Instead of watching an hour of Netflix, watch this 30-minute speech by the Head of Anthropic’s Coding Agents research team. It will teach you more about vibe coding than 100 paid courses.
You can read a detailed technical report on the software vulnerabilities and exploits discovered by Claude Mythos Preview here: https://t.co/AgU6ltV2qW
Today we're releasing Gemma 4, our new family of open foundation models, built on the same research and technology as our Gemini 3 series. These models set a new standard for open intelligence, offering SOTA reasoning capabilities from edge-scale (2B and 4B w/ vision/audio) up to a 26B parameter MoE model and a 31B dense model. By releasing Gemma 4 under the Apache 2.0 license, we hope to enable more innovation across the research and developer communities. Our earlier Gemma 3 models were downloaded 400M times and over 100,000 variants of those models have been published, so we're excited to see what the community will do with the even better Gemma 4 models!
Learn more at https://t.co/BW6O3Gr8bc and https://t.co/8M0XSQSP4u
Great work by everyone involved!
#Gemma4 #AI #OpenSource #ML
DLSS 5 is completely mind blowing. The neural rendering model with photoreal lighting and materials is a generation step up in visual fidelity. Gaming with DLSS 5 feels like future tech, but its possible now. It is truly incredible. 🤯
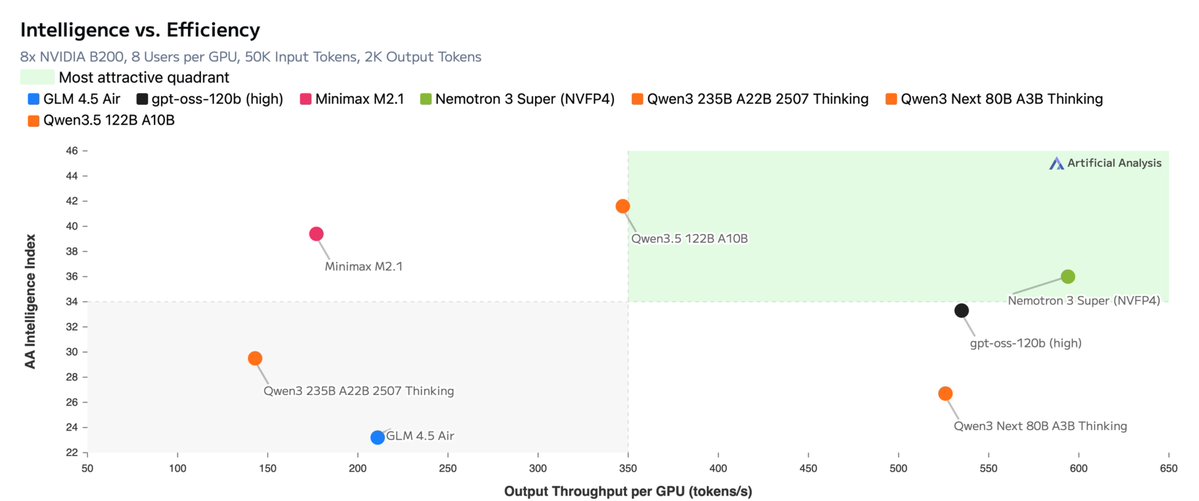
Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell
💚36 on AAIndex v4
💚up to 2.2X faster than GPT-OSS-120B in FP4
💚Open data, open recipe, open weights
Models, Tech report, etc. here:
https://t.co/CAYpP1iK3i
And yes, Ultra is coming!
The age of autonomous mobility at scale is here. Waymo has raised $16B to bring the world’s most trusted driver to more cities.
✅ $126B valuation
✅ 20M+ lifetime rides
✅ 90% reduction in serious injury crashes
Read more from our co-CEOs: https://t.co/Fc5I33WpYB
"how can flash beat pro??" -> the answer is RL!
flash is not just a distilled pro. we've had lots of exciting research progress on agentic RL which made its way into flash but was too late for pro.
can't wait to finally bring them to pro👀
One under-appreciated (so far) aspect of Hybrid-MoE architecture such as in Nemotron 3, is that it is a better fit for reasoning. Its throughput advantage over “plain” transformer grows with batch size and generation length. Which is what happens in reasoning RL loops.
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
Generalist robots need a generalist evaluator. But how do you test safety without breaking things? 💥
🌎 Introducing our new work from @GoogleDeepMind:
Evaluating Gemini Robotics Policies in a Veo World Simulator
https://t.co/ZjvpYXFddZ
🧵👇
Some people may be disappointed that we won the @arcprize competition with a LLM (QWEN 4B) and not with a more reasoning oriented or code oriented method. I'd answer this:
@kaggle compute limits forces us to focus on efficiency. We tried reasoning models but they were too slow. Same for code generation at test time.
We had to move the heavy lifting (generative LLM for puzzle understanding + code gen) to pretraining. We used heavy models there: Claude and GPT OSS 120B.
We still used some fancy scaffolding at test time, including the ARChitects decoding and TRM. But no reasoning nor code generation.
If we relax the Kaggle compute limits then we can, and maybe should, use both reasoning and code generation at test time. But this comes at two orders of magnitude more cost.
Announcing the ARC Prize 2025 Top Score & Paper Award winners
The Grand Prize remains unclaimed
Our analysis on AGI progress marking 2025 the year of the refinement loop
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
"Seed Diffusion Preview achieves an inference speed of 2,146 token/s over H20 GPUs while maintaining competitive performance across a sweep of standard code evaluation benchmarks, significantly faster than contemporary Mercury and Gemini Diffusion, establishing new state of the art on the speed-quality Pareto frontier for code models."
We released two open-weight reasoning models—gpt-oss-120b and gpt-oss-20b—under an Apache 2.0 license.
Developed with open-source community feedback, these models deliver meaningful advancements in both reasoning capabilities & safety.
https://t.co/PdKHqDqCPf
Official results are in - Gemini achieved gold-medal level in the International Mathematical Olympiad! 🏆 An advanced version was able to solve 5 out of 6 problems. Incredible progress - huge congrats to @lmthang and the team! https://t.co/pp9bXF7rVj