To what extent do AI-generated papers contain fabrications?
🚀Excited to introduce FabScore for fine-grained evaluation of fabrications in automated AI research. 🧵
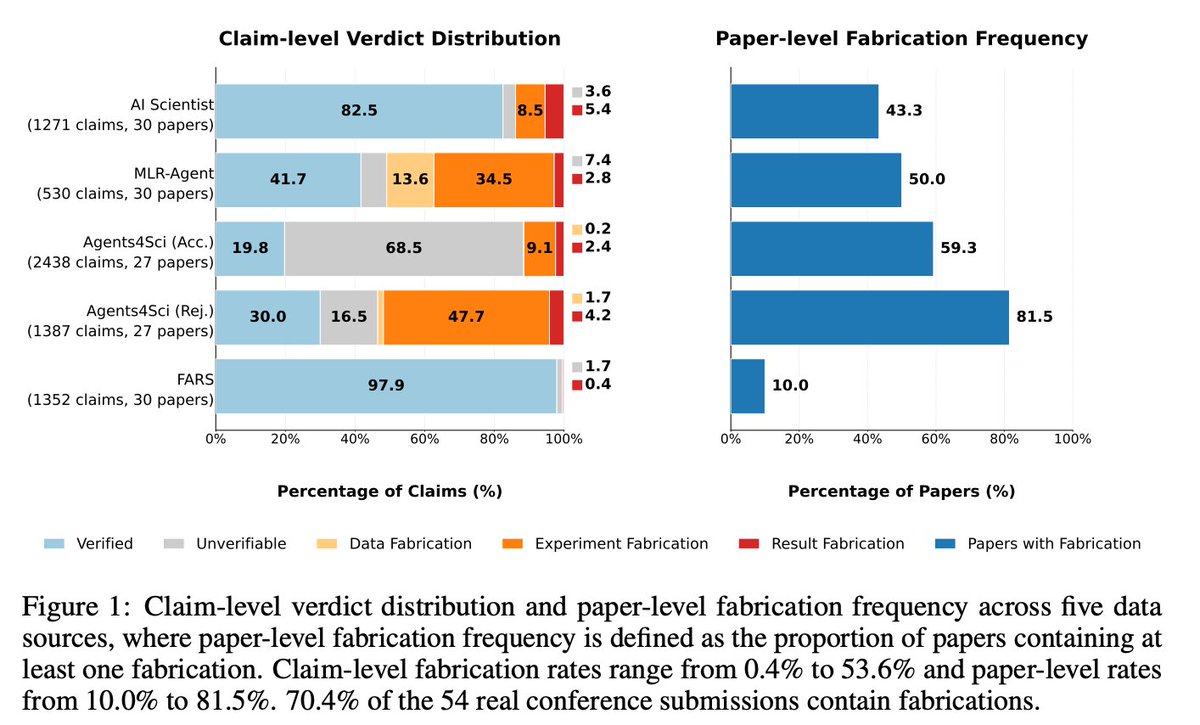
We evaluate 144 AI-written papers from multiple sources, including @SakanaAILabs 's AI Scientist, MLR-Bench, @AnalemmaAI 's FARS and the 2025 #Agents4Science Open Conference.
Among 54 real conference submissions, we find that approximately 70% contain at least one fabrication; even among accepted papers, the rate remains as high as 59.3%.
📰 Paper: https://t.co/egFQ33fglo
💻 Code: https://t.co/BPpZm6YY24
1/
🔍How should we scale test-time compute for agentic search?
We propose FineVerify: decompose questions into checkable sub-questions, verify each candidate with evidence, and select the best-supported answer.
Check our work at: https://t.co/eIt5UW6V7I
(1/N)
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD
Happy to introduce our latest work — VIMPO: Value-Implicit Policy Optimization for LLMs
Most RL methods for LLM training face a trade-off:
· PPO-style methods use a value model (critic) for token-level credit, but critics are hard to train.
· GRPO-style methods drop the critic, but give every token the same trajectory-level signal.
Can we get the best of both worlds? 🧵
Today, agents execute isolated tasks. Tomorrow, agents will steer complex decisions across long horizons.
Introducing CEO-Bench, a first step to measure "Steering Intelligence." In CEO-Bench, agents are asked to run a simulated startup for 500 days.
https://t.co/9gNWFALTKK
What happens when multi-agent systems stop relying on a central “controller” agent? Can agents coordinate by sharing results directly with each other?
Introducing Decentralized Language Models (DeLM): we let agents coordinate asynchronously through a shared context. Agents claim tasks from a queue and write back compact, verified results as they finish, making progress visible to all workers without requiring a main agent to merge, filter, and rebroadcast it.
New paper with @azaliamirh!
Excited to introduce 🌠Orion: Towards Lab Automation with Computer-Using Agents.
Give it control of your lab computer💻, and it can use software, analyze any experiment images, browse databases on Chrome exactly like you, and work for hours to analyze your experiments.
🌎:https://t.co/5EAe8vEetl
📎:https://t.co/D08hYrkJuG
[ICML'26 · arXiv:2606.06036] Your agent isn't forgetting — it just doesn't know how to recall.
Most memory-augmented agents retrieve.
Humans recall.
We propose MRAgent: a Cue–Tag–Content graph memory system where agents follow cues, update state, and decide to explore or answer.
My partner grew up playing the game Sword and Fairy 1 (仙劍一). Every model release cycle my vibe check is to have the model create a revamped version with a Star Trek mashup (my fav). Claude Fable is the first model to do a reasonable job!
Playthrough 4x speed👇
“Build an automated AI researcher—an AI system that can accelerate and increasingly automate the research process itself, while remaining steerable, accountable, and connected to people.”
Building AI that Builds AI: Introducing the Sakana AI RSI Lab 🚀
https://t.co/AskX3J5oEJ
Today, we are announcing the Sakana AI Recursive Self-Improvement (RSI) Lab: a dedicated research group in Tokyo tasked with redesigning the AI development process itself using AI.
While the industry increasingly speculates about the theoretical potential of self-improving AI, we’ve spent the last two years actively laying the foundations to make it a reality:
▪ LLM²: AI models automating research to invent better preference optimization algorithms.
▪ Darwin Gödel Machine: Agents autonomously rewriting their own codebase to double software-engineering performance.
▪ ShinkaEvolve: Hyper-sample-efficient program evolution that builds novel loss functions for MoE models.
▪ ALE-Agent: Reinforcement agents outperforming hundreds of human experts via self-learning.
▪ Digital Red Queen: Open-ended adversarial coevolution laying the groundwork for RSI in cybersecurity.
▪ The AI Scientist: Towards end-to-end automation of AI research, recently published in Nature.
Now, we are unifying these breakthroughs. The Sakana AI RSI Lab is officially tasked with building open-ended, adaptive architectures that collectively self-improve.
Human intelligence did not emerge from limitless resources; it was forged through the open-ended, compounding process of evolution operating under strict constraints. We are applying this exact principle to AI.
We believe recursive self-improvement is achievable on modest, sample-efficient compute. It shouldn’t be a winner-take-all asset locked inside hyperscale clusters, but a democratized public good.
We’re scaling our team to execute this mission. We are looking for frontier scientists and engineers who are entirely unsatisfied with the brute-force status quo. If you are ready to break away from standard benchmarking and build the self-improving future in Japan, come build with us.
so in the past few months, we've seen at least the following labs claiming to work on RSI:
- @AnthropicAI (https://t.co/lZVXWiUHSM)
- @OpenAI (https://t.co/oIPwcHeVKg)
- @Recursive_SI (https://t.co/kT0eQK3G7Z)
- Mirendil (https://t.co/yLDTaWgd3H)
- @inherent_labs (https://t.co/EMdGFkzYHQ)
- @SakanaAILabs (https://t.co/DToke5Udyj)
No matter who's gonna make it happen first, this is gonna be an important year for humanity. Looking forward!
We propose a new way to quantify AI overreliance: the Offloading Score 🧐 @vishakh_pk
It measures the fraction of cognitive work you hand off to AI 🤖 via simulating how you'd have done each step without AI, then counting the steps the AI saved. It works directly from interaction traces (keystrokes, screenshots), so it's reusable across many tools!!
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)
MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
https://t.co/aLW40sWz4d











![shuo_ji87616's tweet photo. [ICML'26 · arXiv:2606.06036] Your agent isn't forgetting — it just doesn't know how to recall.
Most memory-augmented agents retrieve.
Humans recall.
We propose MRAgent: a Cue–Tag–Content graph memory system where agents follow cues, update state, and decide to explore or answer. https://t.co/iH56NtmJ5h](https://pbs.twimg.com/media/HKSHj3la4AAowwp.jpg)
![shuo_ji87616's tweet photo. [ICML'26 · arXiv:2606.06036] Your agent isn't forgetting — it just doesn't know how to recall.
Most memory-augmented agents retrieve.
Humans recall.
We propose MRAgent: a Cue–Tag–Content graph memory system where agents follow cues, update state, and decide to explore or answer. https://t.co/iH56NtmJ5h](https://pbs.twimg.com/media/HKSHgVIaYAAda63.jpg)
![shuo_ji87616's tweet photo. [ICML'26 · arXiv:2606.06036] Your agent isn't forgetting — it just doesn't know how to recall.
Most memory-augmented agents retrieve.
Humans recall.
We propose MRAgent: a Cue–Tag–Content graph memory system where agents follow cues, update state, and decide to explore or answer. https://t.co/iH56NtmJ5h](https://pbs.twimg.com/media/HKSELtjbEAAclgJ.jpg)



















![shuo_ji87616's tweet photo. [ICML'26 · arXiv:2606.06036] Your agent isn't forgetting — it just doesn't know how to recall.
Most memory-augmented agents retrieve.
Humans recall.
We propose MRAgent: a Cue–Tag–Content graph memory system where agents follow cues, update state, and decide to explore or answer. https://t.co/iH56NtmJ5h](https://pbs.twimg.com/media/HKSHk97bQAALDph.jpg)
































