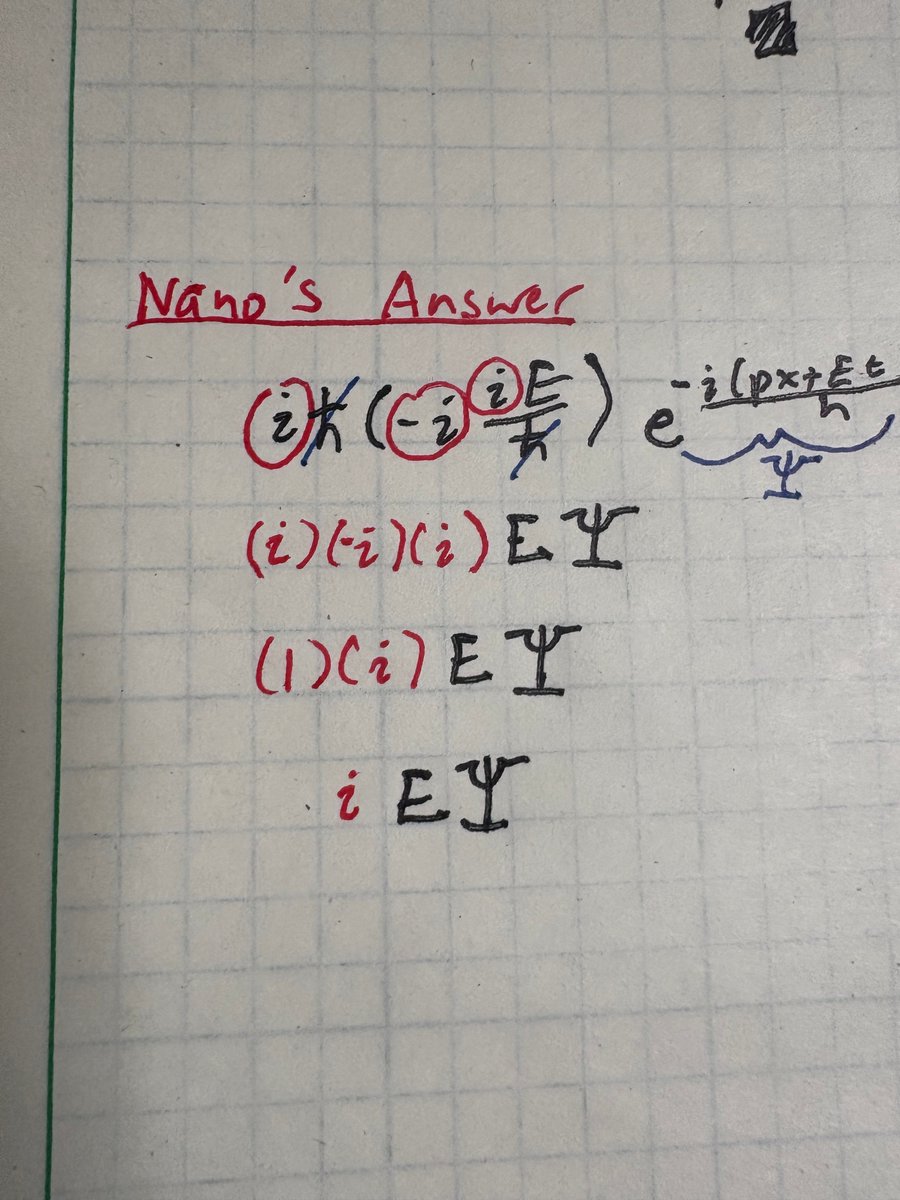Now I wish it was "mass surveillance" rather than "mass *domestic* surveillance" but it's clear that @AnthropicAI is aligning to /their/ *moralities* while @OpenAI is aligning to *legality*. These are not the same and the latter is blatantly a lower guardrail.
It's insulting
This is a farce. To claim "more guardrails" is frankly unbelievable. Why would @AnthropicAI be called a supply chain risk but then @OpenAI gets a contract with stricter conditions.
If guidelines are stricter then what's the claim? DOD killing your competition for you?
Yesterday we reached an agreement with the Department of War for deploying advanced AI systems in classified environments, which we requested they make available to all AI companies.
We think our deployment has more guardrails than any previous agreement for classified AI deployments, including Anthropic's. Here's why: https://t.co/k1Ge2MqqPr
But we can just read both their statements. Compare these two.
@AnthropicAI: no domestic mass surveillance, even if it's legal
@OpenAI: as long as it's legal ¯\_(ツ)_/¯
That's the big difference.
https://t.co/TcFnxVBDYn
https://t.co/PgNmAXHar0
@diyerxx@sarahookr Errors like these don't invalidate the utility of benchmarks but they do limit how useful they are to evaluation.
My point is, you can't evaluate simply by looking at the numerical result. Analysis is the hard part, not the easy part
@diyerxx@sarahookr You can also explore more yourself, here's another obvious example. But there's even problems with some classes. Label 836 is "sunglass" and 837 is "sunglasses".
https://t.co/xyhHfRy6iF
well someone has been preaching this at us for like 6+ years
glad we are past the 'feel the agi' phase and back to building toward human-level intelligence
Btw, there are more mistakes. Can you find them?
There's some more obvious ones (at least one "physically impossible" one) and a few that are far more subtle.
Regardless, Nano Banana is very impressive. Mistakes like these are hard to catch, so keep an attentive eye out.
Very impressive, but also wrong.
There's 2 mistakes in the first physics problem on the LHS.
It did the derivative wrong, but fixed its mistake with another mistake! (better explanation in alt text)
ChatGPT looked at the end, not the answer.
Gemini Nano Banana Pro can solve exam questions *in* the exam page image. With doodles, diagrams, all that.
ChatGPT thinks these solutions are all correct except Se_2P_2 should be "diselenium diphosphide" and a spelling mistake (should be "thiocyanic acid" not "thoicyanic")
:O
It is also a good example of why researchers are arguing about "understanding".
Does it understand?
- It got the right answer, so it must!
- The steps were wrong, so it actually doesn't!
Or maybe something more complex is going on...
We still don't know
@simonw@mitchellh@doodlestein That's absolutely mindboggling. I mean I can `vimdiff` or `git diff` thousands of lines on a machine with outdated hardware without breaking a sweat.
Something went terribly wrong and these "solutions" look like patches kicking a can down the road. Talk about tech debt...
@doodlestein@jwkicklighter@mitchellh The problem here that @jwkicklighter is pointing out is that this doesn't just "get work done." This type of solution adds more complexity and this gets compounded upon again and again.
Your attempts to make things simple have only increased complexity, not decreased ir.
@keenanisalive Sure, you can make accurate predictions without causal models or consistency but those will always be brittle and can't generalize. I just don't see how it can generalize without causality and consistency.
@keenanisalive What does "accurate physics" mean? Which physics?
I feel "world model" often gets used in a weird way as if there is only one world and one physics. I think building causal relationships and consistency seems more important than which world is actually being modeled.