Technical Governance Researcher at the Machine Intelligence Research Institute. Formerly game designer including TFT, LoR, and LoL. Views expressed are my own.
This is a needed and candid post by the Anthropic Institute. I agree with the conclusion that we need more time before we are hit with the “immense implications” of AI technology. My team at the Machine Intelligence Research Institute has worked to detail an international agreement (https://t.co/TiUxXfEPVf) which satisfies the requirements which are laid out by Anthropic: that a pause must include all frontier AI developers anywhere on Earth and must be mutually verified. Our contribution includes answering how to address the technological particulars of verifying a frontier AI development pause, and how to structure the agreement for stability and effectiveness.
Our work is a model, and we would welcome collaboration with Anthropic to further develop and refine it.
Some important points for enabling international coordination:
- We task governments, rather than labs, to coordinate and verify the pause, because they have the diplomatic and national intelligence means to do so and they can architect binding rules that apply to everyone.
- The United States is capable of halting frontier AI development globally, unilaterally and/or through coordination with key allies. While this is not preferred to a broadly coordinated halt, it strengthens the US’s hand in negotiating one.
Not the line of questioning I was expecting in a hearing about Chinese IP theft, but I'm glad senators are starting to really get why "we must beat China!" is really nowhere near a complete plan for how to make sure AI goes well.
---
Transcript:
HAWLEY: Ms. Toner, can I just come back to something that I think you said in response to Senator Durbin. You said to him that, regarding American AI companies, you said that it is hard to believe but nevertheless true that American AI companies are working as hard and as fast as they can to try to develop technology that will displace many millions of workers and potentially pose existential risks. Now that's my gloss, maybe you wanna correct the record exactly as you said it before. I thought that was very interesting and very important. Could you just reiterate that for us?
TONER: Yes. AI is a very fast-moving field, and I think it is important that as we think about what AI's implications are for our society, for our civilization, we don't merely look at the AI systems that we have today—chatbots, starting to be agents that can help a little bit with some professional tasks—but instead we take seriously the goals of the companies that are building these systems.
Over the past 10 or 20 years, it's gone from a very abstract idea that we might build AI that can outperform humans at any intellectual task, to a pretty concrete idea that some of the most well-capitalized companies in the history of the planet are driving towards as fast as they can. They may fail! It may turn out to be harder than they think to build systems that are that capable. Personally, I'm skeptical of some of the extremely short timelines that they name, saying we might have these superintelligent AI systems within, you know, one to three years. But it seems so clear that there's a real possibility that they build these systems within three years, 10 years. If they build it within 10 years, that's when my daughter is entering high school. That's not very long. That is an extremely radical thing to be trying to do, to build computer systems that can outperform humans, that may escape the control of humans, and the companies are telling us they're doing it, and I think we don't take them seriously, and we should.
HAWLEY: These same companies often say, and often in front of this committee and to this body, that it's absolutely vital that they succeed at whatever it is they're doing on that particular day, in order so that we can beat China. You know, they're our great American national champions and we have to beat China. My concern is based on what you've just testified to and what I've heard others testify to, it sounds an awful lot like the goals that they have in mind, that these companies, these CEOs have in mind, are every bit as nefarious. In fact, if these same goals were held by a foreign adversary, we would say this is an incredible threat to our national security, we'd never allow a foreign corporation to try and pursue such plans at the expense of American workers, at the expense of American families, and yet these companies, our own companies so to speak, are doing it. Let me just ask it this way: Will it do us any good if these American AI companies are able to pursue their designs without any hindrance? Will it do any good that we beat China if in fact they succeed in displacing millions of American workers, gobbling up all of Americans' data, completely destroying our IP system, etc.?
TONER: I think the way I've heard this put best is: Right now, the way that we build AI and the level of control we have over it, which is not great, the winner of any AI race between the US and China is the AI. And I think we need to be working to make sure that is not the case. I think it is very important that the US AI sector remains ahead of the Chinese AI sector, but if that's at the expense of AI overrunning the entire planet, then that is, you know, that hasn't benefited us.
HAWLEY: Yeah, that sounds entirely sensible to me and I just have to say I don't really have any interest in winning an AI race in which the goal, the victory rather, the prize for success is to become like China. Is to become a surveillance state. Is to become a place where there is no private property any longer, where nothing is personal, nothing can be protected, nothing can be owned by any individual. Why in the world would we want that in the United States of America? I mean, if the prize is to destroy everything that makes us Americans, why would we compete in that game? It seems very dangerous to me. Let me ask you something else about competition with China though. You also testified to Senator Durbin that the best way, if I remember correctly, the best way to constrain China's ability to match us in AI development is to constrain the hardware to which they have access. That seems to be an important point to me, can you just elaborate?
TONER: Yes. I think there's different levers of what goes into having a competitive AI ecosystem, and many of them, talent, data, algorithmic ideas, are very difficult to control. We're very fortunate that we're in a situation where the most advanced hardware is produced by American companies, is designed by American companies. And I think we, if you look at the, China is growing their capacities here, but they're not growing them nearly fast enough to meet their own domestic demand, nor are the US companies to be clear. So we can control chips to China and not forgo any profits, not forgo any revenue because the demand for those chips is so great.
I'll also call your attention to semiconductor manufacturing equipment, what goes in the fabrication facilities. I think it's even more strategically clear that we should not be allowing China access to advanced tools. That is something that has gotten lip service from the past three administrations but enforcement has been very weak. And I think ensuring that the most advanced lithography tools, the most advanced design software, other aspects of the semiconductor supply chain are not being exported to China to let them build their own indigenous supply chain is also one of the simplest and most important levers we have available.
HAWLEY: Let me just conclude by saying that I think it is absolutely vital that we bend this technology, this AI technology which is upon us whether we like it or not, that we bend it to the good of the American worker and the American family. And I am firmly of the view that this is not just going to happen magically. That if we just stand back and just wait to see what will happen, it's not going to be good for American workers, it's not going to be good for American families. We've got to make a choice as a society to make it so. And this is the time to make that choice right now.
https://t.co/xnuVcYwCNg
I hate to say it but an international agreement between the US and China to ban superintelligence is inevitable.
Leaders in these countries are just going to follow their incentives, and none of them are willing to give up control to an artificial superintelligence.
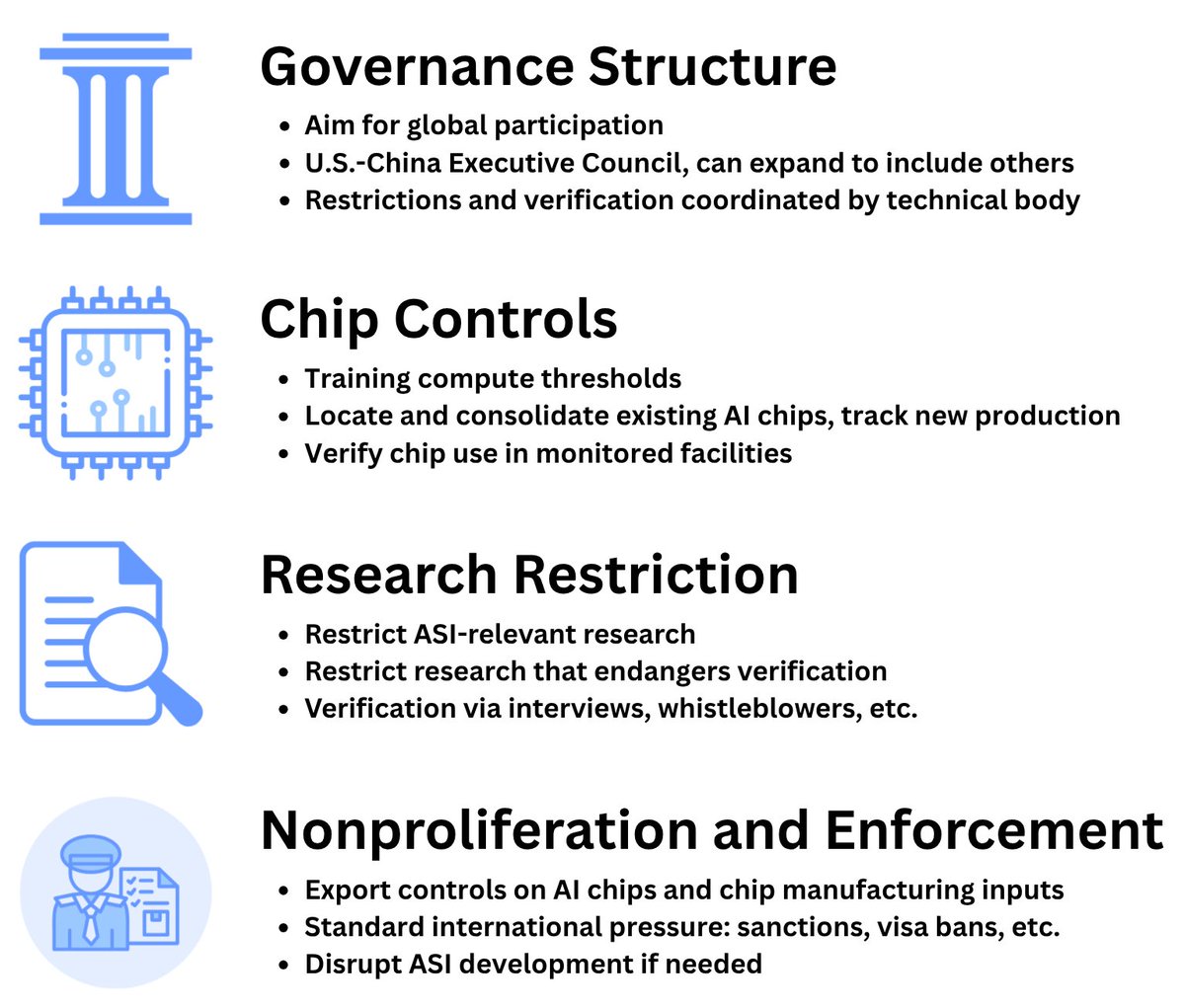
1. Our agreement permits inference, broadly, to continue. It only limits AI training above 10^24 FLOP. In Article VIII, we establish that the agreement restricts only research that advances toward ASI or undermines verification. We permit medical diagnostics and drug discovery, for example, among other non-general capabilities. As long as the research focuses on a narrow domain (like materials science or climate modeling) and does not increase "general cognitive capabilities," it is not subject to restrictions.
There is no seizing of assets, but rather mandatory monitoring which can involve forced consolidation of compute into monitored datacenters by the signatory government domestically. (No international centralization of AI monitoring!) So, for example, a small university lab’s research compute would be relocated to a monitored datacenter but is still owned and (remotely) operated by that lab.
2. We architected our agreement to specifically not ban the additional production and installation of compute. The value of such for inference and real-world economic activity is only increasing. So the total economic impact on parts of the AI supply chain are probably far less than existential. We note that many of the relevant players have multi-year backlogs to clear at full production capacity, and building out the infrastructure for model development is only a part of that.
3. Nothing happens to consumer AI apps. If anything additional resources are freed up which can accelerate adoption and integration of these tools.
4. Individual governments handle their own verification and monitoring, but some transparency, random inspections, etc. to either China or the US will be required. Our agreement opts for comprehensive domestic monitoring and shares the least information with rivals (directly) which establishes required confidence. There is no multilateral international AI inspection apparatus in our current version of the agreement, which is a change from the first version we published.
5. Robotics and other applications are unaffected to the extent that progress can continue without developing new models with runs that exceed the compute limit.
6. Our agreement does not attempt to set up a “binding” constraint, in that we do not consider the legal, reputational constraints on US/China to be the active ingredient which leads to stability of the treaty. Instead, we establish a clear understanding on both sides of what behavior is restricted and what consequences must follow otherwise, with enough transparency and non-interference with intelligence gathering to create confidence in each side that the other is adhering to the agreement.
Rather than legal constraints, I consider deterrence as the framework for thinking about the stability of the agreement. This is the historical method for constraining a major power, including the use of strategically significant assets. Nuclear deterrence prevented Soviet employment of its conventional superiority against Western Europe. A Soviet dead hand blocked what was otherwise the possibility of a perfect first strike (nuclear or otherwise). Stability emerges when both sides coordinate to make the consequences of aggression clear. Is that a “binding constraint” that one side “accepts”? No, not legally, textually. Not in the sense of “I staked my reputation and my honor in the arena of international relations”. Where agreements have a role to play is in helping to maintain the conditions for successful deterrence. An example of this is the anti-ballistic missile treaty, in which both sides limited their deployment of missile defenses so that deterrence could be maintained.
Speaking on behalf of MIRI TGT (not necessarily MIRI overall)
We share many of the same concerns, which is why we structured our model agreement (below) the way we did. It invites broad participation, but also features mechanisms to address states which insist on operating outside of the agreement, while prioritizing the national security requirements of the US and China. So to address question 5 upfront, “should [this] be a global agreement?”: Yes! We think the US and China would be a sufficient seed to get broad participation via their network of allies, superpower status, and AI dominance. Now going point by point:
“1. Assuming we achieve the desired policy goal through a bilateral US/China agreement, what would be the specific metric or objective we would say needs to be satisfied in advance? Who decides whether we have satisfied them? What if one party believes we have satisfied them but the other does not?”
There are two interpretations of this question. Interpretation (1): what metric is used to determine whether the desired policy goal is being achieved? Interpretation (2): what metric is used to determine when a halt is to terminate? I’ve tried to address both below:
The policy goal is to forestall the development of superintelligence long enough for other, better solutions to be realized. It is hard to say what these solutions will be in advance, as humanity is nowhere near being able to align a superintelligence. The field doesn’t have a clear path to solving that technical problem. Furthermore, solving alignment isn’t sufficient on its own, and the other thorny problems (such as concentration of power) require similar focused effort which we aren’t seeing on current timelines.
The key metric we use to know if that goal is accomplished is the confidence within the leadership of the US and China that no one is advancing the frontier of AI general intelligence capabilities anywhere. This confidence is reflected by the continued willingness of these actors to participate in the agreement, and springs from a combination of restrictions/controls, transparency, verification, and intelligence gathering. It would be great if we can attain this confidence without much constraint on the beneficial uses of AI we already see today, and our agreement aims to preserve these!
The agreement is not accomplishing its aims if only one of these key parties has such confidence. We have tried to accommodate the requirements we think that the USG and CCP would have, but also expect that many details would need to be ironed out through an actual negotiation and implementation effort.
“2. If the goal is achieved through a bilateral US/China agreement, would we need capital controls to ensure that U.S. investors cannot fund semiconductor fabs, data centers, or AI research labs in countries other than the U.S. and China?”
Yes, just like how the U.S. makes it hard for you to fund terrorists or give money to the North Korean military.
“3. Would we need to revoke the passports of U.S.-based AI researchers and semiconductor engineers to prevent them leaving America to join AI-related ventures elsewhere? How else would the U.S. and China keep researchers within their borders?”
There will be no shortage of technical work for talented researchers under our proposed agreement, and the best approach is for states to modify their incentives (i.e. pay them well) to act in our collective interest, in the style of efforts like the International Science and Technology Center. In 1994, the ISTC kept former Soviet nuclear researchers employed in peaceful work so that they wouldn’t sell their expertise to proliferators.
We anticipate that some researchers will emigrate to non-signatories and pursue covert work, in spite of any efforts. The agreement aims to provide the US and China with sufficient confidence that these efforts will fail through a combination of compute denial, detection, and enforcement.
The framing of this question seems to imply that some agreements may only aim to address AI development within the US and China, and that such development must not leave those jurisdictions. We agree that is not viable. We cover this in Article XII.
“4. How should we grapple with the fact that (2) and (3) are common features of autocratic regimes? “
It doesn’t look like it takes qualitatively different “autocracy” than was required to prevent the proliferation of nuclear weapons. Limiting the development and deployment of extraordinarily dangerous technology is a feature of our American system of government which prioritizes the defense of individual life, freedom, and property. Preventing you from refining uranium in your basement and assembling a nuke in your garage is an impingement upon your freedom, but that doesn’t mean society should let you do it, and it doesn’t mean the government needs to become an autocracy to prevent it. So too with superintelligence.
We charge our military and Intelligence Community with ensuring the safety and freedom of Americans against all threats. Through careful institutional design and adherence to our constitution we can avoid abuse of the power granted by our agreement. As an aside, we believe that the potential for abuse of our agreement is less than the potential for abuse of AI systems developed and employed by the government without constraint, or the potential for abuse in arrangements where the government is allowed to gatekeep access to powerful AI.
Read More: An International Agreement to Prevent the Premature Creation of Artificial Superintelligence https://t.co/IZ9Rhr898M
Every AI lab is working to make their AI helpful, harmless and honest.
Max Harms (@raelifin) thinks this is a complete wrong turn, and 'aligning' AI to human values is actively dangerous.
In his view a safe AGI must have absolutely no opinion about how the world ought to be, be willingly modifiable, and be entirely indifferent to being shut down. The opposite of all commercial models today.
The key appeal is that so-called 'corrigibility' could be an attractor state – get close enough and the AI actively helps you make it more corrigible over time. That forgiveness would at least give us a shot.
It's a strategy that feels natural within the 'MIRI worldview', recently laid out by his colleagues @ESYudkowsky and @So8res in 'If Anyone Builds It Everyone Dies'.
But it risks causing a different AI catastrophe, because the resulting AI model would necessarily be willing to assist any human operator with a power grab, or indeed any crime at all.
I interviewed Max on the 80,000 Hours Podcast to debate the MIRI worldview, and what we should do to figure out if corrigibility ought to be our one and only focus. Links below – enjoy!
00:01:56 If anyone builds it, will everyone die? The MIRI perspective on AGI risk
00:24:28 Evolution failed to ‘align’ us, just as we'll fail to align AI
00:42:56 We're training AIs to want to stay alive and value power for its own sake
00:52:24 Objections: Is the 'squiggle/paperclip problem' really real?
01:05:02 Can we get empirical evidence re: 'alignment by default'?
01:10:17 Why do few AI researchers share Max's perspective?
01:18:34 We're training AI to pursue goals relentlessly — and superintelligence will too
01:24:51 The case for a radical slowdown
01:27:53 Max's best hope: corrigibility as stepping stone to alignment
01:32:34 Corrigibility is both uniquely valuable, and practical, to train
01:45:06 What training could ever make models corrigible enough?
01:51:38 Corrigibility is also terribly risky due to misuse risk
01:58:57 A single researcher could make a corrigibility benchmark. Nobody has.
02:12:20 Red Heart & why Max writes hard science fiction
02:34:08 Should you homeschool? Depends how weird your kids are.
A tale of two warning shots, #1: COVID happened. Scientists are divided on whether it was a lab leak. The world did not rally against dangerous viral research in labs. The warning shot was squandered.
@AivokeArt@robbensinger and this could turn to hostility. The CCP is more interested in regulation and diffusion than pushing frontier capabilities. So against that we're going to say this inevitable and its out of our hands?
@AivokeArt@robbensinger solar-powered compute. He describes Starship as the most complex machine, which "really wants to explode".
The point being that technically, this is a house of cards that just wants to be knocked over. Politically, there is widespread popular skepticism about the impacts of AI,
Reminder: Donations to MIRI before Jan 1 are high-leverage. We’ve got ~$1.6M in 1:1 matching from SFF, over half of which has yet to be claimed!
This is real counterfactual matching: whatever doesn’t get matched by the end of Dec 31, we don’t get. 🧵
https://t.co/zhe2YRBxZb
My new memo reformulates @hendrycks' Superintelligence Strategy argument as three main premises:
1. China will expect to be disempowered if the US develops ASI unilaterally
2. China will launch cyber/kinetic strikes to prevent this.
3. The US will concede, rather than risk war.
We at the MIRI Technical Governance Team just put out a report describing an example international agreement to prevent the creation of superintelligence. 🧵