How do you scale enterprise OLAP for complex financial analytics on AWS?
Amazon’s FinTech team shares how they scaled StarRocks on Amazon EKS, achieving sub-5s standard queries, sub-20s complex queries, and support for 1,000 concurrent users.
Learn more:https://t.co/CEHlgs0haV
🆕 A while back, @open_metadata added the StarRocks connector.
This makes it easier to bring metadata into OpenMetadata, including schemas, tables, column types, and view definitions via StarRocks’ MySQL-compatible interface.
Setup guide: https://t.co/OIhAFgdfso
Iceberg acceleration only works if it stays fresh.
StarRocks 4.1 introduces Incremental Materialized Views for Apache Iceberg. That means faster refresh, lower compute cost, and fresher analytics at lakehouse scale.
Learn more👇
https://t.co/XjBdQBZKaj
Semi-structured data in Apache Iceberg just got easier to analyze.
🆕 With StarRocks 4.1, you can query VARIANT data in Iceberg tables natively—no complex preprocessing or pipeline workarounds.
See what’s new and how it works 👇
https://t.co/pu4DbGGdIg
CelerData is now PhoenixAI. 🔥
Same team, same database, same commitment — sharper focus on what we've always been building toward: the analytical database for the age of AI agents.
Welcome to PhoenixAI 👉 https://t.co/9b8yUJzABy
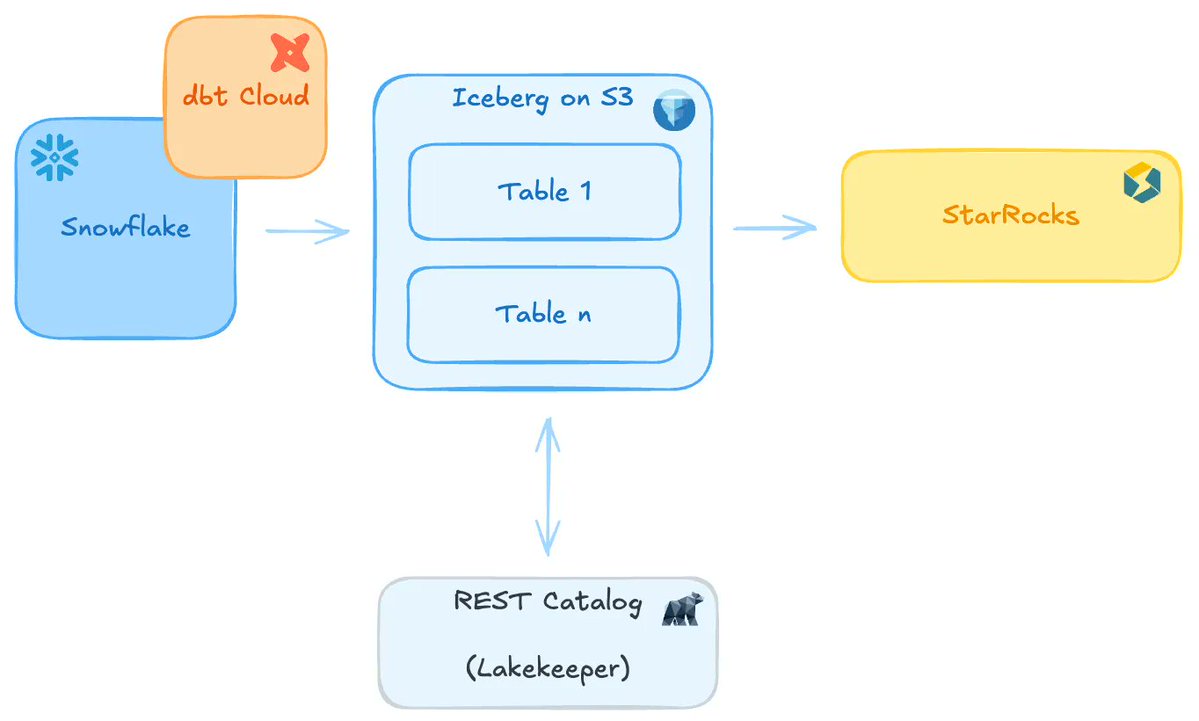
Great write-up from Fresha on Snowflake, Apache Iceberg, Lakekeeper, dbt, and StarRocks in practice.
A very honest look at what works, what gets complicated, and what teams should watch for when building on Snowflake+Iceberg.
Read the full article: https://t.co/BQd9TmXu9h
Telescope is a web based log viewer that lets teams explore Kubernetes, Docker, ClickHouse, and StarRocks logs through one interface with filtering, graphs, RBAC, and GitHub authentication
➜ https://t.co/ntoZEJcT1L
Static runbooks go stale. Tribal debugging knowledge gets lost.
We open-sourced starrocks-debug-skills, an AI troubleshooting skill built from real production database incidents, diagnostic flows, and on-call lessons.
Read more: https://t.co/H5vSzPRG3s
StarRocks community user Fresha is heading to Confluent Current London 2026 with 2 StarRocks-related talks on real-time analytics and streaming architecture.
Attending May 19–20? Catch the sessions and connect with the community. 👇
https://t.co/8FaZvLfz62
Have you ever had a table design that worked perfectly—until one tenant got huge?🤯
StarRocks 4.1 helps multi-tenant tables adapt as data grows and workloads shift, with Range distribution, large tablets, and automatic split/merge.
Learn more: https://t.co/YC1CNbTQDX
Have you ever had Debezium replication stall silently? No errors. No alarms. Just nothing.
We hit this with a customer at One2N on a standalone Debezium Server with Postgres and a custom CDC sink into StarRocks.
Apache Iceberg setup doesn’t have to be painful.
This walkthrough shows how to run Iceberg locally with StarRocks + MinIO using Docker Compose — then create catalogs, tables, insert data, query it, and inspect the storage layout.
Watch the demo: https://t.co/yyGlcJbrCI
What’s new in StarRocks 4.1?
Adaptive data distribution. Faster schema evolution. Better cache observability. Deeper Iceberg support.
A release built to simplify production analytics at scale.
Read the overview: https://t.co/ywYjf76DNF
We talk a lot about using AI to query data, but what about using AI to manage the database?
TRM Labs (@trmlabs) built a closed-loop AI agent to autonomously manage StarRocks upgrades.
Learn how they took #AIOps to the next level: https://t.co/OXAKRNo1ls
Part 3 of the StarRocks Monitor & Alert Guide covers how to monitor application availability — from query failures and P95 latency spikes to ingestion lag, MV refresh failures, and schema change issues.
Level up your alerting strategy👉https://t.co/TI0mFU9pnU
StarRocks 4.1.0 is now available! 🚀
This release brings major improvements to shared-data architecture and stronger support for Iceberg.
Full release notes: https://t.co/xOiRVhG8Cm
Huge thanks to everyone in the StarRocks community who helped make this release possible! 🎉