Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: https://t.co/VH36cDIIz0
💻 GitHub: https://t.co/H3ewP99ydj
🤗 HF: https://t.co/BnLb7tcsRc
🧵👇
Next Monday (June 15), I’ll give a tutorial at AI4X 2026 Singapore, as part of the Agentic AI for Science tutorial.
My session: 10:30 AM–12:00 PM, Lecture Theater 29.
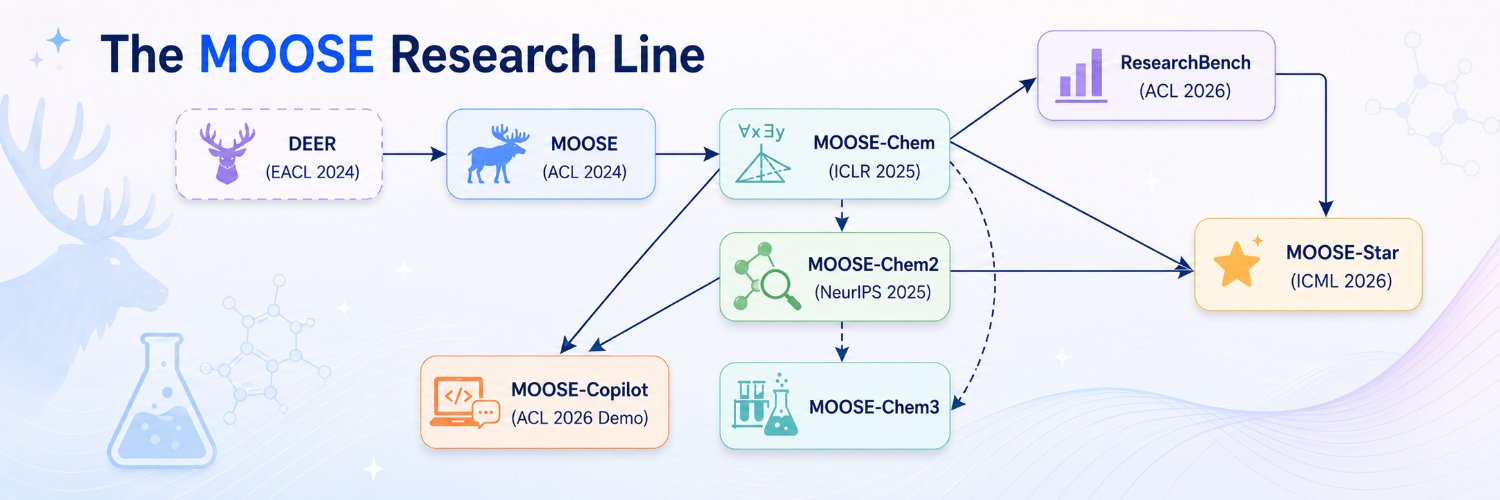
I’ll present the MOOSE research line, which asks:
How can LLMs help scientific discovery — with mathematical foundations, discovery harnesses, benchmarks, and scalable training recipes?
If you’re attending AI4X and interested in LLMs for scientific discovery / AI4Science, feel free to drop by!
The first post-training scaling laws for scientific discovery🫎 — performance on held-out, unseen research scales log-linearly with training data.
MOOSE-Star (ICML 2026): the first tractable and scalable training recipe for discipline-agnostic hypothesis discovery.
Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: https://t.co/VH36cDIIz0
💻 GitHub: https://t.co/H3ewP99ydj
🤗 HF: https://t.co/BnLb7tcsRc
🧵👇
MOOSE-Star (ICML 2026): the first scalable SFT recipe for discipline-agnostic scientific hypothesis discovery.🌟
We establish scaling laws for discovery training — and they confirm: the learned ability generalizes to unseen discoveries at test time.
Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: https://t.co/VH36cDIIz0
💻 GitHub: https://t.co/H3ewP99ydj
🤗 HF: https://t.co/BnLb7tcsRc
🧵👇
What if the very pretrained prior that lets an RL agent explore tools also destroys the format that made it tool-native?
We name this the Tool Prior Paradox — and tame it with PARA-GRPO.
🚀 Introducing ParaVT: parallel video tool use × agentic RL.
Thanks for the interest for MOOSE-Star!
This associative ability of LLMs has been analyzed by MOOSE-Chem (https://t.co/TvirgSjcVh), which I quote:
"We propose an assumption, grounded in preliminary experiments, that LLMs may already possess numerous knowledge pairs capable of being associated to create novel knowledge—even when scientists have not previously recognized any relationship between them."
This associate ability is exactly what MOOSE-Star built upon!
We post-train LLMs for math, for code, for instruction-following. Why not for scientific discovery?
🫎 MOOSE-Star (ICML 2026) : the first scalable SFT recipe for discipline-agnostic scientific hypothesis discovery. https://t.co/1THAJQ9pR5
By @Yang_zy223 & @LidongBing from MiroMind.
@BioAI_Pharma Thanks for sharing! The models and experiment results are fully available and reproducible!
GitHub: https://t.co/5Z29Q2RtMX
HuggingFace: https://t.co/dq7wkIUHKg
🔬 We post-train LLMs for math, for code, for instruction-following. Why not for scientific discovery?
No model has been post-trained specifically for hypothesis generation. MOOSE-Star is a first step, with scaling laws suggesting there's much more to unlock.
🚨 LLM-based scientific hypothesis discovery now has a scalable training recipe.
MOOSE-Star, accepted at ICML 2026, enables scalable training for hypothesis generation, with more scalable test-time scaling.
By our researchers—
https://t.co/17DnFbaefZ
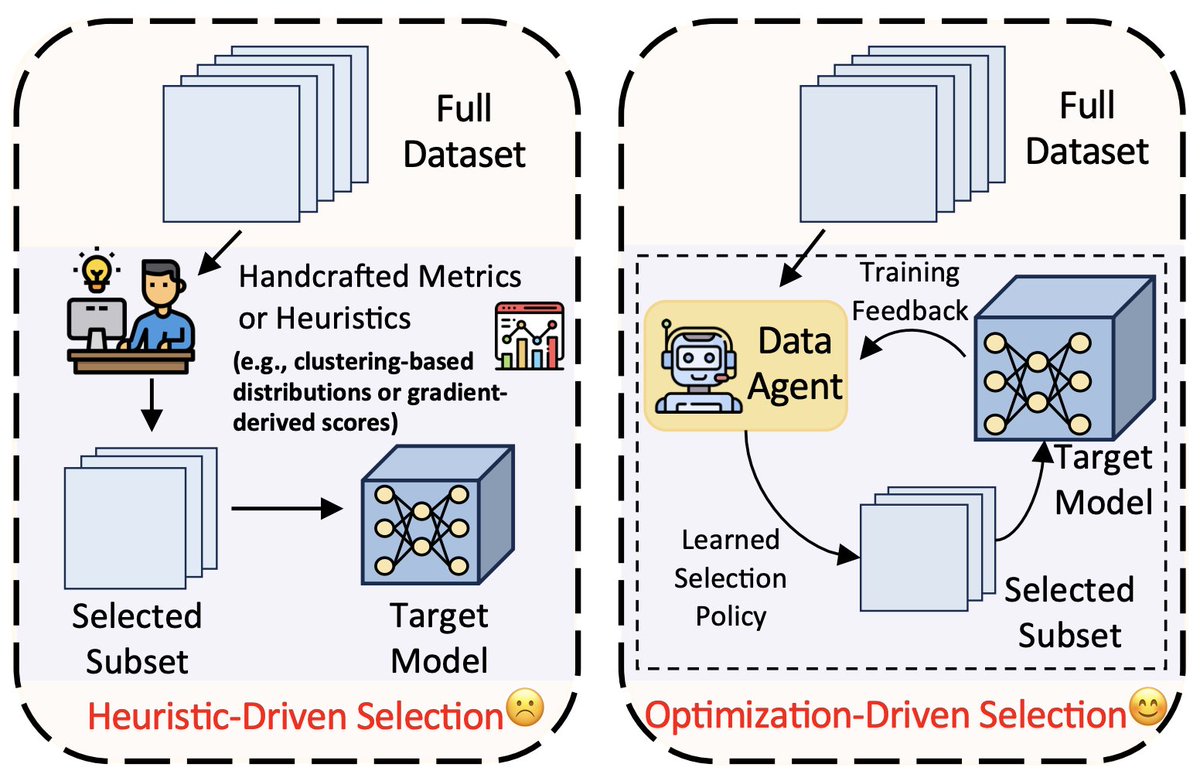
Excited to share that Data Agent has been accepted to #icml2026@icmlconf
🎉 Data Agent asks: Can a model learn which data it needs during training?
Highlights:
✅ Modular reward designs
✅ Very lightweight agent
✅ Plug-and-play across vision models and LLMs
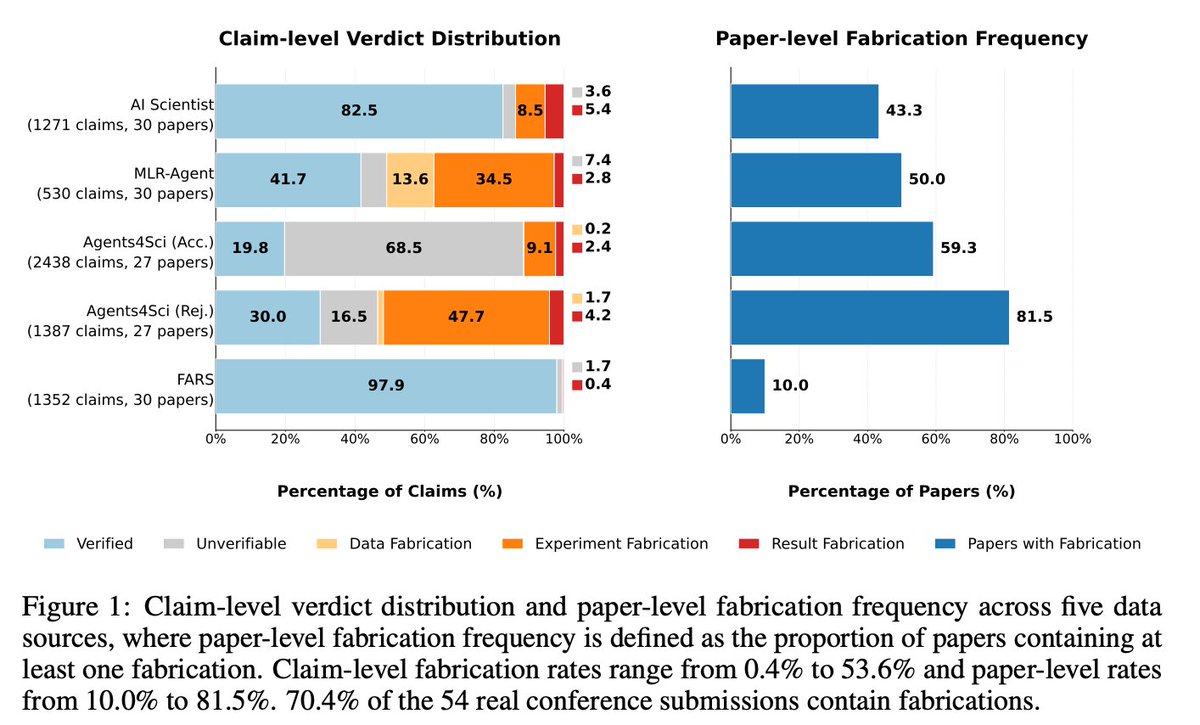
To what extent do AI-generated papers contain fabrications?
🚀Excited to introduce FabScore for fine-grained evaluation of fabrications in automated AI research. 🧵
We evaluate 144 AI-written papers from multiple sources, including @SakanaAILabs 's AI Scientist, MLR-Bench, @AnalemmaAI 's FARS and the 2025 #Agents4Science Open Conference.
Among 54 real conference submissions, we find that approximately 70% contain at least one fabrication; even among accepted papers, the rate remains as high as 59.3%.
📰 Paper: https://t.co/egFQ33fglo
💻 Code: https://t.co/BPpZm6YY24
1/
TL;DR — three contributions:
🔬 Theory — first analysis of why training P(h|b) is intractable (combinatorial complexity).
🛠 Training — first recipe that makes training P(h|b) tractable and scalable, with log-linear scaling laws.
⚡ Inference — continuous test-time scaling, breaking the brute-force complexity wall.
📄 Paper: https://t.co/VH36cDIaJs
💻 GitHub: https://t.co/H3ewP990nL
🤗 HF: https://t.co/BnLb7tbV1E
Joint work with @LidongBing at @miromind_ai 🍅
Happy to discuss in the comments — questions and critiques welcome.
#ICML2026 #AI4Science #LLM #AI4Research #Discovery
Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: https://t.co/VH36cDIIz0
💻 GitHub: https://t.co/H3ewP99ydj
🤗 HF: https://t.co/BnLb7tcsRc
🧵👇
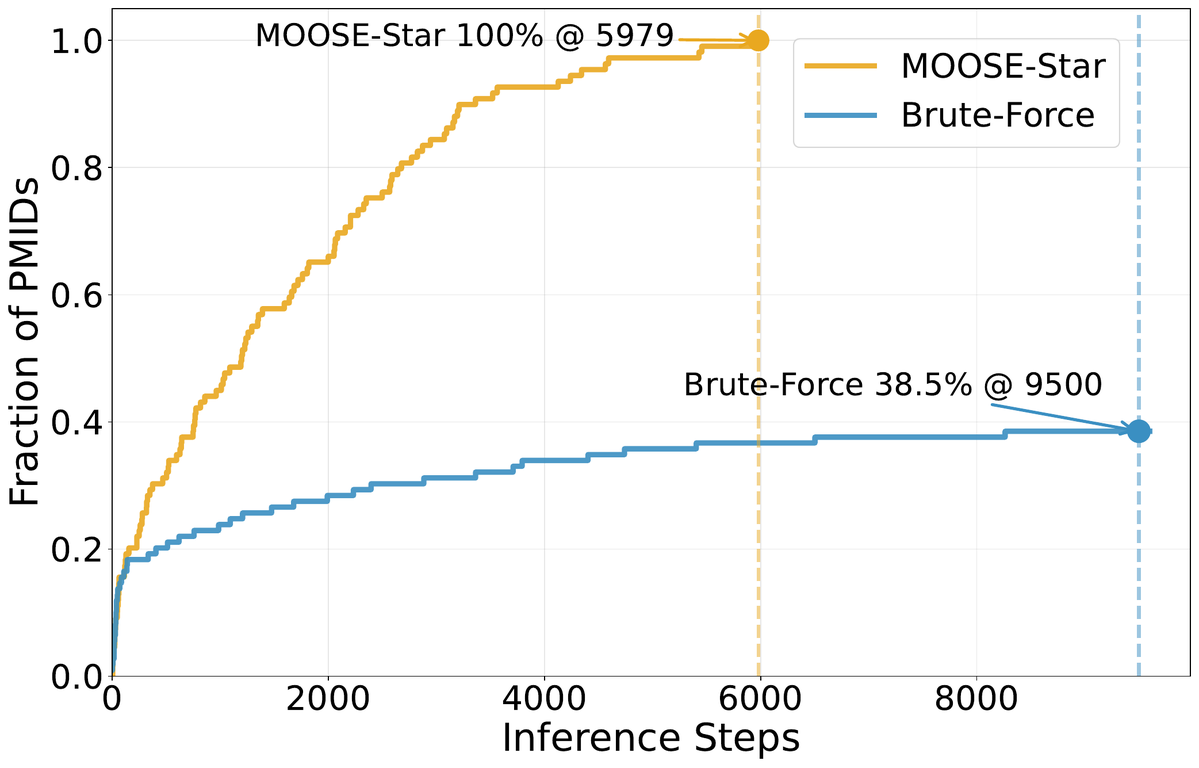
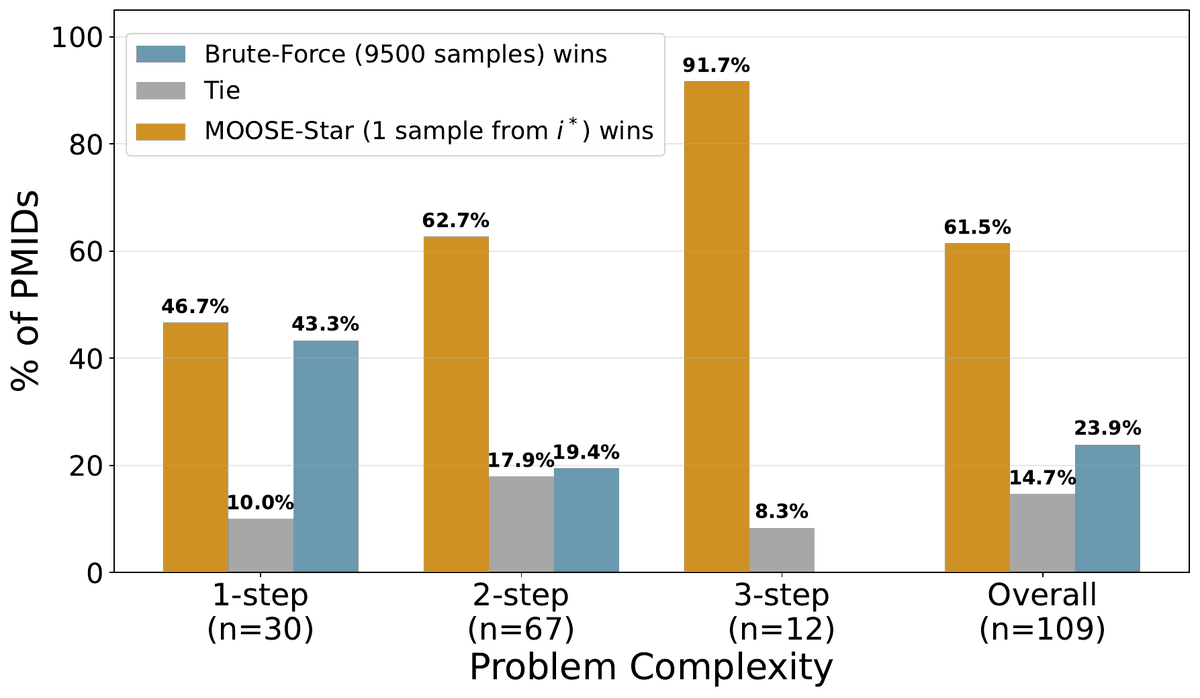
Test-time scales — and brute-force collapses 🏔️
The most striking result.
We pit brute-force sampling head-to-head against MOOSE-Star (MS): even with ~9,500 unguided samples per case, can brute-force match what MS produces with just 1–3 guided samples?
It hits a hard "complexity wall." Brute-force's win rate against MS collapses as required inspirations k grows:
43% → 19% → 0% for k = 1, 2, 3.
By k=3, brute-force never wins a single matchup — even at this massive sample budget. Overall, MS wins 61.5% of head-to-heads, with brute-force at just 23.9%.
Decomposition turns an intractable discovery problem into a tractable search problem.