Join us in San Francisco on June 23 for an evening with @redpandadata and @datastrato on building the real-time data stack for AI agents.
- Streaming ingestion
- Metadata Management
- Real-time analytics and hybrid search
👉 Register: https://t.co/52To1gmR21
#agents
#Iceberg is evolving from just a table format to a key data foundation for real-time analytics, lakehouse, and AI.
Join us for a webinar on running Iceberg in real production scenario. Lessons from Lucid Motors.
👉RSVP: https://t.co/YSyWJQptu5
Come meet us at PGday Boston! Let's chat about PG + OLAP architecture.
We offer native CDC sync from Postgres WAL, real time, no middleware to manage.
Postgres stays as the transactional source of truth, and Doris can handles the analytical side.
🔗https://t.co/cPBnp5cZ9c
We built AgentLogsBench for AI agent observability
The benchmark test how databases handle four core access patterns of AI agent observability
Combined score:
Doris: 1.28x
Elasticsearch: 3.11x
ClickHouse: 11.91x
DuckDB: 73.48x
Postgres: 439.55x
🔗https://t.co/HHJSEnpZQf
Running a RAG demo is very different from deploying a retrieval system for production
Apache Doris has helped firms like ByteDance to build production-ready retrieval system
Three key decisions:
- Chunk Shape
- Embedding Strategy
- Vector Index
🔗https://t.co/nM3CjJ6HW2
We have upgraded the Spill to Disk feature in Apache Doris 4.1, addressing OOM (out of memory) issues
1️⃣ Full operator coverage: Hash Join, Aggregation, and Sort operators all support Spill to Disk.
2️⃣ Recursive spill
3️⃣ Dynamic triggers
🔗https://t.co/WbHT4Y5i2U
Sydney data engineers 👋
Special meetup with @VeloDB_IO — Thu 11 June, 5:30pm @ Stone & Chalk, Tech Central
Two talks on real-time analytics for AI systems + live demo
Free. Food provided. Great people.
RSVP 👇
Last Call 📣: This May 18-19, the VeloDB team'll be at AI & Big Data Expo North America.
If your team is evaluating AI data infra or looking to consolidate search and analytics stack, find us at Booth 252.
📍 San Jose McEnery Convention Center, CA
🎟️https://t.co/LYq4v9y8YJ
Come join us in San Francisco on May 20 to build a data layer that can keep up with the real-time, high-concurrent, and multimodal demands of enterprise agents.
Partner @puppyquery and @cocoindex_io
📅 Wed, May 20, 5:30 – 7:30 PM
📍 Trellis Cafe, SF
🎟️ https://t.co/kIy3n3nXg6
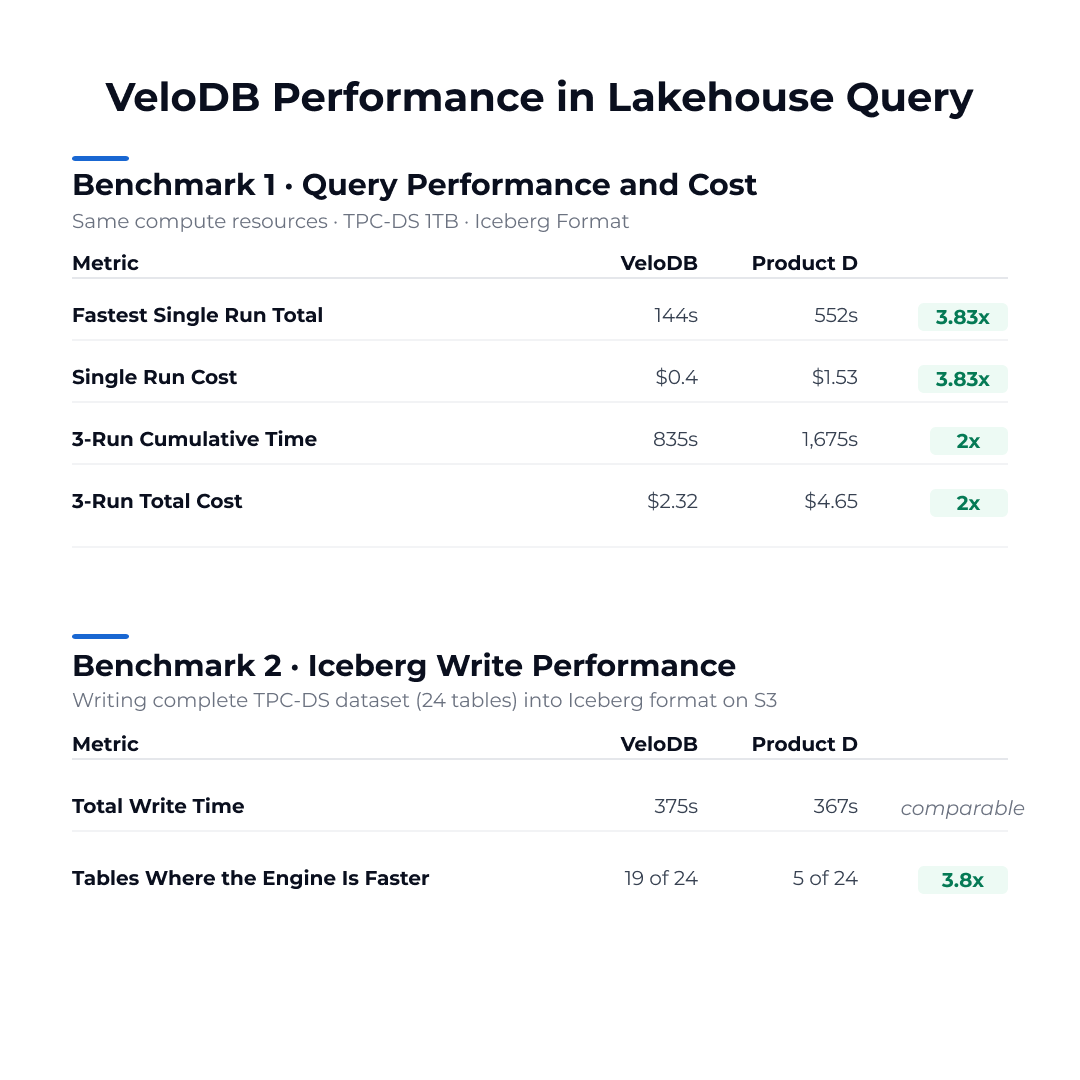
VeloDB supports lakehouse analytics natively, querying and write data for Iceberg table (V2/V3) directly on object storage, without moving data.
See how VeloDB performs in lakeshoue queries:
🔗 Full benchmarks + technical breakdown: https://t.co/Od22itw0u0
Come join us in Bengaluru this Saturday for Lakehouse at Scale: Apache Doris × OLake @_olake
- Apache Doris powers AI agents with hybrid search
- Iceberg table maintenance at CDC scale
📅Saturday, May 9, 11:00 AM
📍 Hustlehub Tech Park, Bengaluru
🎟️ https://t.co/kTJMxfcEMa
Check out @khameshra's demo for setting up an Iceberg lakehouse with Apache Doris in 15 minutes.
The stack:
PostgreSQL → @_olake (CDC) → Apache Iceberg on Object Storage → Apache Doris (Query Engine)
🔗 Full walkthrough: https://t.co/EDagt0vcam
Join us and Supermetal for a webinar to build a real-time analytics stack with lean, affordable real-time CDC.
👉 RSVP: https://t.co/ZUpcPEHFYm
Supermetal offers real-time CDC as a single Rust binary. Pair it with VeloDB to get continuous ingestion and sub-second queries.
We built a Snowflake alternative on #AWS
Results for a team that migrated from Snowflake to the alternative:
- 80% cost reduction
- Ingestion latency down 5-10 minutes to 1-2 seconds
- 90x query performance boost on 475M row scans: 90x improvement
🔗https://t.co/OmJJCHWOWH
We helped ZTO Express run real-time analytics in a demanding situation: 500 million record updates per day, on a single 4.5-billion-row table with 200+ columns.
ZTO is one of Asia's largest express delivery firms, handling 35 billion packages a year
🔗https://t.co/AuBLrQzFqk
Apache Doris can be at the center of an open observability system. It works well with other ingestion and visualization tools.
Ingestion:
- ELK: FileBeat, LogStash
- OpenTelemetry
- Kafka
Visualization:
- Grafana
- Kibana
🔗 https://t.co/EWimGXLYvp
Introducing native CDC from #PostgreSQL and MySQL to VeloDB Cloud
VeloDB Cloud now connects directly to PostgreSQL WAL and MySQL Binlog, no need for traditional CDC pipeline like Debezium + Kafka + Flink + custom connectors.
🔗https://t.co/C5ChveSRrf