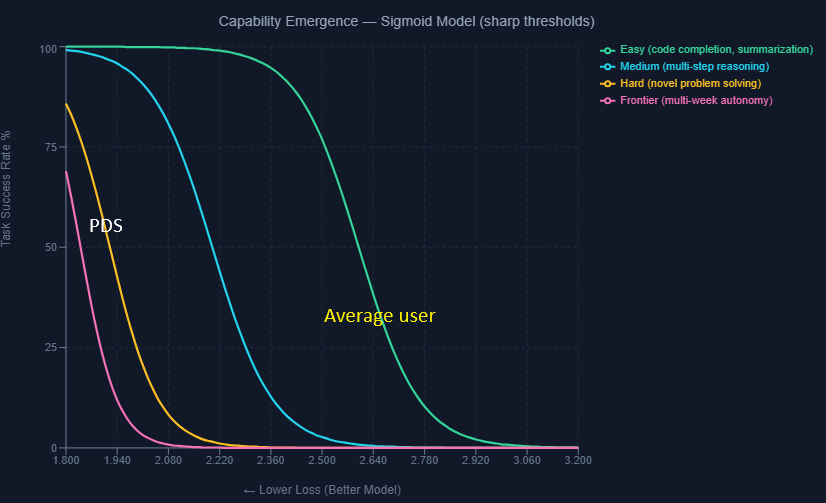
The relationship between scaling laws and capabilities is determined by a "Capability Transfer" function. This relationship is non-linear and task-dependent. Capabilities don't emerge linearly from loss improvements — they phase-transition at specific thresholds (I model this with a sigmoid in pic below). Du et al. (2024) validates pre-training loss as the sufficient proxy for capability emergence below task-specific thresholds.
The hard tasks Citrini envisions — autonomous multi-week work by 2028 — likely have thresholds near the irreducible loss floor (E ≈ 1.82 nats). But here's the deeper issue: next-token prediction is a proxy objective. A model can approach E without acquiring the causal reasoning, goal persistence, and calibrated uncertainty that autonomous work demands. The frontier labs' pivot to post-training (RLHF, inference-time compute, tool use) is an implicit admission of this gap. All this to say, some hard tasks may not be solvable by scaling compute alone - which is what Citrini assumes.
If we know the capability transfer thresholds and map them to loss levels (and thus compute), we can estimate when complex tasks become feasible. (yup -> we can actually model this)
Using 0.40 OOM/year in compute growth and 0.30 OOM/year in algorithmic efficiency gains, I model that professional replacement (defined workflows: customer service, routine legal, basic analysis) starts mid-2026 — but cognitive displacement (multi-week autonomy, novel problem solving) only arrives ~2031. Citrini's crisis requires cognitive displacement. So his timeline starts at 2031 at earliest.
**AND** we haven't even addressed two more constraints that push it further: agent reliability decays exponentially with task complexity and the training data wall.
If I can vibe code myself into a web dev, I'll upload the interactive model at https://t.co/kdlYUwTjvt for you to stress-test the assumptions yourself.
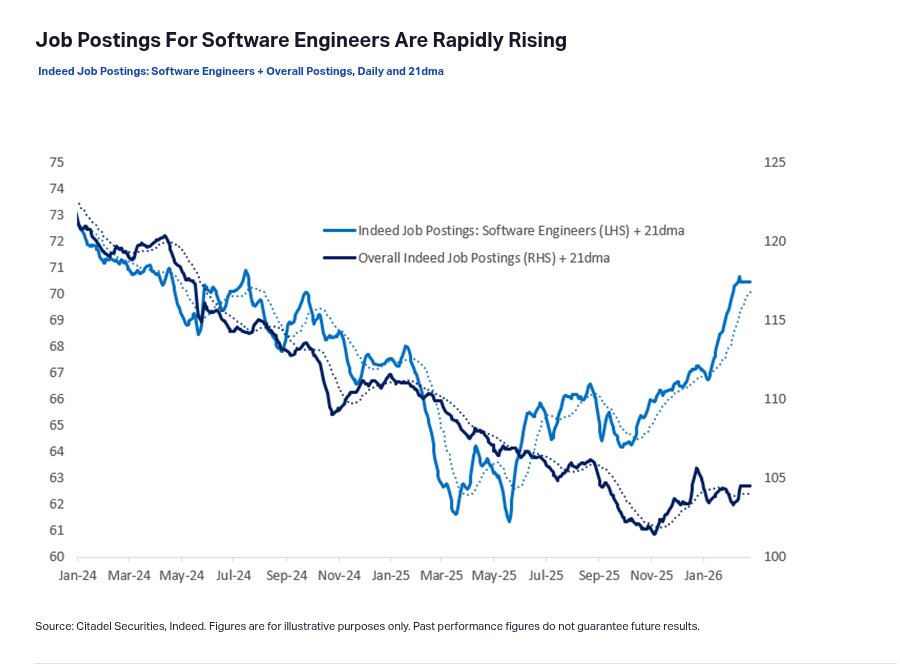
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
The markets can be irrational for a long time. People investing are not at frontier labs or are not using AI beyond a conversational capability.
A litmus test. Ask market participants - who think vibe coding will replace SAAS, who is going to verify the additional billions lines of codes that an AI system at scale can produce per month (maybe per week)?
Automation comes only after verification, so tell me how less software engineers or non specialists (software companies) are going to verify codebases that are growing of orders of magnitude a month (a week)?
Today, we launched the AI Registered Apprenticeship Innovation Portal, a one-stop resource to help organizations build AI literacy and develop AI-focused apprenticeship programs.
Under @POTUS’ leadership, we’re positioning American Workers to lead in the age of AI 🇺🇸
https://t.co/Wc76dKSIcW
Did a very different format with @reinerpope – a blackboard lecture where he walks through how frontier LLMs are trained and served.
It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk.
It’s a bit technical, but I encourage you to hang in there - it’s really worth it.
There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him.
Recommend watching this one on YouTube so you can see the chalkboard.
– How batch size affects token cost and speed
– How MoE models are laid out across GPU racks
– How pipeline parallelism spreads model layers across racks
– Why Ilya said, “As we now know, pipelining is not wise.”
– Because of RL, models may be 100x over-trained beyond Chinchilla-optimal
– Deducing long context memory costs from API pricing
– Convergent evolution between neural nets and cryptography
Here is a Citrini critique from a Macro-AI lens.
Citrini's "2028 Intelligence Crisis" direction of labor market impact is sensible. The velocity is wrong. His scenario timeline is off by ~ 5 years + because his AI capability assumptions are anecdotal, not grounded in the math of how models actually improve.
His core assumptions:
1) The AI feedback loop is sustained by "AI Investment Increases & AI Capabilities Improve" — implying that as long as you throw money at compute, you get better models that unlock capabilities replacing humans at a given task
2) He extrapolates from what he's observed anecdotally about AI agents to "smooth sailing" toward autonomous multi-week agents by 2027. This is a guess, not an informed view
Let's rigorize his feedback loop with some Macro-AI:
scaling laws → capabilities → task automation → displacement
The relationship between scaling laws and capabilities is determined by a "Capability Transfer" function. This relationship is non-linear and task-dependent. Capabilities don't emerge linearly from loss improvements — they phase-transition at specific thresholds (I model this with a sigmoid in pic below). Du et al. (2024) validates pre-training loss as the sufficient proxy for capability emergence below task-specific thresholds.
The hard tasks Citrini envisions — autonomous multi-week work by 2028 — likely have thresholds near the irreducible loss floor (E ≈ 1.82 nats). But here's the deeper issue: next-token prediction is a proxy objective. A model can approach E without acquiring the causal reasoning, goal persistence, and calibrated uncertainty that autonomous work demands. The frontier labs' pivot to post-training (RLHF, inference-time compute, tool use) is an implicit admission of this gap. All this to say, some hard tasks may not be solvable by scaling compute alone - which is what Citrini assumes.
If we know the capability transfer thresholds and map them to loss levels (and thus compute), we can estimate when complex tasks become feasible. (yup -> we can actually model this)
Using 0.40 OOM/year in compute growth and 0.30 OOM/year in algorithmic efficiency gains, I model that professional replacement (defined workflows: customer service, routine legal, basic analysis) starts mid-2026 — but cognitive displacement (multi-week autonomy, novel problem solving) only arrives ~2031. Citrini's crisis requires cognitive displacement. So his timeline starts at 2031 at earliest.
**AND** we haven't even addressed two more constraints that push it further: agent reliability decays exponentially with task complexity and the training data wall.
If I can vibe code myself into a web dev, I'll upload the interactive model at https://t.co/kdlYUwTjvt for you to stress-test the assumptions yourself.
@ylecun@Ph_Aghion@erikbryn 💯
Most macroeconomists thou are not close enough to the algorithmic capabilities of the models so they struggle understanding the capability transfer function
@ylecun
Here is a Citrini critique from a Macro-AI lens.
Citrini's "2028 Intelligence Crisis" direction of labor market impact is sensible. The velocity is wrong. His scenario timeline is off by ~ 5 years + because his AI capability assumptions are anecdotal, not grounded in the math of how models actually improve.
His core assumptions:
1) The AI feedback loop is sustained by "AI Investment Increases & AI Capabilities Improve" — implying that as long as you throw money at compute, you get better models that unlock capabilities replacing humans at a given task
2) He extrapolates from what he's observed anecdotally about AI agents to "smooth sailing" toward autonomous multi-week agents by 2027. This is a guess, not an informed view
Let's rigorize his feedback loop with some Macro-AI:
scaling laws → capabilities → task automation → displacement
The relationship between scaling laws and capabilities is determined by a "Capability Transfer" function. This relationship is non-linear and task-dependent. Capabilities don't emerge linearly from loss improvements — they phase-transition at specific thresholds (I model this with a sigmoid in pic below). Du et al. (2024) validates pre-training loss as the sufficient proxy for capability emergence below task-specific thresholds.
The hard tasks Citrini envisions — autonomous multi-week work by 2028 — likely have thresholds near the irreducible loss floor (E ≈ 1.82 nats). But here's the deeper issue: next-token prediction is a proxy objective. A model can approach E without acquiring the causal reasoning, goal persistence, and calibrated uncertainty that autonomous work demands. The frontier labs' pivot to post-training (RLHF, inference-time compute, tool use) is an implicit admission of this gap. All this to say, some hard tasks may not be solvable by scaling compute alone - which is what Citrini assumes.
If we know the capability transfer thresholds and map them to loss levels (and thus compute), we can estimate when complex tasks become feasible. (yup -> we can actually model this)
Using 0.40 OOM/year in compute growth and 0.30 OOM/year in algorithmic efficiency gains, I model that professional replacement (defined workflows: customer service, routine legal, basic analysis) starts mid-2026 — but cognitive displacement (multi-week autonomy, novel problem solving) only arrives ~2031. Citrini's crisis requires cognitive displacement. So his timeline starts at 2031 at earliest.
**AND** we haven't even addressed two more constraints that push it further: agent reliability decays exponentially with task complexity and the training data wall.
If I can vibe code myself into a web dev, I'll upload the interactive model at https://t.co/kdlYUwTjvt for you to stress-test the assumptions yourself.
There's a dimension of the AI frontier that gets zero airtime next to compute scaling and Blackwell trained models — and it's where the actual alpha lives.
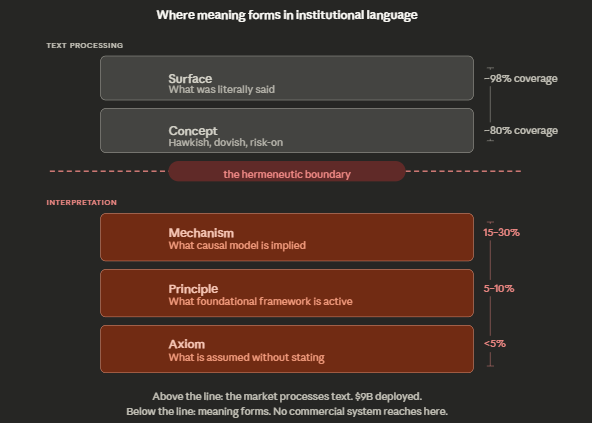
Hermeneutics is the study of interpretation — not what a text says, but what it means. For 200 years it's been confined to philosophy departments. It now has a direct application in markets that nobody is exploiting.
The entire financial NLP ecosystem — $9B deployed — operates at what hermeneutics would call the 'surface' and 'concept' layers. What was literally said, what category it maps to. This is textual processing, not interpretation.
Interpretation begins at the mechanism layer: what causal model does this framing imply? 'Softening' through demand destruction and 'softening' through supply normalization are the same word pointing at completely different forward worlds. The concept layer can't distinguish them. The hermeneutic layer must.
Below mechanism: principle (what foundational framework is active) and axiom (what's assumed without being stated). The market's coverage at these layers is sub 10% — and the participants processing there are doing it in their heads, unscalable.
The processing cliff between concept and mechanism is a measured 44 points of F1 accuracy. That cliff is the boundary between text processing and interpretation. Most alpha theories rely on attention asymmetry. This relies on interpretive asymmetry — a gap that requires architectural change, not redirected attention.
The LLM paradigm makes it possible to perform hermeneutic operations computationally — holding multiple interpretive horizons open, tracking epistemic modality, detecting framework shifts across time. But only when architected as structured extraction systems, not conversational tools. The gap between those two architectures is the gap between reading and interpreting.
Markets have always rewarded the latter. They've just never been able to scale it.
@WhiteHouse Countries will just give a call to Iran.. basically we gave them agency over the strait and wasted ton of tax payer money..
Anyways
Let’s get back to work Mr President
Here is a Citrini critique from a Macro-AI lens.
Citrini's "2028 Intelligence Crisis" direction of labor market impact is sensible. The velocity is wrong. His scenario timeline is off by ~ 5 years + because his AI capability assumptions are anecdotal, not grounded in the math of how models actually improve.
His core assumptions:
1) The AI feedback loop is sustained by "AI Investment Increases & AI Capabilities Improve" — implying that as long as you throw money at compute, you get better models that unlock capabilities replacing humans at a given task
2) He extrapolates from what he's observed anecdotally about AI agents to "smooth sailing" toward autonomous multi-week agents by 2027. This is a guess, not an informed view
Let's rigorize his feedback loop with some Macro-AI:
scaling laws → capabilities → task automation → displacement
The relationship between scaling laws and capabilities is determined by a "Capability Transfer" function. This relationship is non-linear and task-dependent. Capabilities don't emerge linearly from loss improvements — they phase-transition at specific thresholds (I model this with a sigmoid in pic below). Du et al. (2024) validates pre-training loss as the sufficient proxy for capability emergence below task-specific thresholds.
The hard tasks Citrini envisions — autonomous multi-week work by 2028 — likely have thresholds near the irreducible loss floor (E ≈ 1.82 nats). But here's the deeper issue: next-token prediction is a proxy objective. A model can approach E without acquiring the causal reasoning, goal persistence, and calibrated uncertainty that autonomous work demands. The frontier labs' pivot to post-training (RLHF, inference-time compute, tool use) is an implicit admission of this gap. All this to say, some hard tasks may not be solvable by scaling compute alone - which is what Citrini assumes.
If we know the capability transfer thresholds and map them to loss levels (and thus compute), we can estimate when complex tasks become feasible. (yup -> we can actually model this)
Using 0.40 OOM/year in compute growth and 0.30 OOM/year in algorithmic efficiency gains, I model that professional replacement (defined workflows: customer service, routine legal, basic analysis) starts mid-2026 — but cognitive displacement (multi-week autonomy, novel problem solving) only arrives ~2031. Citrini's crisis requires cognitive displacement. So his timeline starts at 2031 at earliest.
**AND** we haven't even addressed two more constraints that push it further: agent reliability decays exponentially with task complexity and the training data wall.
If I can vibe code myself into a web dev, I'll upload the interactive model at https://t.co/kdlYUwTjvt for you to stress-test the assumptions yourself.