Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
@JustJake Yeah it was a dream of mine to get my hands on one of these. Intel would have made a killing post~2025 if they stuck with them for a little while longer.
Perfect disk for dev work and dbs
🚀 GLM-5.1-HighSpeed is live: 400 tokens/s — a new speed ceiling for flagship-tier LLM APIs.
Not a smaller model traded for speed. A flagship from @Zai_org that's also the fastest.
📖 Full technical deep-dive 👇
https://t.co/nLEFdMf2Ea
Please go read this - really great paper with some fancy and clever training and architecture decisions
Here’s some cool things in no particular order:
HRM-Text omits broad raw-text pretraining and trains exclusively on instruction-response pairs from scratch.
MagicNorm, which ex-ploits the asymmetry between the forward and backward computational horizons induced by truncated backpropagation through time.
combining small recurrent reasoning models with external or learned knowledge stores is a promising direction
We hypothesize that the instabilities observed under deep BPTT in looped architectures are a consequence of the intrinsically multiplicative structure of gradient propagation through repeated iterations. Specifically, gradients backpropagate through products of Jacobian-like operators across loop steps, and theory for products of many random matrices predicts that the logarithm of the norm of such products is approximately Gaussian, implying lognormal-like variability in gradient magnitudes and increasing separation between typical and extreme values as backward depth grows
The HRM-Text paper is now available 🎉
HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning.
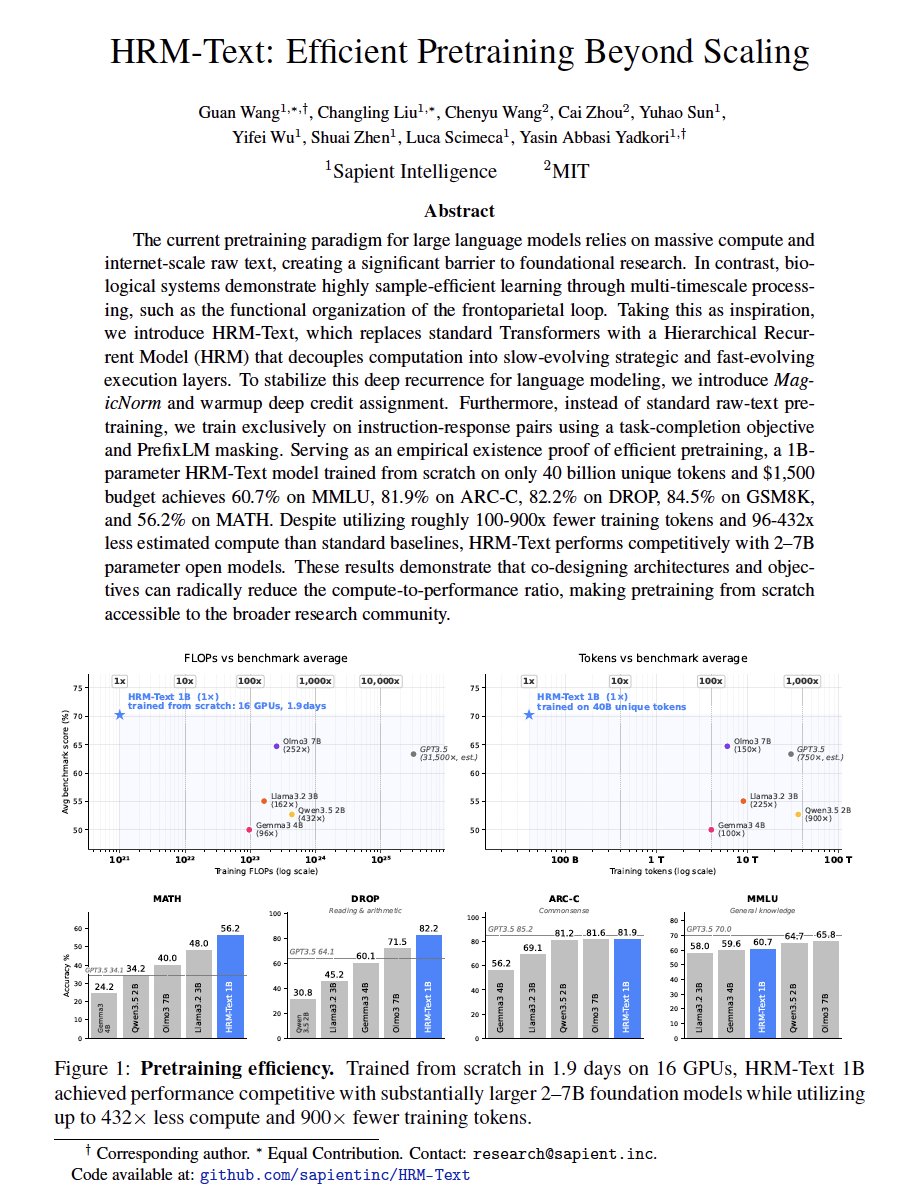
At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements.
1B parameters
40B unique tokens
~1 day of pretraining
~$1000 training cost