⭐ VibeThinker-3B is released — a dense 3B model for frontier-level verifiable reasoning.
🚀 Reasoning: 94.3 on AIME’26, 76.4 on IMO-AnsBench, and 80.2 Pass@1 on LCB v6; with CLR, AIME‘26 improves to 97.1 and IMO-AnsBench to 80.6.
💻 OOD Coding: On recent unseen LeetCode weekly contests, VibeThinker-3B passes 123/128 (96.1%) first-attempt Python submissions.
⚡ Efficiency: Only 3B parameters, yet reaching the performance range of much larger top-tier reasoning models.
🧠 Perspective: Small models are not just cheaper substitutes. In parameter-dense domains with clear verification signals, SLMs offer a path to frontier-level reasoning that complements traditional Scaling Law.
Model : https://t.co/94A14zpqCV
Github: https://t.co/32so5P6C7L
Paper: https://t.co/UDd264RsZb
#AI #LLM #Reasoning #OpenSource #SmallModel
@MaziyarPanahi Thanks for the shout-out! It's great to see your work on quantizing and running VibeThinker-1.5B so smoothly on device. Massive respect!
VibeThinker-1.5B hit #1 on @huggingface ’s trending models today! 🔥
Huge thank you to our amazing community for the love, downloads, and priceless feedback.❤️
@MaziyarPanahi@lmstudio Thanks for the support and all the recommendations! Glad we could help.
We’ll keep improving and would love to hear your thoughts anytime — together we go further!
I strongly agree with your perspective.
We recently open-sourced a 1.5B small model, which performs well on competition-level math and code problems. On benchmarks like AIME and HMMT, it even surpasses deepseekr1-0120, and its cost is less than $8,000.
We are looking forward to your thoughts on this model.
https://t.co/gXedxAgukO
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel
@gm8xx8 Curious to get your thoughts on our new 1.5B model, VibeThinker.
We're seeing it challenge scaling laws: it outperforms a 671B model on AIME math, and was trained for only $7.8k using our "Spectrum-to-Signal Principle."
It's open-source, details below:
https://t.co/gXedxAgukO
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel
@rasbt@rasbt
Agree, Kimi K2 thinking is a massive leap for open weights! 🔥
But what if I told you a 1.5B model can beat a 671B giant on Olympiad-level problems like AIME and HMMT?
We just open-sourced VibeThinker-1.5B, details below:
https://t.co/HLO4Uef9JF
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel
@reach_vb Curious to get your thoughts on our new 1.5B model, VibeThinker.
We're seeing it challenge scaling laws: it outperforms a 671B model on AIME math, and was trained for only $7.8k using our "Spectrum-to-Signal Principle." It's open-source, details below: https://t.co/gXedxAgukO
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel
@_akhaliq Curious to get your thoughts on our new 1.5B model, VibeThinker.
We're seeing it challenge scaling laws: it outperforms a 671B model on AIME math, and was trained for only $7.8k using our "Spectrum-to-Signal Principle."
It's open-source, details below:
https://t.co/gXedxAgukO
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel
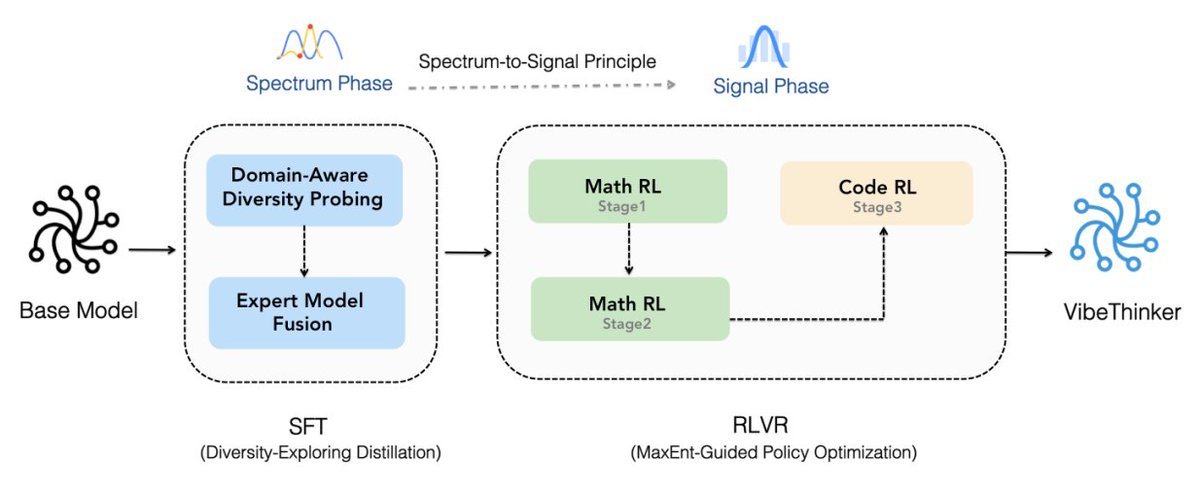
1st, we encourage it to explore manypossible answers (Spectrum Phase). Then, we teach it to identify & amplify the bestones (Signal Phase)
This "explore then focus" method is key to its strong reasoning.
⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
Model : https://t.co/G2aSB9MInX
Github: https://t.co/32so5P64id
Arxiv : https://t.co/GsN3ya0QX9
#AI #LLM #Reasoning #OpenSource #SmallModel