This is one of the one the best (if not the best) approach to AI evaluation I've seen. You can't blabla your way to the predictive power they report in section 3.4!
ADeLe, a new evaluation method, explains what AI systems are good at—and where they’re likely to fail. By breaking tasks into ability-based requirements, it has the potential to provide a clearer way to evaluate and predict AI model performance: https://t.co/zPt8DxSLdT
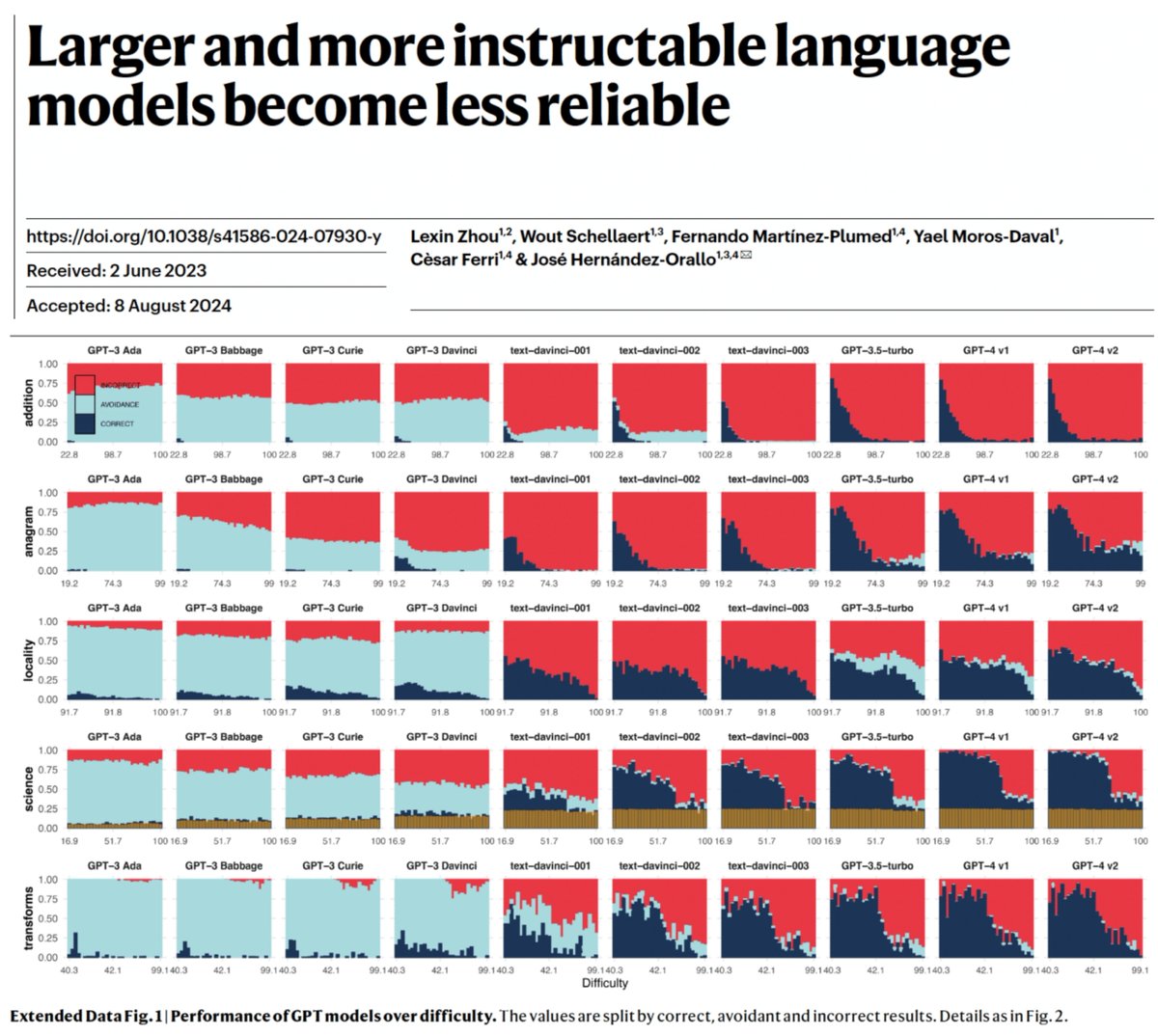
1/ New paper @Nature!
Discrepancy between human expectations of task difficulty and LLM errors harms reliability. In 2022, Ilya Sutskever @ilyasut predicted: "perhaps over time that discrepancy will diminish" (https://t.co/HADDUztzhu, min 61-64).
We show this is *not* the case!
1/ New paper @Nature!
Discrepancy between human expectations of task difficulty and LLM errors harms reliability. In 2022, Ilya Sutskever @ilyasut predicted: "perhaps over time that discrepancy will diminish" (https://t.co/HADDUztzhu, min 61-64).
We show this is *not* the case!
New and shiny AI systems have superseded the ones we reference (it took a while to publish), but our perspectives and suggestions for evaluating them have only become more relevant. Go have a read! 👽👽
New Article: "Your Prompt is My Command: On Assessing the Human-Centred Generality of Multimodal Models" by Schellaert, Martínez-Plumed, Vold, Burden, Casares, Loe, Reichart, Ó hÉigeartaigh, Korhonen and Hernández-Orallo https://t.co/LE7pWxdsON
Is it time to rethink how we perform system evaluations in AI? In our new @ScienceMagazine paper, we show that over-reliance on aggregate metrics and a lack of transparency in reporting threatens public understanding and hinders progress in the field. 1/8 https://t.co/kZMNCEALbG
@JohnJBurden While a stochastic parrot could be considered a world model, the logic of how to use it, e.g. in self-dialogue or planning, is conceptually external to the parrot, while as a human we seem to encapsulate the whole package.
Interested in AI robustness and predictability? Come join us in sunny Valencia for an exciting workshop on March 8th! Information here: https://t.co/5tkt5jqsMU
From https://t.co/7IIkp7TBOc, you can explore all the results. Drill down beyond aggregate statistics into individual predictions and exact prompts. It’s fully reproducible. Download it all, perform your own analyses, and let us know what you find!
We're starting an old school mailing list for folks interested in how to evaluate AI (and all questions that come with it).
Open for all to join and post! Come come!
https://t.co/WFv3eQZsDD
Still 10 full days to submit your papers for the 📐Evaluation Beyond Metrics workshop @IJCAIconf.
Not that you need another excuse to come, with @adinamwilliams and @AmandaMSeed giving a talk!
🔗 https://t.co/RRRSJvt1hR
@yanaiela @VictorButoi Probabilistic outputs are at the instance level, while your measures are typically aggregate. Instances and corresponding confidence differ.
📐Our Evaluation Beyond Metrics workshop at IJCAI got accepted... so prepare your cool papers!
💻https://t.co/RRRSJvt1hR
With @LucyCheke, @DanajaRutar, @JohnJBurden, @DrRyanBurnell, @TomerUllman and twitterless Josh Tenenbaum, José Hernández-Orallo and Fernando Martínez-Plumed
@rajiinio "If the so-called 'general' benchmarks were legitimate tests of progress towards general artificial cognitive abilities, we would expect the tasks they embody to be chosen systematically."
Great insight. Thanks!