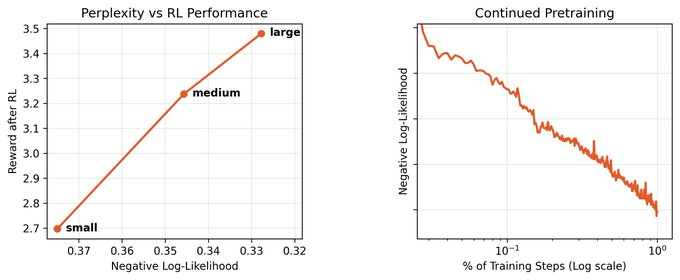
C2.5 is the same pretrain as C2, but powered by a much better and stronger midtrain (nearly an OOM more FLOPS)!
The base model matters a ton for RL, so we're very excited for the power of Colossus 2 to push this way further
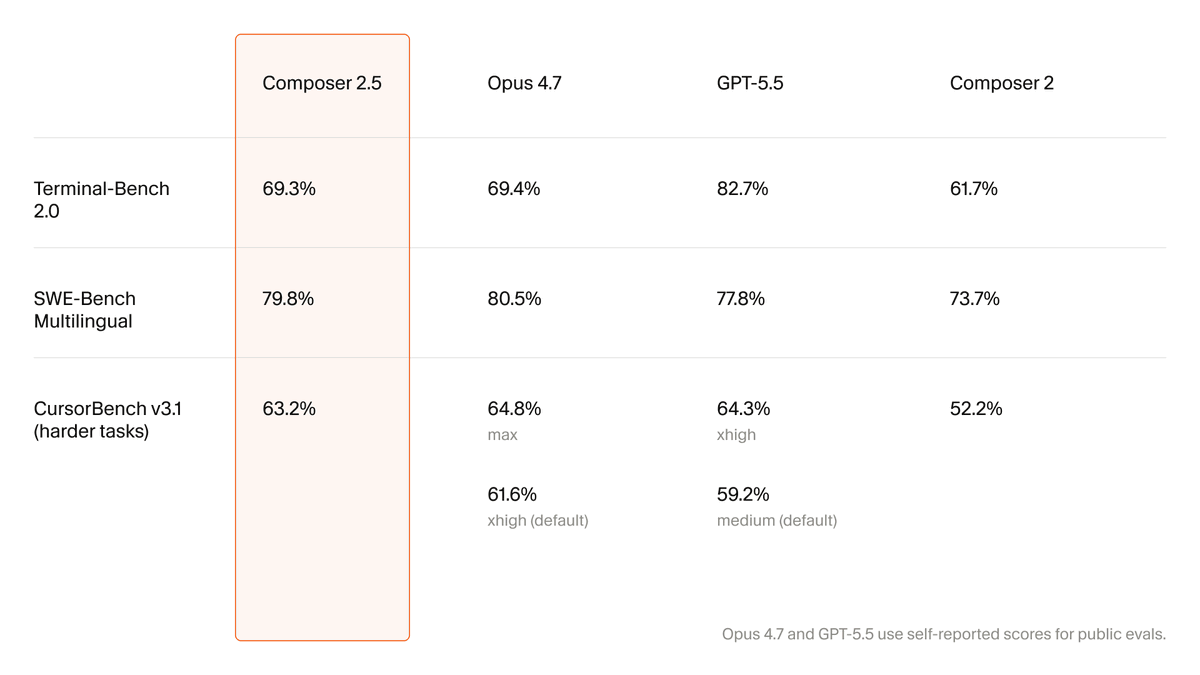
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
@varun_kr great question! don't think we have definitive answers here, but if you believe that RL is doing some "low-rank" adaptation, should be straightforward to unlearn. of course, you lose all the juice from previous RL, but our RL stack is quite good and makes up for it
easy to get drawn into discourse over whether it's (continued) pretraining or RL that really matters, when they actually compound!
that's why we're investing so heavily in continued pretraining - it acts as a multiplier on our work in RL
@HarveenChadha evaluating models' suitability as bases is a pretty tricky task, and we're still figuring out the story! e.g. you want metrics that are cheap-ish to compute, but predictive of performance after all the interventions we apply. ofc, considerations beyond benchmarks apply too
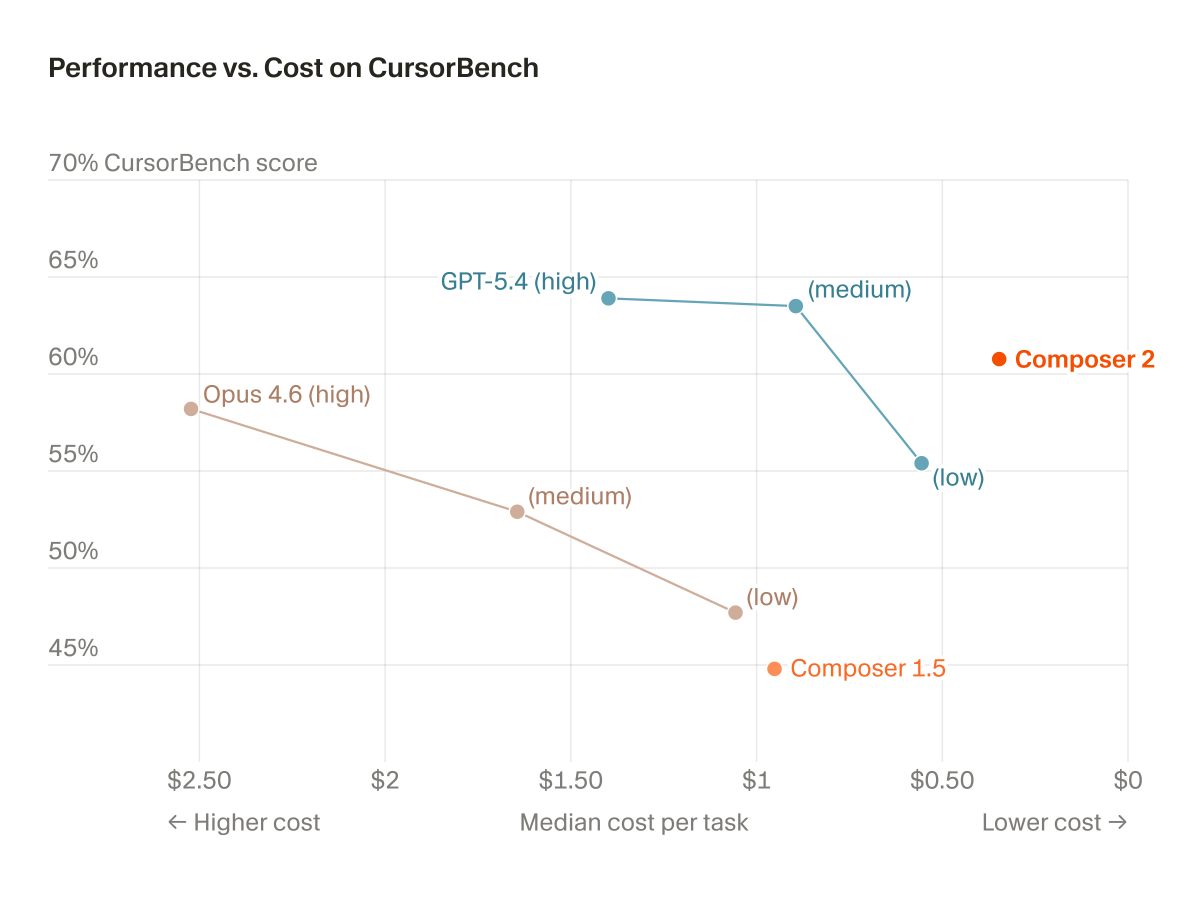
Composer 2 is out!
Cursor is an example of a new type of company, not a pure app maker and not a model provider.
Our aim is to build the most useful coding agents by combining the best API models and our domain-specific models.
3 years ago we could showcase AI's frontier w. a unicorn drawing. Today we do so w. AI outputs touching the scientific frontier: https://t.co/ALJvCFsaie
Use the doc to judge for yourself the status of AI-aided science acceleration, and hopefully be inspired by a couple examples!
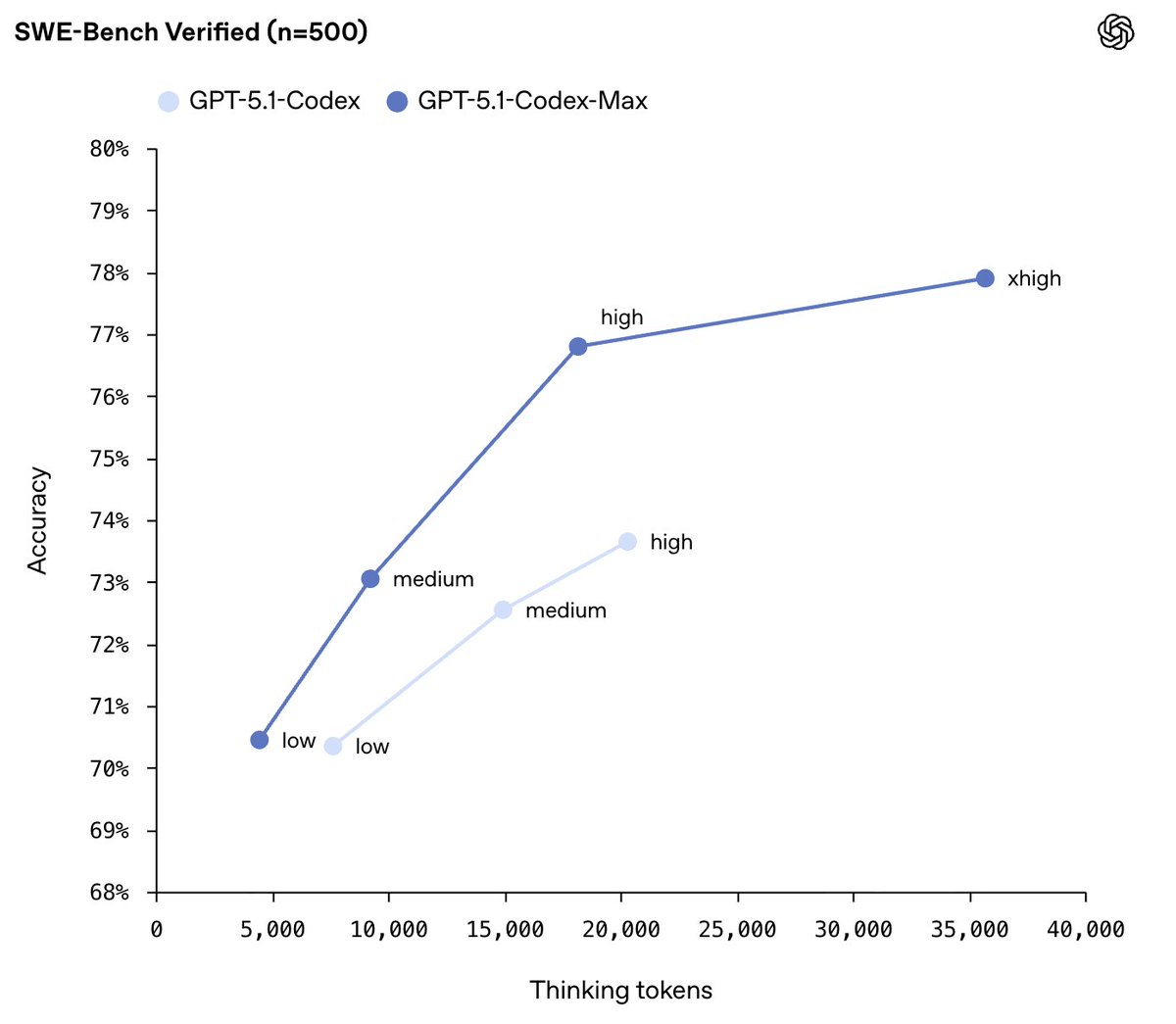
Today we at @OpenAI are releasing GPT-5.1-Codex-Max, which can work autonomously for more than a day over millions of tokens. Pretraining hasn't hit a wall, and neither has test-time compute.
Congrats to my teammates @kevinleestone & @mikegmalek for helping to make it possible!
GPT-5 is proof that synthetic data just keeps working! And that OpenAI has the best synthetic data team in the world 👁️
@SebastienBubeck the team has our eyeballs on you! 🙌
GPT-5 is what you’ve been waiting for – it defines and extends the cost-intelligence frontier across model sizes today.
it’s been a long journey, and we’ve landed pivotal improvements across many axes in the whole GPT-5 family.
and hey no more model picker (by default)!
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
The race for LLM "cognitive core" - a few billion param model that maximally sacrifices encyclopedic knowledge for capability. It lives always-on and by default on every computer as the kernel of LLM personal computing.
Its features are slowly crystalizing:
- Natively multimodal text/vision/audio at both input and output.
- Matryoshka-style architecture allowing a dial of capability up and down at test time.
- Reasoning, also with a dial. (system 2)
- Aggressively tool-using.
- On-device finetuning LoRA slots for test-time training, personalization and customization.
- Delegates and double checks just the right parts with the oracles in the cloud if internet is available.
It doesn't know that William the Conqueror's reign ended in September 9 1087, but it vaguely recognizes the name and can look up the date. It can't recite the SHA-256 of empty string as e3b0c442..., but it can calculate it quickly should you really want it.
What LLM personal computing lacks in broad world knowledge and top tier problem-solving capability it will make up in super low interaction latency (especially as multimodal matures), direct / private access to data and state, offline continuity, sovereignty ("not your weights not your brain"). i.e. many of the same reasons we like, use and buy personal computers instead of having thin clients access a cloud via remote desktop or so.
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
On top of context engineering itself, an LLM app has to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability
- handle generation-verification UIUX flows
- a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.