Providing evidence contrary to deeply held beliefs doesn’t always work. When beliefs are entrenched in one’s sense of self, logical claims can backfire. This can lead to a communication breakdown, especially when the logic runs counter to identity-oriented language, since we’re primed to react to perceived threats to our social groups [1]. 1/6
@bendee983 Really refreshing take in a sea of relative AI-psychosis. Been thinking about how to keep humans more effectively in the loop without creating bottlenecks, especially when scaling to large enterprises. Requires reimagining org. design to center transparency and provenance imo
Context alone will not solve the fundamental problems of LLMs. No matter how much context engineering you do, there will still be hallucinations, misinterpretations of instructions, prompt injections and jailbreaks, and toll-call mistakes (e.g., deleting your files or emails).
The true solution is to build the right system and scaffolding to make sure the AI works properly.
- Always build with the assumption that what can go wrong will go wrong.
- Set hard rules on tool calls as opposed to recommendations in the prompt.
- Evaluate the sensitivity of each step of an automated workflow. If there is a slight chance that an LLM hallucination error will result in a disaster, put a human in the loop.
AI can be a multiplier when you acknowledge and embrace its limitations. It will be a nightmare when you hope it works well every time.
"I get rebounds that break teams."
This mic'd up moment between Josh Hart and Mitchell Robinson in 2023 😂
Hart finished with 15 REB in under 30 minutes in Game 1 of the 2026 NBA Finals!
They're not lying. With AI coding agents, they can not only 100x but 1000x their output, which is 1 year's worth of code in 0.365 days.
However, 1000x output doesn't mean 1000x productivity. When you defer this amount of your work to the agents, you lose all semblance of control. You are at the mercy of whatever the LLM thinks is useful. There is no way you can fully understand what the AI is doing.
Very interesting; time is a useful but imperfect metric. How is quality being measured? Are we comparing to prorated salaries? Feels like an incomplete step in the right direction.
We built a system to estimate whether an agent’s output was actually productive, and if so, how long a human engineer would have taken to do the same work. Validated on real engineers’ time estimates working in enterprise codebases.
Read the blog from @ScottWu46: https://t.co/x2OiKI01cv
“It’s like hiring Tom Cruise, finding out he charges by the stunt, and you don’t know if you’re making Jerry Maguire or Mission: Impossible” is a hilarious analogy for companies blowing their AI tokens.
Right direction imo; the real problem isn’t model quality, it’s organizational design and transparency. With the right oversight, provenance, and replicability systems OS models should be more than able to handle law firm workflows
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
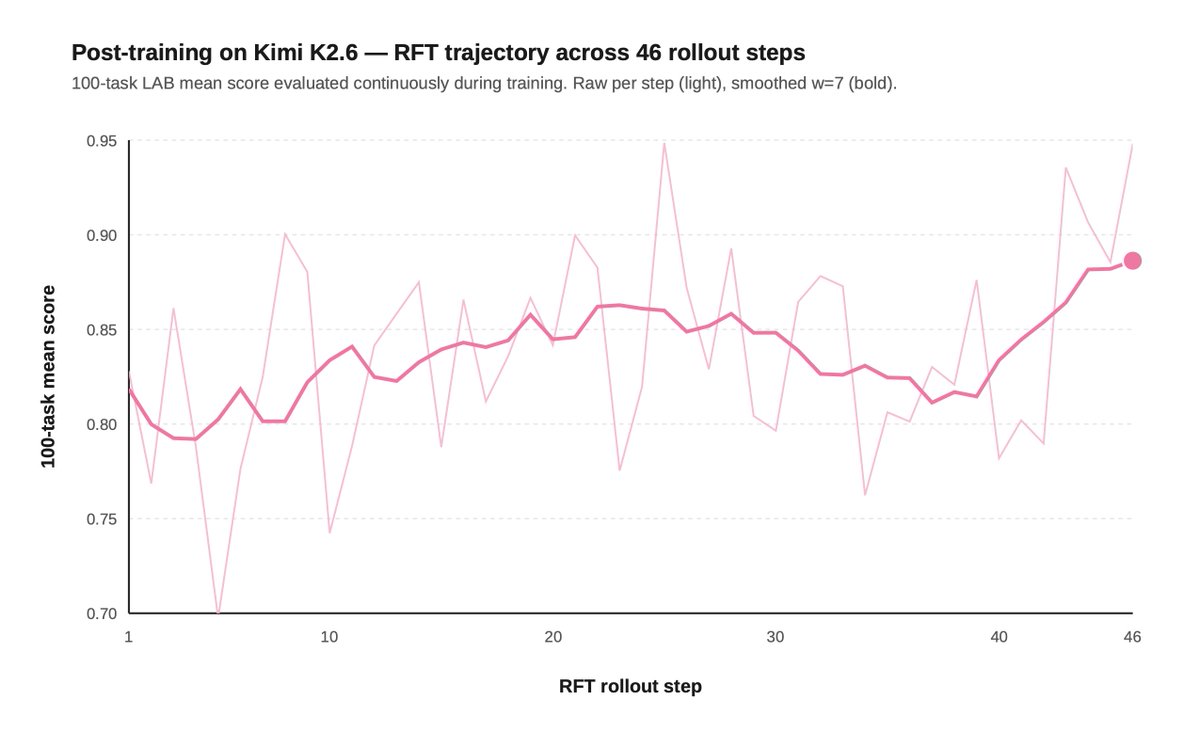
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.