AI agents are changing creative workflows.
Meshy's 3D Agent lets you brainstorm, iterate, and build in one conversation.
Less tool switching.
More creating.
Introducing Meshy 3D Agent 🚀 The world's first AI agent for 3D creation, now in Beta.
Just chat — the agent will:
🧠 Brainstorm with you, pitching directions first
🎨 Generate visuals in batches, refined through chat
🧊 Turn your favorite into 3D — print, download, anywhere
📚 Answer your 3D questions in-line
Create 3D in conversation with Meshy Now → https://t.co/3g1voTIUhY
Have you ever thought to yourself: I really don't want to make this PowerPoint.
Good news: ChatGPT can now create and edit presentations directly in PowerPoint.
Build, update, understand, and polish presentations directly in PowerPoint while keeping slides editable.
Now in beta, we’d love your feedback 👀
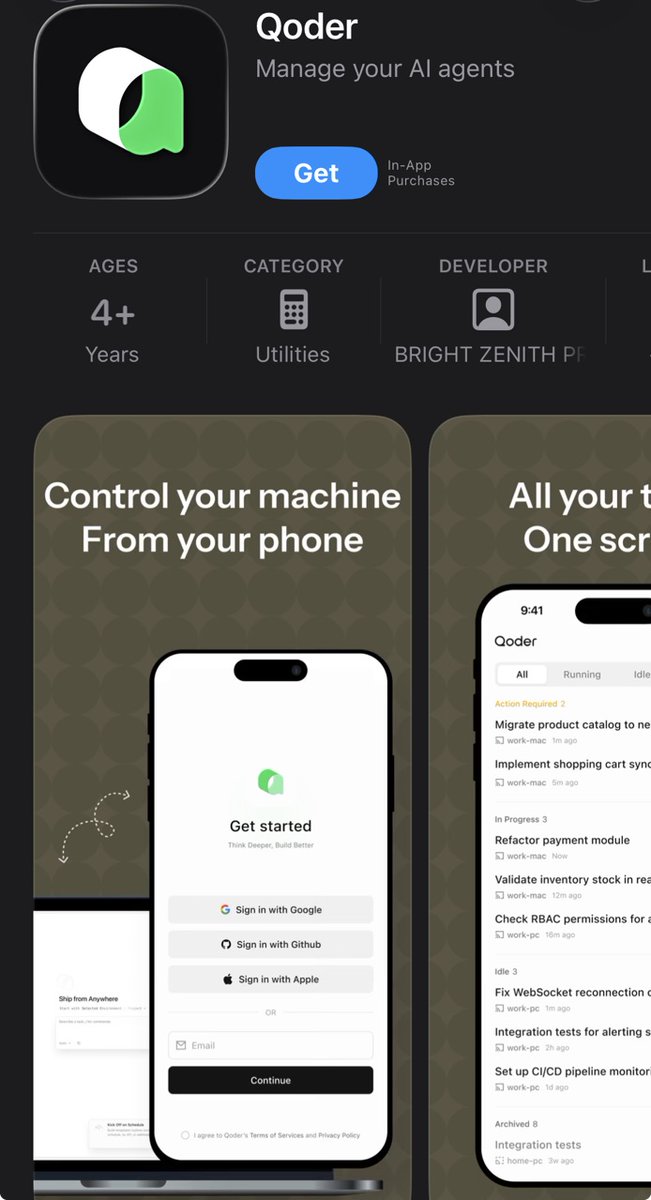
AI agents are changing how work feels.
You don’t wait in front of your computer anymore. You just check in during small moments.
Qoder iOS Remote Control fits this shift.
Work becomes something you step into, not sit through.
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
📁 Fei-Fei Li, former Google Chief Scientist, says the industry is dangerously fixated on language models.
Most of the real economy is physical, perceptual and spatial.
Once AI fully understands the visual world, it stops being a chatbot and starts becoming infrastructure.
Introducing Daybreak: frontier AI for cyber defenders.
Daybreak brings together the most capable OpenAI models, Codex, and our security partners to accelerate cyber defense and continuously secure software.
A step toward a future where security teams can move at the speed defense demands.
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
When AI can break down tasks, determine steps, and check results on its own,
humans are devolving from "operators"
into mere "confirmation buttons."
This reminds me of the humans in Wall-E who escaped Earth and whose only job was simply to exist...
For the past few years, AI has been saying:
"I can help you write, help you think, and help you revise."
Starting in 2026, it changed its tune:
"You don't need to worry about it, I'll do it."
This isn't an increase in efficiency.
This is a change of roles.
Stop creating that garbage music with only four-bar loops! Try the new Mureka V8 model
, ever-changing melodies, and expressive vocals—let you tell stories with music!
The MusiCoT style logic is an interesting direction for the development of artificial intelligence music.
🚀Mureka V8 — Goodbye "AI feel," hello release-ready music. Powered by our breakthrough MusiCoT (Music Chain of Thought) to transform "generated" into "published":
• Lead Singer Aura: Confident, expressive vocals that truly carry the story.
• Human-Like Logic: Mimics human composition for coherent structure and progression.
• Valid Musicality: Melodies that develop, not just experimental clips.
Real songs, ready for your actual workflow.
Let's watch the music generated by Mureka's cutting-edge V8 model.
AI artist avatar & MV created by @Skywork_ai
#MCE #mureka #aimusic
It’s already 2026, and I still don’t see the point of “general” LLMs that can only chat but can’t remember.
Once the conversation gets slightly vague, they start hallucinating.
Honestly, my 90-year-old grandmother is smarter.
👉 Star the repo: https://t.co/j6LQMPl5dG
👉 Learn more: https://t.co/eb9WYdTNad
👉 Read the paper: https://t.co/gMKb46hO2Q
Because real agents shouldn’t just recall —
they should remember why you chose what you did.
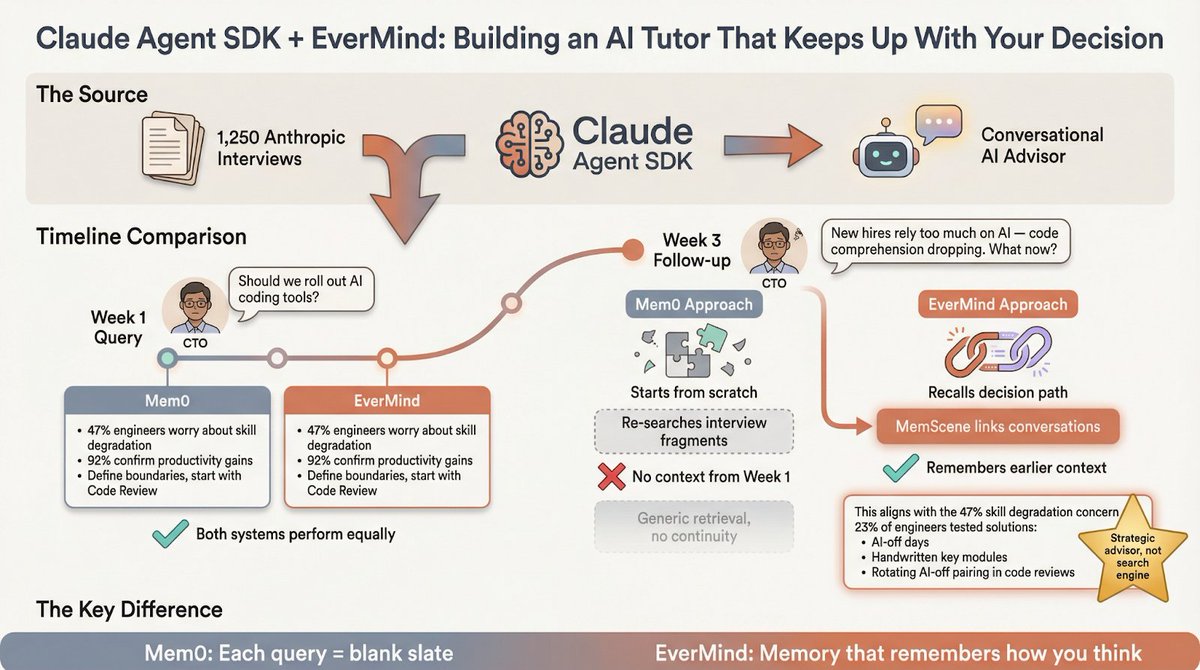
Claude Agent SDK + EverMind: Building an AI Tutor That Keeps Up With Your Decision
Your boss wants “AI strategy.”
So they send you a stack of research reports.
But what you really want to know is:
What do the 1,250 people already using AI actually think?